How to Run a Vert.x Cluster With Broadcasting Messaging
Learn how to work with multiples verticles in Vert.x clusters between multiple applications in a clustered environment.
Join the DZone community and get the full member experience.
Join For FreeWe reviewed how to work with multiple verticles and communication in the previous article. In this article, I will attempt to explain how you can do this between multiple applications in a clustered environment.
Things to Remember
We have an example from the previous article. For the clustered example, we'll split it into two independent application. To briefly remind you, we developed two verticles in the previous example. One of them the sender and the other the receiver. The sender receives a message via an endpoint then send it to the receiver. The receiver replies to the message. That's all.
At now, we'll split the example into two independent application as mentioned above. In other words, we will package these two verticles in separate jars to run separately multiple instances. Unlike the previous application, we use broadcasting messaging in this example by the eventBus
.publsih method because we will have a clustered environment and we want our messages to reach multiple receivers. You can access the code of this example under the sender and receiver directories from this repository. The sendMessage method of the Sender application as follows:
private void sendMessage(RoutingContext routingContext){
final EventBus eventBus = vertx.eventBus();
final String message = routingContext.request().getParam(PATH_PARAM);
eventBus.publish(ADDRESS, message);
log.info("Current Thread Id {} Is Clustered {} ", Thread.currentThread().getId(), vertx.isClustered());
routingContext.response().end(message);
}
}As you can see, the main difference from the previous example is the use of the publish method. When this method is used, the message will be delivered to all handlers registered to the address. In addition, we log the current thread id and whether Vert.x instance is clustered. Now let's look at the ClusteredReceiver class. The start method in the class as follows:
@Override
public void start(Future<Void> startFuture) throws Exception {
final EventBus eventBus = vertx.eventBus();
eventBus.consumer(ADDRESS, receivedMessage -> {
log.debug("Received message: {} ", receivedMessage.body());
});
log.info("Receiver ready!");
}As you can see, we don't reply the received message because we don't use point-to-point messaging. Everything else is the same as the previous example.
Cluster Manager
Now that we have split the verticles into two applications, we can start configuring the cluster environment. If a clustered environment is being targeted, the first step is to configure the cluster manager. In Vert.x, the cluster manager is Hazelcast by default. Hazelcast is an In-Memory Data Grid, it provides you to distribute your data among the nodes of a cluster. You can find more details about to Hazelcast in this link if you need. Hazelcast implementation is packaged inside Vert.x. To use in a Maven project, you will need to add the following dependency to pom.xml:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-hazelcast</artifactId>
<version>3.5.3</version>
</dependency>For a Gradle project:
dependencies {
compile 'io.vertx:vertx-hazelcast:3.5.2'
}When the Hazelcast is on your classpath then Vert.x will automatically detect this and use it as the cluster manager. Usually, the cluster manager is configured by an XML file which is packaged inside the jar. Therefore in the second step, we will override this configuration in accordance with our needs by a file called cluster.xml on our classpath.
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.8.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<properties>
<property name="hazelcast.mancenter.enabled">false</property>
<property name="hazelcast.memcache.enabled">false</property>
<property name="hazelcast.rest.enabled">false</property>
<property name="hazelcast.wait.seconds.before.join">0</property>
</properties>
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
<network>
<join>
<multicast enabled="false"/>
<tcp-ip enabled="true">
<interface>127.0.0.1</interface>
</tcp-ip>
</join>
<interfaces enabled="true">
<interface>127.0.0.1</interface>
</interfaces>
</network>
</hazelcast>You can also override the configuration by programmatically over the Hazelcast Config object.
Config hazelcastConfig = new Config();
// some configuration settings
ClusterManager mgr = new HazelcastClusterManager(hazelcastConfig);After these two steps, you have two options to run Vert.x in a clustered environment. One of these is the -cluster parameter which using on the command line.
java -jar jarPath/jarname -clusterNote that, when using -ha parameter on the command line you no need to add -cluster parameter. The -ha parameter is related to high availability and has not been mentioned because it is outside the scope of this article.
The other option is to use clustering programmatically wit the clusteredVertx method for verticle deploy.
public static void main(String[] args){
ClusterManager mgr = new HazelcastClusterManager();
VertxOptions options = new VertxOptions().setClusterManager(mgr);
Vertx.clusteredVertx(options, cluster -> {
if (cluster.succeeded()) {
cluster.result().deployVerticle(new ClusteredSender(), res -> {
if(res.succeeded()){
log.info("Deployment id is: " + res.result());
} else {
log.error("Deployment failed!");
}
});
} else {
log.error("Cluster up failed: " + cluster.cause());
}
});
}When Vert.x started with one of these ways, Hazelcast is started as an embedded element.
INFO: [127.0.0.1]:5701 [dev] [3.8.2]
Members [1] {
Member [127.0.0.1]:5701 - bebd26d2-6793-4e6b-b5b1-266e2fa33586 this
}
Aug 05, 2018 3:36:44 PM com.hazelcast.core.LifecycleService
INFO: [127.0.0.1]:5701 [dev] [3.8.2] [127.0.0.1]:5701 is STARTED
Aug 05, 2018 3:36:44 PM com.hazelcast.internal.partition.impl.PartitionStateManager
INFO: [127.0.0.1]:5701 [dev] [3.8.2] Initializing cluster partition table arrangement...At now, we will launch the sender application and then we will launch multiple the receiver application on the command line.
java -jar Sender/target/clusteredSenderLauncher.jar -clusterjava -jar Receiver/target/clusteredReceiverLauncher.jar -cluster
java -jar Receiver/target/clusteredReceiverLauncher.jar -clusterWhen the applications launched and we send our message to the endpoint we have, the message will be forwarded to all registered receivers.
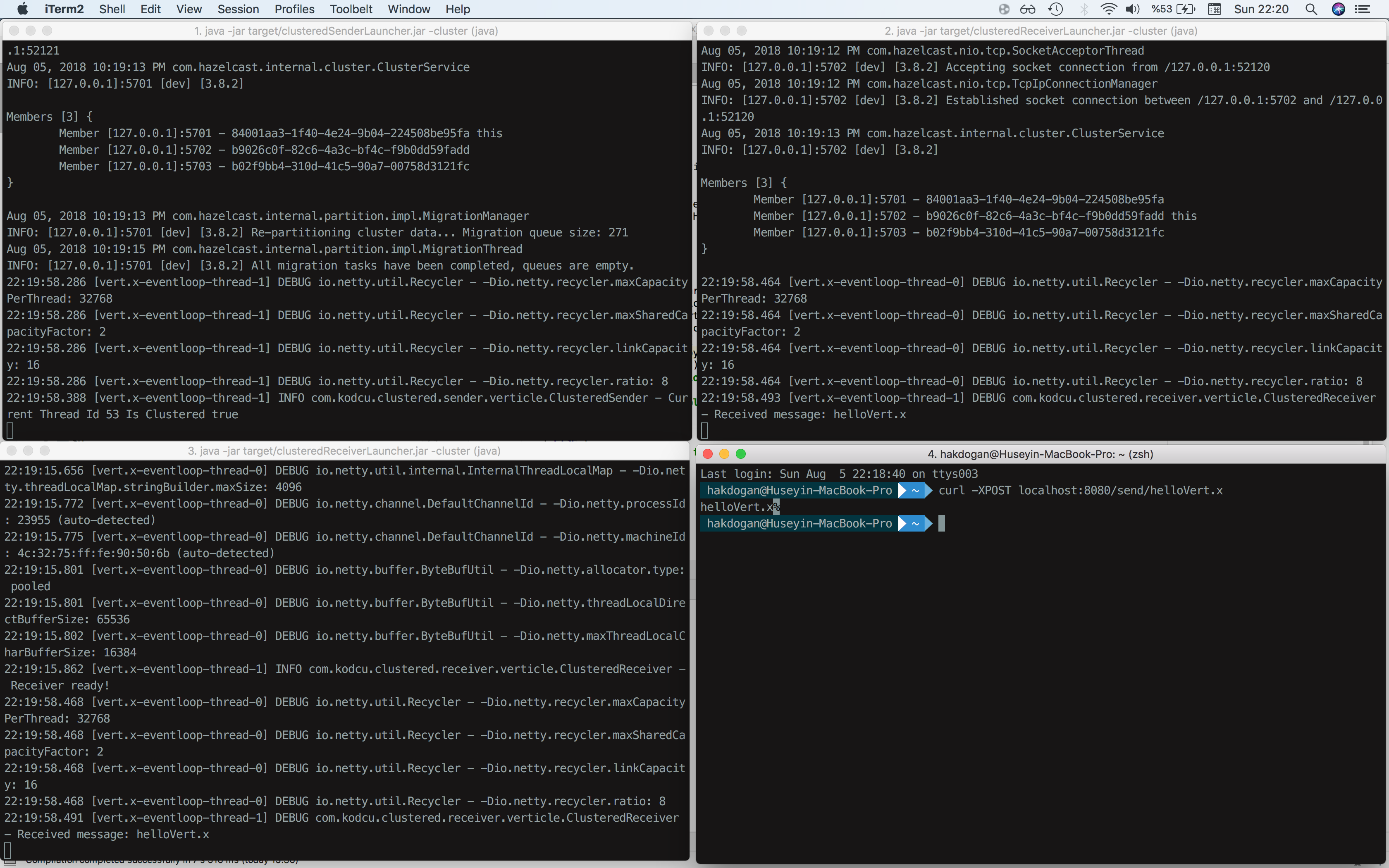
If you want to use multiple senders in our case, you should do this differently than the receiver launch style. That's because we created an HTTP server in the Sender which is bound to the 8080 port.
java -jar Sender/target/clusteredSenderLauncher.jar -cluster -instances 2When your start Vert.x instance this way, it internally maintains just a single server, and, as incoming connections arrive it distributes them in a round-robin fashion to any of the connect handlers. In this case, when you send two consecutive messages, you will see two different thread ID in the console.
22:50:13.954 [vert.x-eventloop-thread-2] INFO com.kodcu.clustered.sender.verticle.ClusteredSender - Current Thread Id 53 Is Clustered true
22:50:27.818 [vert.x-eventloop-thread-1] INFO com.kodcu.clustered.sender.verticle.ClusteredSender - Current Thread Id 54 Is Clustered trueConclusion
By default, Vert.x use Hazelcast as cluster manager and it provides you to distribute your data among the nodes of your cluster. That's an important point, Vert.x cluster managers are pluggable, so you can be replaced with another implementation as cluster manager if you want.
References
Opinions expressed by DZone contributors are their own.
Comments