How We Trained a Neural Network to Generate Shadows in a Photo: Part 3
In this article, we train a neural network to generate shadows in photos.
Join the DZone community and get the full member experience.
Join For FreeIn this series, Artem Nazarenko, Computer Vision Engineer at Everypixel, shows you how you can implement the architecture of a neural network. In the first part, we were talking about the working principles of GAN and methods of collecting datasets for training, the second part was about preparing for GAN training. Today, we are going to start training.
Training
We declare datasets and dataloaders for loading data and provide the device on which the network will be trained.
x
# The number of images that run through the neural network at one time
batch_size = 8
dataset_path = '/path/to/your/dataset'
train_path = osp.join(dataset_path, 'train')
test_path = osp.join(dataset_path, 'test')
# Declare datasets
train_dataset = ARDataset(train_path,\
augmentation=get_training_augmentation(),\
preprocessing=get_preprocessing(),)
valid_dataset = ARDataset(test_path, \
augmentation=get_validation_augmentation(),\
preprocessing=get_preprocessing(),)
# Declare dataloaders
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
Provide the device on which we will train the network:
xxxxxxxxxx
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
We train attention and shadow generation blocks separately.
Attention block training. We take U-Net as the attention block model and import the architecture from the segmentation_models.pytorch repository. To improve the quality of the network, replace the standard encoding part of the U-Net with the resnet34 classifier network.
Since the attention block accepts a shadow-free image and a mask of the inserted object at the input, we will replace the first convolutional layer in the model: a 4-channel tensor (3 color channels + 1 black-and-white) is sent to the module's input.
x
# Declare a U-Net model with two classes at the output — two masks (neighboring objects and their shadows)
model = smp.Unet(encoder_name='resnet34', classes=2, activation='sigmoid',)
# Replace the first convolutional layer in the model — there should be four channels at the input
model.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7, 7), stride=(2, 2), \
padding=(3, 3), bias=False)
Declare the loss function, metric and optimizer.
xxxxxxxxxx
loss = smp.utils.losses.DiceLoss()
metric = smp.utils.metrics.IoU(threshold=0.5)
optimizer = torch.optim.Adam([dict(params=model.parameters(), lr=1e-4),])
Create a function to train the attention block. The training is standard. It consists of three cycles: a cycle by epochs, a training cycle by batches, and a validation cycle by batches.
At each iteration of the dataloader, a direct run of the data through the model and obtaining predictions are performed. Then, the loss functions and metrics are calculated, after which a reverse pass of the learning algorithm (backpropagation of the error) is done, and the weights are updated.
x
def train(n_epoch, train_loader, valid_loader, model_path, model, loss,\
metric, optimizer, device):
""" Network learning function.
n_epoch — number of epochs
train_loader — dataloader for training samples
valid_loader — dataloader for validation samples
model_path — path to save the model
model — pre-announced model
loss — loss function
metric — metric
optimizer — optimizer
device — specific torch.device
"""
model.to(device)
max_score = 0
total_train_steps = len(train_loader)
total_valid_steps = len(valid_loader)
# Start the training cycle
print('Start training!')
for epoch in range(n_epoch):
# Put the model into training mode
model.train()
train_loss = 0.0
train_metric = 0.0
# Batch training cycle
for data in train_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# Run through the model
model_input = torch.cat((noshadow_image, mask), axis=1)
model_output = model(model_input)
# Compare the model output with ground truth data
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
train_metric += metric(ground_truth, model_output).item()
optimizer.zero_grad()
loss_result.backward()
optimizer.step()
train_loss += loss_result.item()
# Put the model in eval mode
model.eval()
valid_loss = 0.0
valid_metric = 0.0
# Batch validation cycle
for data in valid_loader:
noshadow_image = data[0][:, :3].to(device)
robject_mask = torch.unsqueeze(data[1][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[1][:, 1], 1).to(device)
mask = torch.unsqueeze(data[1][:, 2], 1).to(device)
# Run through the model
model_input = torch.cat((noshadow_image, mask), axis=1)
with torch.no_grad():
model_output = model(model_input)
# Compare the model output with ground truth data
ground_truth = torch.cat((robject_mask, rshadow_mask), axis=1)
loss_result = loss(ground_truth, model_output)
valid_metric += metric(ground_truth, model_output).item()
valid_loss += loss_result.item()
train_loss = train_loss / total_train_steps
train_metric = train_metric / total_train_steps
valid_loss = valid_loss / total_valid_steps
valid_metric = valid_metric / total_valid_steps
print(f'\nEpoch {epoch}, train_loss: {train_loss}, train_metric: {train_metric}, valid_loss: {valid_loss}, valid_metric: {valid_metric}')
# If you got a new maximum in accuracy, save the model
if max_score < valid_metric:
max_score = valid_metric
torch.save(model.state_dict(), model_path)
print('Model saved!')
# Call the function:
# Number of epochs
n_epoch = 10
# Path to save the model
model_path = '/path/for/model/saving'
train(n_epoch=n_epoch,
train_loader=train_loader,
valid_loader=valid_loader,
model_path=model_path,
model=model,
loss=loss,
metric=metric,
optimizer=optimizer,
device=device)
After the training of the attention block is completed, proceed to the main part of the network.
Shadow generation block training. As a model of the shadow generation block, we will similarly take U-Net and a lighter network – resnet18 as an encoder.
Since at the input shadow generation block accepts a shadow-free image and 3 masks (the mask of the inserted object, the mask of neighboring objects and the mask of their shadows), we will replace the first convolutional layer in the model: the module receives a 6-channel tensor (3 color channels + 3 black-white ones) at the input.
Behind the U-Net, we add 4 refinement blocks at the end. One block consists of a sequence: BatchNorm2d, ReLU and Conv2d.
Declare a generator class.
xxxxxxxxxx
class Generator_with_Refin(nn.Module):
def __init__(self, encoder):
""" Generator initialization."""
super(Generator_with_Refin, self).__init__()
self.generator = smp.Unet(
encoder_name=encoder,
classes=1,
activation='identity',
)
self.generator.encoder.conv1 = nn.Conv2d(6, 64, kernel_size=(7, 7), \
stride=(2, 2), padding=(3, 3), \
bias=False)
self.generator.segmentation_head = nn.Identity()
self.SG_head = nn.Conv2d(in_channels=16, out_channels=3, \
kernel_size=3, stride=1, padding=1)
self.refinement = torch.nn.Sequential()
for i in range(4):
self.refinement.add_module(f'refinement{3*i+1}', nn.BatchNorm2d(16))
self.refinement.add_module(f'refinement{3*i+2}', nn.ReLU())
refinement3 = nn.Conv2d(in_channels=16, out_channels=16, \
kernel_size=3, stride=1, padding=1)
self.refinement.add_module(f'refinement{3*i+3}', refinement3)
self.output1 = nn.Conv2d(in_channels=16, out_channels=3, kernel_size=3, \
stride=1, padding=1)
def forward(self, x):
""" Direct pass of data through the network."""
x = self.generator(x)
out1 = self.SG_head(x)
x = self.refinement(x)
x = self.output1(x)
return out1, x
Declare a discriminator class.
xxxxxxxxxx
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, \
stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, \
stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, \
first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, \
padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
Declare generator and discriminator model objects, as well as loss functions and optimizers for the generator and discriminator.
xxxxxxxxxx
generator = Generator_with_Refin('resnet18')
discriminator = Discriminator(input_shape=(3,256,256))
l2loss = nn.MSELoss()
perloss = ContentLoss(feature_extractor="vgg16", layers=("relu3_3", ))
GANloss = nn.MSELoss()
optimizer_G = torch.optim.Adam([dict(params=generator.parameters(), lr=1e-4),])
optimizer_D = torch.optim.Adam([dict(params=discriminator.parameters(), lr=1e-6),])
Everything is ready for training. Provide a function for training the SG block. Calling it will be similar to calling the attention learning function.
x
def train(generator, discriminator, device, n_epoch, optimizer_G, optimizer_D, train_loader, valid_loader, scheduler, losses, models_paths, bettas, writer):
"""Function for training the SG block
generator — generator model
discriminator — discriminator model
device — torch-device for training
n_epoch — number of epochs
optimizer_G — optimizer for the generator model
optimizer_D — optimizer for the discriminator model
train_loader — dataloader for training samples
valid_loader — dataloader for validation samples
scheduler — scheduler to change the learning rate
losses — list of loss functions
models_paths — list of paths for saving models
bettas — list of coefficients for loss function
writer — tensorboard writer
"""
# Transferring the models to the GPU
generator.to(device)
discriminator.to(device)
# For the validation minimum
val_common_min = np.inf
print('Start training!')
for epoch in range(n_epoch):
# Put the models into training mode
generator.train()
discriminator.train()
# Lists for Loss Function Values
train_l2_loss = []; train_per_loss = []; train_common_loss = [];
train_D_loss = []; valid_l2_loss = []; valid_per_loss = [];
valid_common_loss = [];
print('Cycle by batches:')
for batch_i, data in enumerate(tqdm(train_loader)):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# Prepare the input tensor for the model
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
# ------------ Train the generator ----------------------------------
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# Adversarial ground truths
valid = Variable(torch.cuda.FloatTensor(np.ones((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(torch.cuda.FloatTensor(np.zeros((data[2].size(0), *discriminator.output_shape))), requires_grad=False)
# Calculate loss functions
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_shadow_image_tensor, for_per_result_nn_tensor2)
gan_loss = losses[2](discriminator(result_nn_tensor2), valid)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss + bettas[2] * gan_loss
optimizer_G.zero_grad()
common_loss.backward()
optimizer_G.step()
# ------------ Train the discriminator ------------------------------
optimizer_D.zero_grad()
loss_real = losses[2](discriminator(shadow_image), valid)
loss_fake = losses[2](discriminator(result_nn_tensor2.detach()), fake)
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# ------------------------------------------------------------------
train_l2_loss.append((bettas[0] * l2_loss).item())
train_per_loss.append((bettas[1] * per_loss).item())
train_D_loss.append((bettas[2] * loss_D).item())
train_common_loss.append(common_loss.item())
# Put the generator into eval mode
generator.eval()
# Validation
for batch_i, data in enumerate(valid_loader):
noshadow_image = data[2][:, :3].to(device)
shadow_image = data[2][:, 3:].to(device)
robject_mask = torch.unsqueeze(data[3][:, 0], 1).to(device)
rshadow_mask = torch.unsqueeze(data[3][:, 1], 1).to(device)
mask = torch.unsqueeze(data[3][:, 2], 1).to(device)
# Prepare the input for the model
model_input = torch.cat((noshadow_image, mask, robject_mask, rshadow_mask), axis=1)
with torch.no_grad():
shadow_mask_tensor1, shadow_mask_tensor2 = generator(model_input)
result_nn_tensor1 = torch.add(noshadow_image, shadow_mask_tensor1)
result_nn_tensor2 = torch.add(noshadow_image, shadow_mask_tensor2)
for_per_result_shadow_image_tensor = torch.sigmoid(shadow_image)
for_per_result_nn_tensor1 = torch.sigmoid(result_nn_tensor1)
for_per_result_nn_tensor2 = torch.sigmoid(result_nn_tensor2)
# Calculate loss functions
l2_loss = losses[0](shadow_image, result_nn_tensor1) + losses[0](shadow_image, result_nn_tensor2)
per_loss = losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor1) + losses[1](for_per_result_shadow_image_tensor, for_per_result_nn_tensor2)
common_loss = bettas[0] * l2_loss + bettas[1] * per_loss
valid_per_loss.append((bettas[1] * per_loss).item())
valid_l2_loss.append((bettas[0] * l2_loss).item())
valid_common_loss.append(common_loss.item())
# Average the values of the loss functions
tr_l2_loss = np.mean(train_l2_loss)
val_l2_loss = np.mean(valid_l2_loss)
tr_per_loss = np.mean(train_per_loss)
val_per_loss = np.mean(valid_per_loss)
tr_common_loss = np.mean(train_common_loss)
val_common_loss = np.mean(valid_common_loss)
tr_D_loss = np.mean(train_D_loss)
# Add results to tensorboard
writer.add_scalar('tr_l2_loss', tr_l2_loss, epoch)
writer.add_scalar('val_l2_loss', val_l2_loss, epoch)
writer.add_scalar('tr_per_loss', tr_per_loss, epoch)
writer.add_scalar('val_per_loss', val_per_loss, epoch)
writer.add_scalar('tr_common_loss', tr_common_loss, epoch)
writer.add_scalar('val_common_loss', val_common_loss, epoch)
writer.add_scalar('tr_D_loss', tr_D_loss, epoch)
# Print information
print(f'\nEpoch {epoch}, tr_common loss: {tr_common_loss:.4f}, val_common loss: {val_common_loss:.4f}, D_loss {tr_D_loss:.4f}')
if val_common_loss <= val_common_min:
# Save the best model
torch.save(generator.state_dict(), models_paths[0])
torch.save(discriminator.state_dict(), models_paths[1])
val_common_min = val_common_loss
print(f'Model saved!')
# Make a Scheduler Step
scheduler.step(val_common_loss)
Training Process
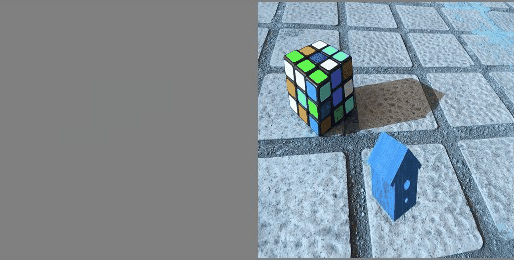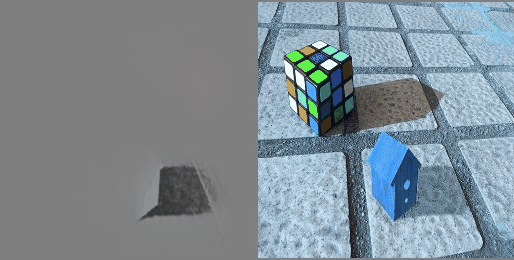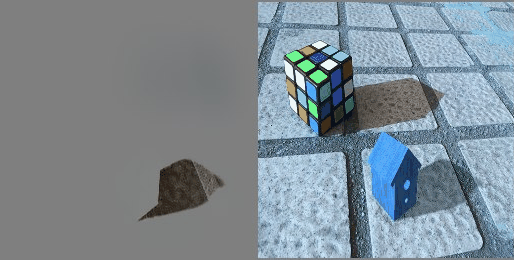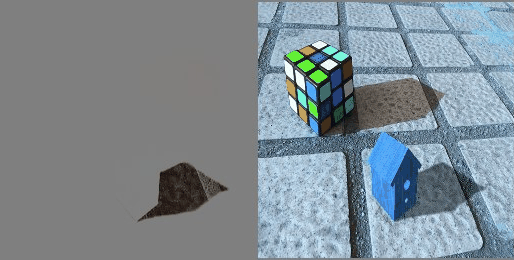
Visualization of the learning process
Graphs, general information. For training, I used a GTX 1080Ti graphics card on the Hostkey server. In the process, I tracked the change in the loss functions for the plotted graphs using the tensorboard utility. Below, the figures show training graphs based on the training and validation samples.

Training Graphs — Training Samples
The second figure is especially useful because the validation samples are not used in the generator training process. They are independent. The training graphs show that it reached the plateau at approx. the 200-250th epoch. Here it was already possible to slow down the training of the generator since the loss function was not monotonic.
However, it is useful to look at the training graphs on a logarithmic scale as it shows the monotony of the graph more clearly. According to the graph of the logarithm of the validation loss function, we can see that it was too early to stop learning at approx. the 200-250th epoch. It could have been done later, at the 400th epoch.

For clarity of the experiment, the predicted picture was periodically saved (see the gif of the visualization of the learning process above).
Some difficulties. During the training process, we had to solve a simple problem — incorrect weighting of the loss functions.
Since our final loss function consists of the weighted sum of the other loss functions, the contribution of each of them to the total must be adjusted separately by setting the coefficients for them. The best option is to take the coefficients suggested in the original article.
If the balancing of the loss functions is wrong, we can get unsatisfactory results. For example, if too strong a contribution is set for L2, and then the training of the neural network can even come to a standstill. L2 converges quickly enough, but at the same time, it is undesirable to completely remove it from the total amount - the output shadow will be less realistic, less consistent in color and transparency.

The picture shows the ground truth image on the left and the generated image on the right.
Inference. For prediction and testing, we will combine the attention and SG models into one ARShadowGAN class.
xxxxxxxxxx
class ARShadowGAN(nn.Module):
def __init__(self, model_path_attention, model_path_SG, encoder_att='resnet34', \
encoder_SG='resnet18', device='cuda:0'):
super(ARShadowGAN, self).__init__()
self.device = torch.device(device)
self.model_att = smp.Unet(
classes=2,
encoder_name=encoder_att,
activation='sigmoid'
)
self.model_att.encoder.conv1 = nn.Conv2d(4, 64, kernel_size=(7,7), stride=(2,2), padding=(3,3), bias=False)
self.model_att.load_state_dict(torch.load(model_path_attention))
self.model_att.to(device)
self.model_SG = Generator_with_Refin(encoder_SG)
self.model_SG.load_state_dict(torch.load(model_path_SG))
self.model_SG.to(device)
def forward(self, tensor_att, tensor_SG):
self.model_att.eval()
with torch.no_grad():
robject_rshadow_tensor = self.model_att(tensor_att)
robject_rshadow_np = robject_rshadow_tensor.cpu().numpy()
robject_rshadow_np[robject_rshadow_np >= 0.5] = 1
robject_rshadow_np[robject_rshadow_np < 0.5] = 0
robject_rshadow_np = 2 * (robject_rshadow_np - 0.5)
robject_rshadow_tensor = torch.cuda.FloatTensor(robject_rshadow_np)
tensor_SG = torch.cat((tensor_SG, robject_rshadow_tensor), axis=1)
self.model_SG.eval()
with torch.no_grad():
output_mask1, output_mask2 = self.model_SG(tensor_SG)
result = torch.add(tensor_SG[:,:3, ...], output_mask2)
return result, output_mask2
The inference code is below.
x
# Specify the paths to data and checkpoints
dataset_path = '/content/arshadowgan/uploaded'
result_path = '/content/arshadowgan/uploaded/shadow'
path_att = '/content/drive/MyDrive/ARShadowGAN-like/attention.pth'
path_SG = '/content/drive/MyDrive/ARShadowGAN-like/SG_generator.pth'
# Declare dataset and dataloader
dataset = ARDataset(dataset_path, augmentation=get_validation_augmentation(256), preprocessing=get_preprocessing(), is_train=False)
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
# Provide the device
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Declare the complete model
model = ARShadowGAN(
encoder_att='resnet34',
encoder_SG='resnet18',
model_path_attention=path_att,
model_path_SG=path_SG,
device=device
)
# Put it into testing mode
model.eval()
# Prediction
for i, data in enumerate(dataloader):
tensor_att = torch.cat((data[0][:, :3], torch.unsqueeze(data[1][:, -1], axis=1)), axis=1).to(device)
tensor_SG = torch.cat((data[2][:, :3], torch.unsqueeze(data[3][:, -1], axis=1)), axis=1).to(device)
with torch.no_grad():
result, shadow_mask = model(tensor_att, tensor_SG)
shadow_mask = np.uint8(127.5*shadow_mask[0].cpu().numpy().transpose((1,2,0)) + 1.0)
output_image = np.uint8(127.5 * (result.cpu().numpy()[0].transpose(1,2,0) + 1.0))
cv2.imwrite(osp.join(result_path, 'test.png'), output_image)
print('result saved: ' + result_path + '/test.png')
Conclusion
This article discusses a generative adversarial network by the example of solving one of the ambitious and difficult tasks at the junction of Augmented Reality and Computer Vision. In general, the resulting model can generate shadows, although not always perfect.
Note that GAN is not the only way to generate shadows. There are other approaches that, for example, use 3D object reconstruction techniques, differentiated rendering, etc.
The whole above code is in the repository. The examples of launching are in Google Colab Notebook.

P.S. I would be happy to answer any questions you may have and to receive your feedback. Thank you for your attention!
Opinions expressed by DZone contributors are their own.
Comments