Improve Performance and Data Availability With Elastic Block Store (EBS)
With a careful selection of Elastic Block Store (EBS) types and clever optimizations, deploying DBaaS on EBS can achieve even better performance.
Join the DZone community and get the full member experience.
Join For FreeNowadays, many Database-as-a-Service (DBaaS) solutions separate the computation layer and the storage layer. These include, for example, Amazon Aurora and Google BigQuery. This solution is attractive, as the data storage and data replication can be handled by existing services. DBaaS takes off the need to worry about this complexity; however, the performance of this design sometimes may not be as good as the traditional ways—using a local disk as storage.
In this article, we show that with a careful selection of Elastic Block Store (EBS) types and clever optimizations, deploying DBaaS on EBS can achieve even better performance than on local disks.
Why Do We Consider EBS in the First Place?
To explain our motivation for using EBS, we’d like to briefly introduce TiDB. TiDB is a MySQL-compatible, distributed database. TiDB Servers are the computation nodes which process SQL requests. The Placement Driver (PD) is the brain for TiDB, which configures load balancing and provides metadata services. TiKV is a row-oriented key-value store that processes transactional queries. TiFlash is a columnar storage extension that handles analytical queries. Going forward, we will take a deep dive into TiKV.
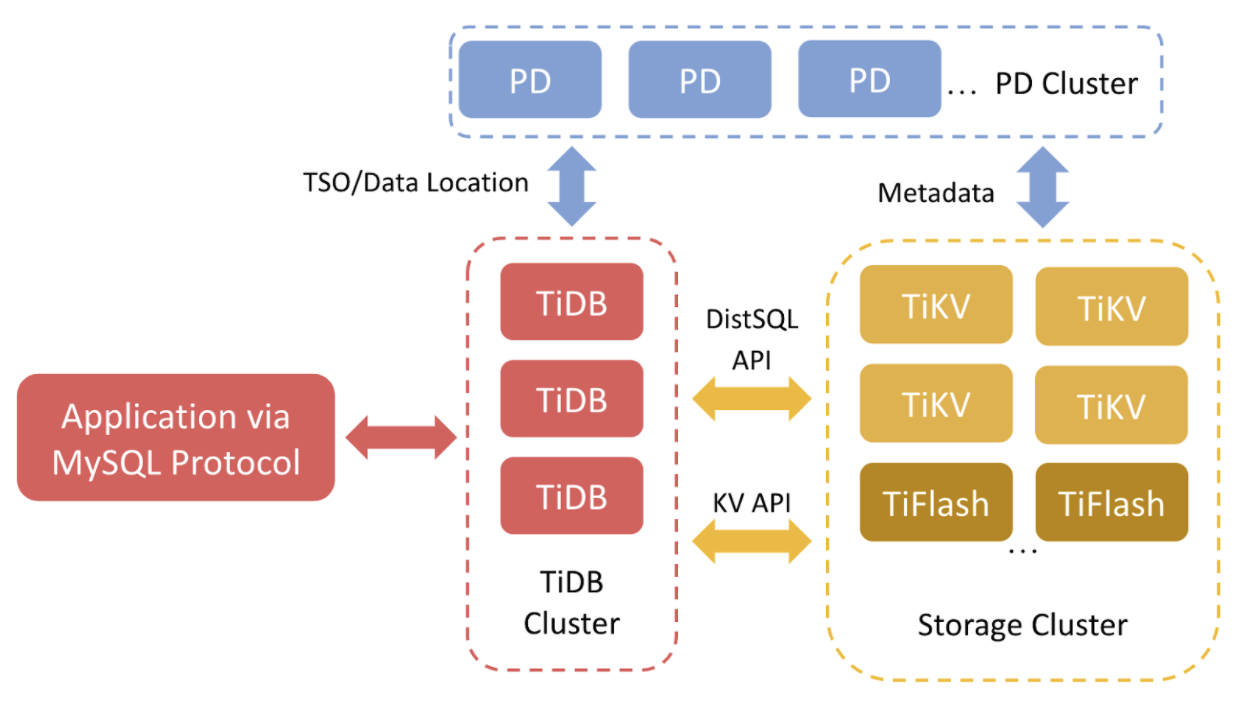
TiKV provides distributed key-value service. First, it splits the data into several Regions, the smallest data unit for replication and load balancing. To achieve High Availability (HA), each Region is replicated three times and then distributed among different TiKV nodes. The replicas for one Region form a Raft group. Losing one node and thus losing one replica in some Regions is acceptable for TiDB. However, losing two replicas simultaneously causes problems because the majority of members of a Raft group are lost. This makes a Region unavailable; its data can no longer be accessed. Human intervention is needed to address such issues.
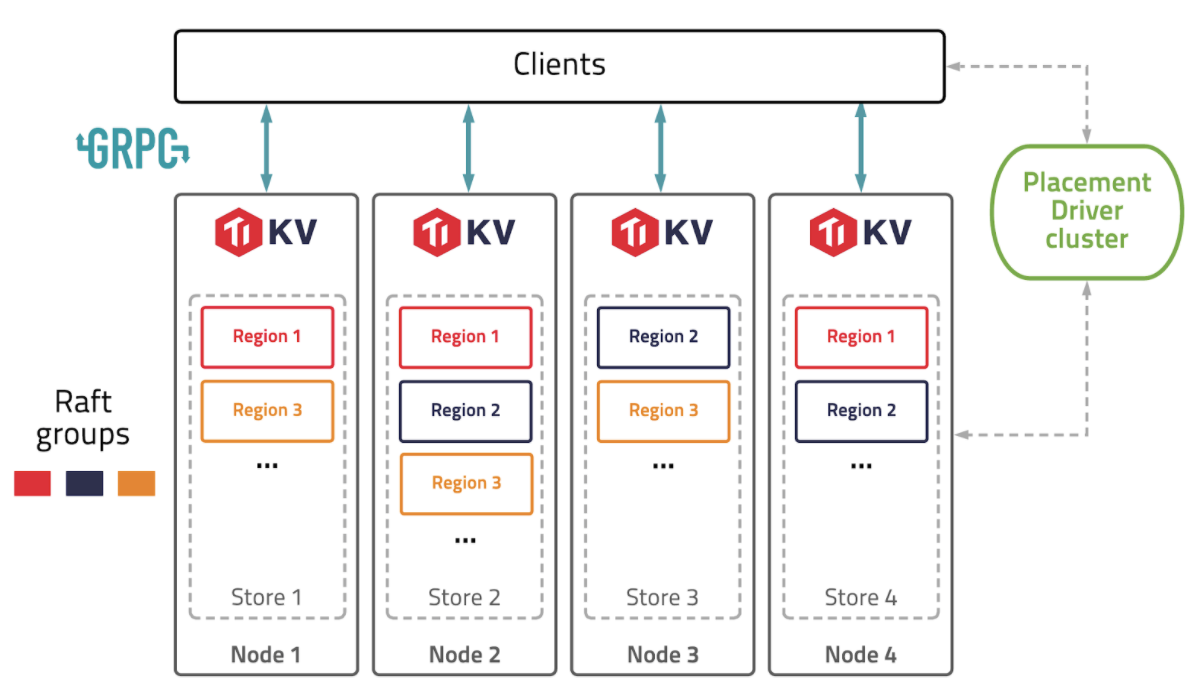
When deploying TiDB Cloud, we have placement rules which guarantee that the replica of a Region will be spread across multiple Availability Zones (AZ). Losing one Availability Zone (AZ) will not have a huge impact on TiDB Cloud. However, with AZ + 1 failure (one Availability Zone and at least one node failure in another Availability Zone), the Region becomes unavailable. We had such a failure in production, and it took a lot of work to bring the TiDB cluster online. To avoid such painful experiences again, EBS comes into our sight.
AWS Elastic Block Store (EBS) is a Block Store service provided by AWS, which can be attached to EC2 instances. The data on EBS, however, are independent of the EC2 instance, so when an EC2 instance fails, the data persists. When an EC2 instance fails, the EBS can be automatically remounted to a working EC2 instance by using Kubernetes. Moreover, EBS volumes are designed for mission-critical systems, so they are replicated within an AZ. This means that EBS is less likely to fail, which gives us extra peace of mind.
Selecting a Suitable EBS Volume Type
In general, there are four SSD-based EBS volume types: gp2, gp3, io1, and io2. (When we designed and implemented TiDB Cloud, io2 Block Express was still in preview mode, so we didn’t consider it.) The following table summarizes the characteristics of these volume types.
Volume type |
Durability (%) | Bandwidth (MB/s) | IOPS (per GB) | cost | comments |
|---|---|---|---|---|---|
gp2 |
99.8-99.9 |
250 |
3, burstable |
Low |
A general purpose volume |
gp3 |
99.8-99.9 |
125-1,000 |
3,000- 16,000 |
Low |
A general purpose volume with flexible bandwidth |
io1 |
99.8-99.9 |
Up to 1,000 |
Up to 64,000 |
High |
High IOPS |
io2 |
99.999 |
Up to 1,000 |
up to 64,000 |
High |
High IOPS; the best performance of the group |
Now, let’s get our hands dirty and do some performance comparison. Note that in the following figures, the four EBS volume types are attached to the r5b instance, while the measurements on the local disk are conducted on the i3 instance. This is because that r5b instance can only use EBS. We use i3 as a close alternative. Each figure shows the average and 99th percentile latency for all operations.
We’ll start with benchmarking the read and write latency. The first workload is a simple one. It has 1,000 IOPS, and each I/O is 4 KB. The following two figures show the average and 99-percentile latency.
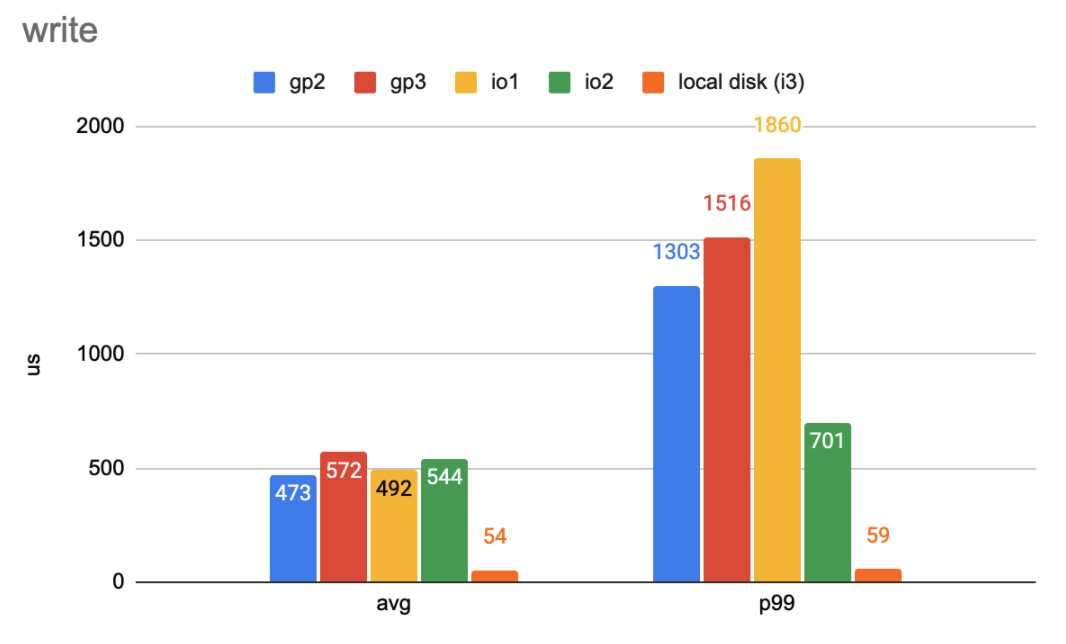
Write latency in a simple workload with one thread. (Lower numbers are better)
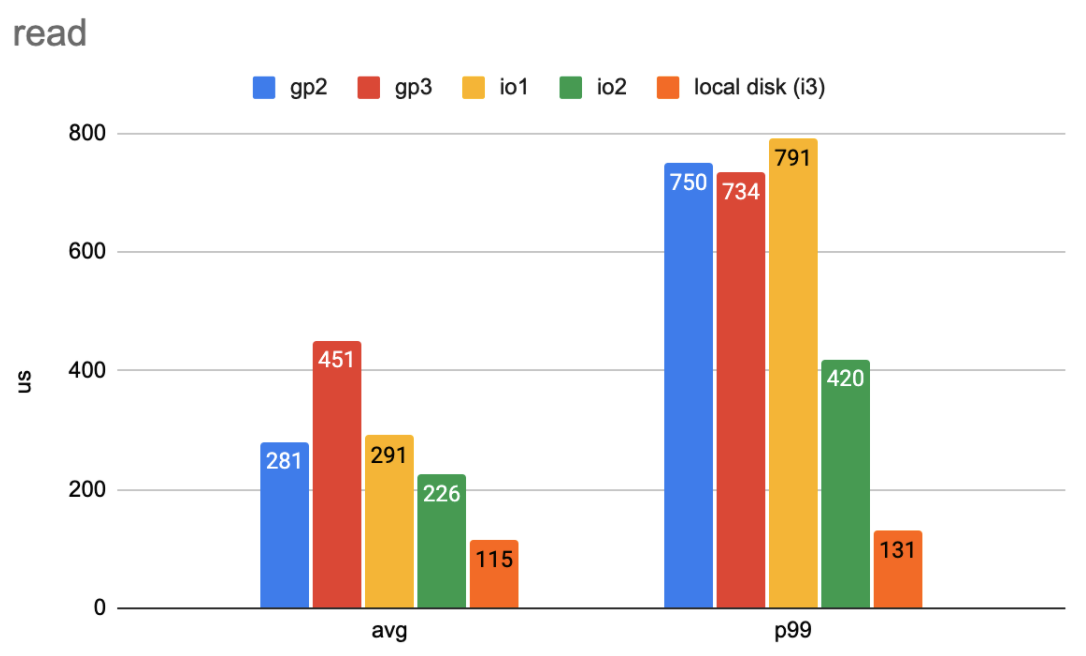
Read latency in a simple workload with one thread. (Lower numbers are better)
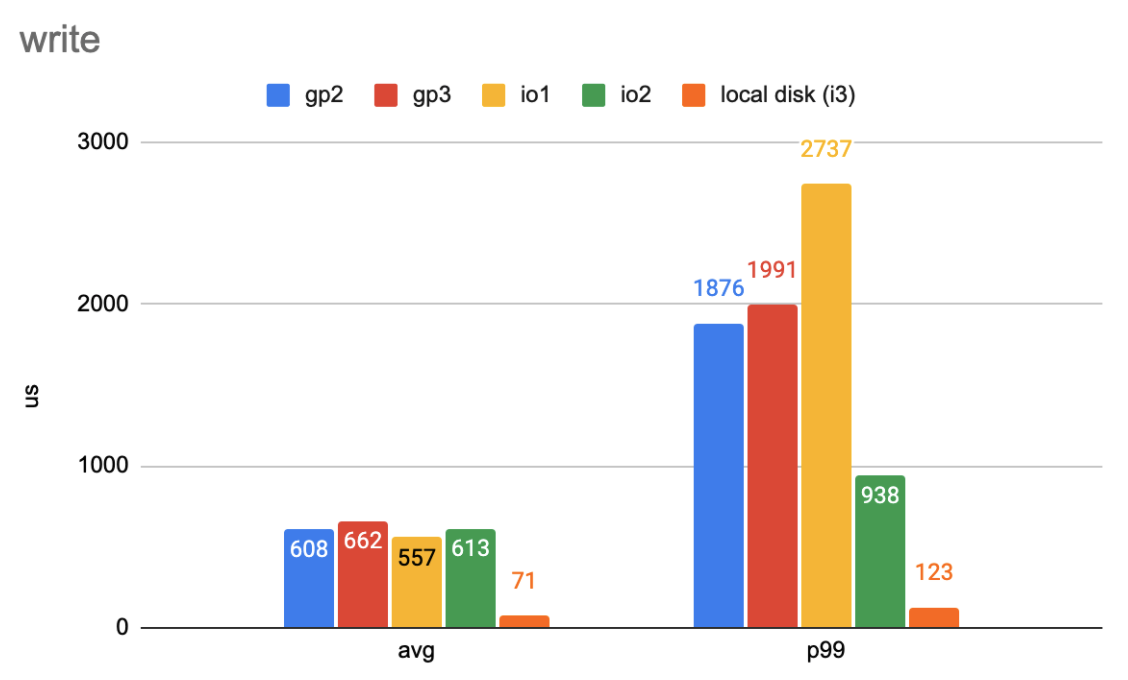
Write latency in a simple workload with eight threads. (Lower numbers are better)
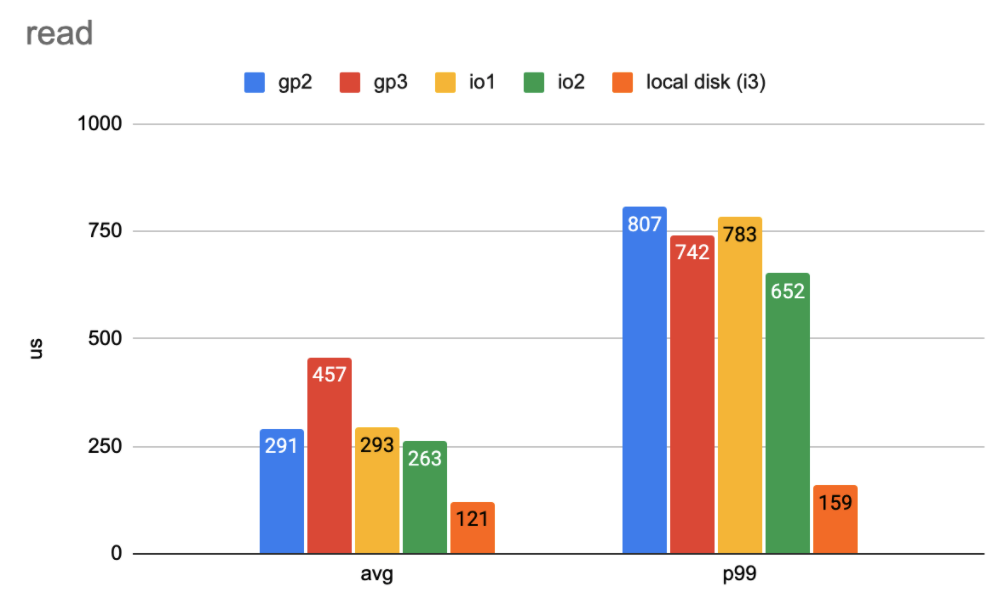
Read latency in a simple workload with eight threads. (Lower numbers are better)
We found that when the background I/O becomes more intense, foreground latency grows, and the latency gap between the local disk and the EBS becomes smaller. See the following figure.
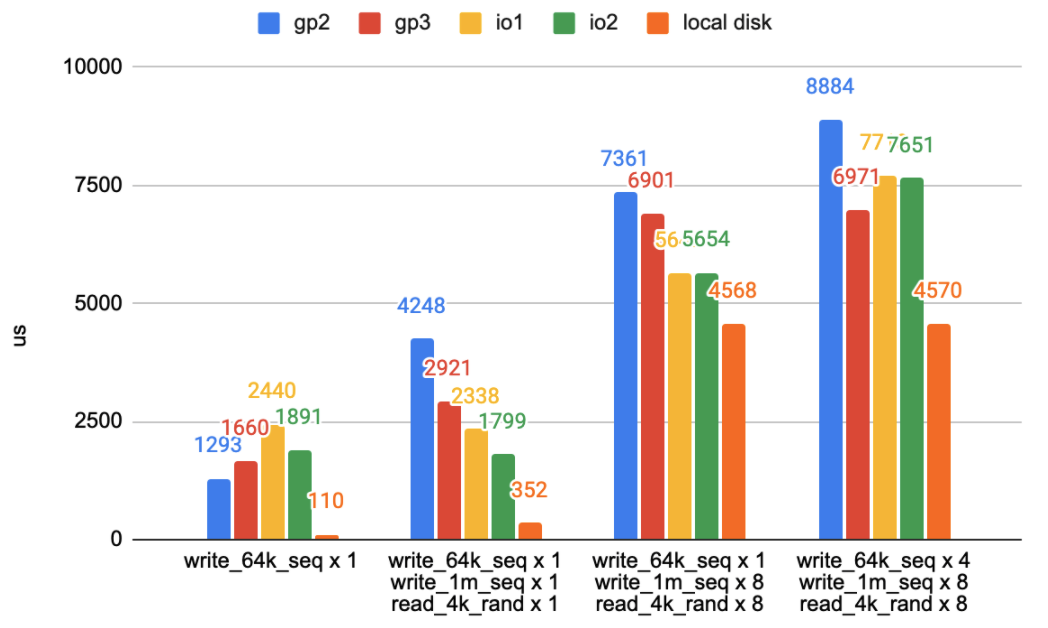
Average operation latency in some comprehensive workloads. (Lower numbers are better)
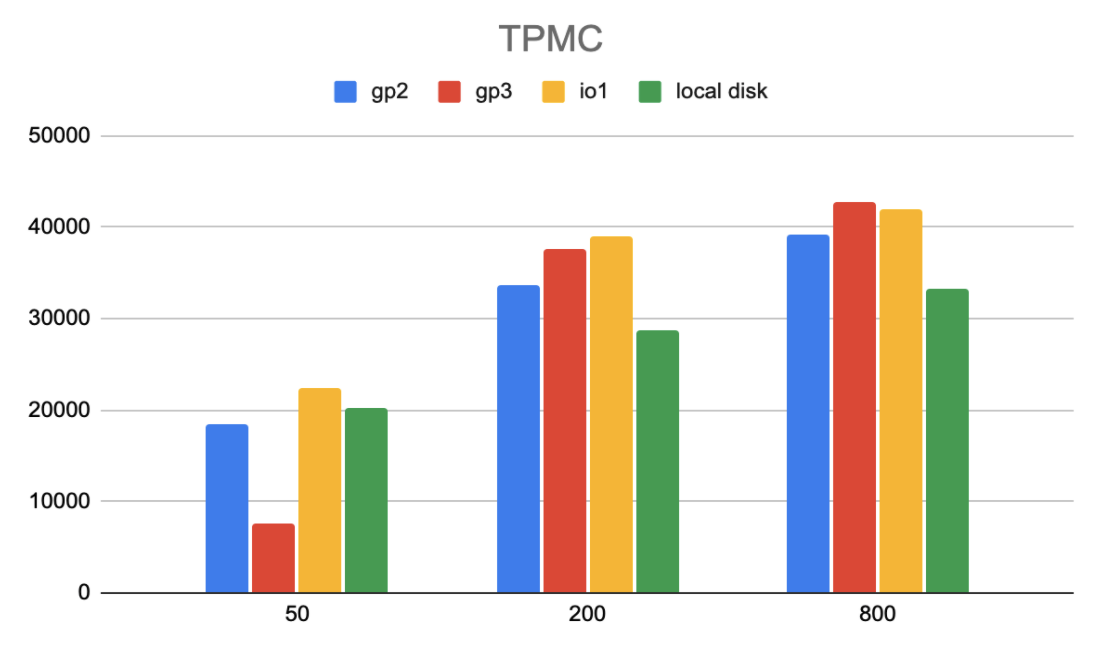
Transaction per minute (TPMC) in TPC-C workload. (Higher numbers are better)
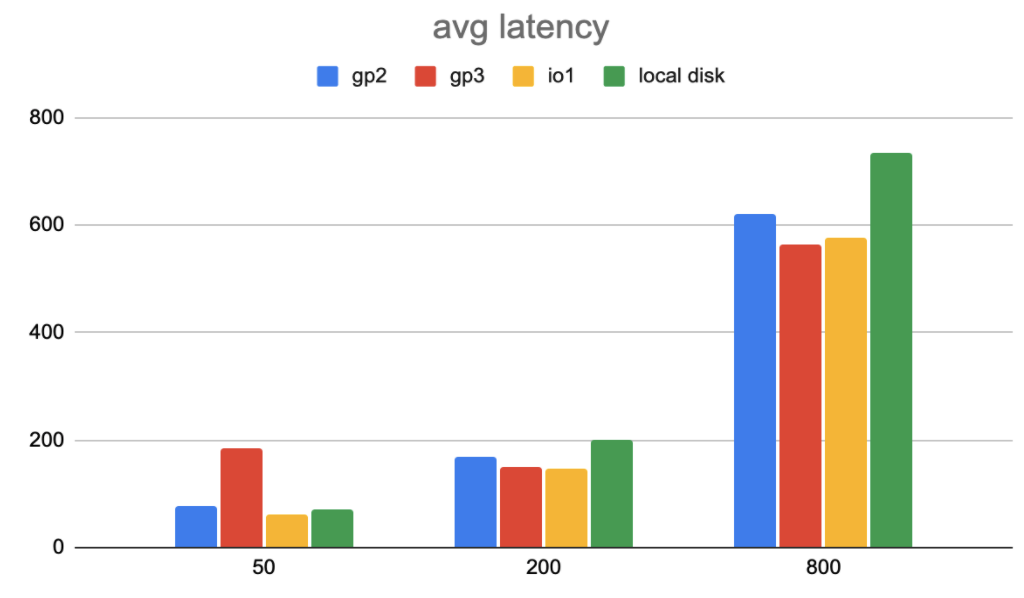
Average operation latency (ms) in TPC-C workload. (Lower numbers are better)
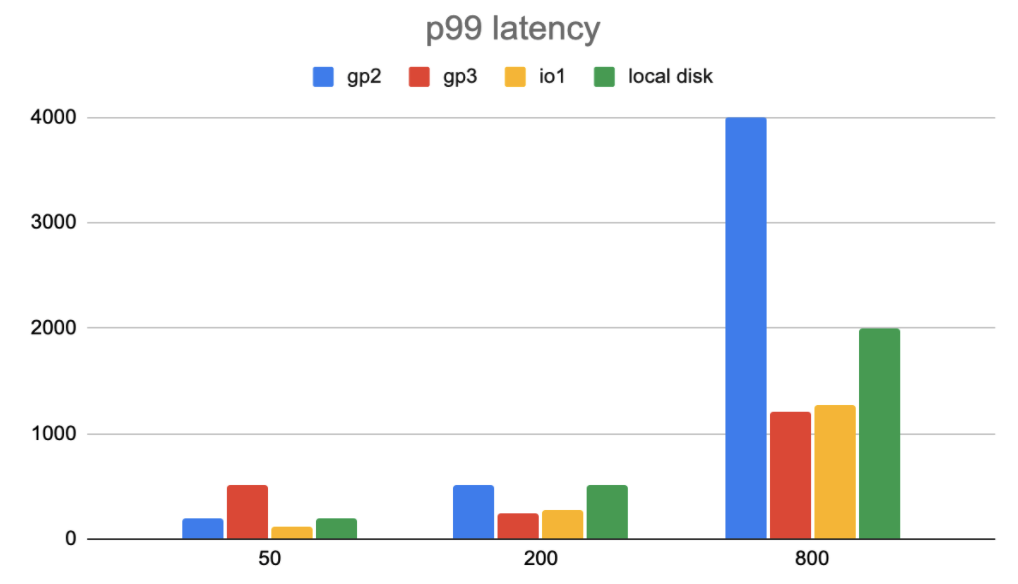
99-percentile operation latency (ms) in TPC-C workload. (Lower numbers are better)
Also, in the third figure (99-percentile operation latency in TPC-C workload), when there are 800 threads, the 99-percentile latency with EBS volume type gp2 skyrockets. This is because with gp2, the bandwidth reaches the limit.
To conclude, we chose gp3 as our EBS type. The EBS volume io2 was out of our consideration, as it was not available to r5b instances when we designed and implemented TiDB Cloud. Also, io2 block express was still in preview mode then. The EBS volume io1 has comparable latency with gp2 overall ,and io1 provides a higher bandwidth IOPS limit. However, io1 has extra cost based on provisioned IOPS. The EBS volume gp2 has limited bandwidth and IOPS, which are unconfigurable. This brings extra limitations to TiDB. As a result, we chose gp3.
Published at DZone with permission of Chenhao Huang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments