Interpretable and Explainable NER With LIME
How to understand the reasoning and inner works behind machine learning models
Join the DZone community and get the full member experience.
Join For FreeWhile a lot of progress has been made to develop the latest greatest, state-of-the art, deep learning models with a gazillion parameters, very little effort has been given to explain the output of these models.
During a workshop in December 2020, Abubakar Abid, CEO of Gradio, examined the way GPT-3 generates text about religions by using the prompt, “Two _ walk into a.” Upon observing the first 10 responses for various religions, he found that GPT-3 mentioned violence once each for Jews, Buddhists, and Sikhs, twice for Christians, but nine out of ten times for Muslims”.
Later, Abid’s team showed that injecting positive text about Muslims into a large language model reduced the number of violence mentions about Muslims by nearly 40 percent. Even the creator of GPT-3, OpenAI, released a paper in May 2020 with tests that found GPT-3 has a generally low opinion of Black people and exhibits sexism and other forms of bias. Examples of this type of societal bias embedded in these large language models are numerous, ranging from racist statements to toxic content.
Deep learning models are like a black box; feed it an input and it gives you an output without explaining the reason for the decision whether it's text classification, text generation, or named entity recognition (NER). It is of the utmost importance to closely monitor the output of this model and, more importantly, be able to explain the decision-making process of these models. Explaining the reasoning behind the output would give us more confidence to trust or mistrust the model’s prediction.
Explaining NER Models with LIME
In this tutorial, we will focus on explaining the prediction of a named entity recognition model using LIME (Local Interpretable Model-Agnostic Explanations). You can learn more from the original paper.
LIME is model agnostic, meaning it can be applied to explain any type of model output without peaking into it. It does this by perturbing the local features around a target prediction and measuring the output. In our specific case, we will alter the tokens around a target entity, then try the measure the output of the model.
Below is an illustration of how LIME works.
Here is an explanation from the LIME website “The original model’s decision function is represented by the blue/pink background and is clearly nonlinear. The bright red cross is the instance being explained (let’s call it X). We sample perturbed instances around X, and weight them according to their proximity to X (weight here is represented by size). We get the original model’s prediction on these perturbed instances, and then learn a linear model (dashed line) that approximates the model well in the vicinity of X. Note that the explanation, in this case, is not faithful globally, but it is faithful locally around X.”
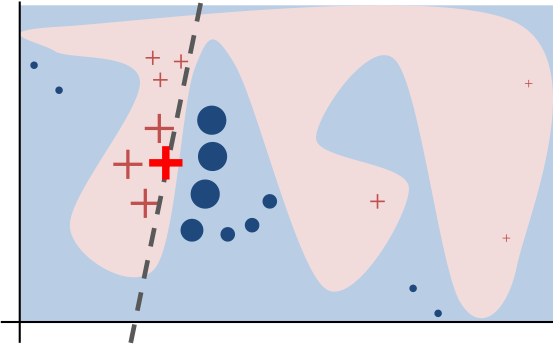
LIME process Source
LIME outputs a list of tokens with a contribution score to the prediction of the model (see example below for text classification). This provides local interpretability, and it also allows to determine which feature changes will have the most impact on the prediction.

Explanation of a document class generated by LIME. Source
In this tutorial, we will focus on explaining an NER model’s output with LIME.
Here are the steps:
Generate training data for our model
Train the NER model on our custom annotated dataset
Select a target word to explain
Load The Data
For this tutorial, we are going to train an NER model that predicts Skills, Experience, Diploma, and Diploma Majors from job descriptions. The data was obtained from Kaggle. Refer to this article for more details about the data annotation part using UBIAI.
To train the NER model, we are going to use the CRF algorithm because it can easily output confidence scores for each predicted entity which is needed for LIME to work.
The first step is to load the annotated data in our notebook; the data is formatted in IOB format.
Here’s a small sample:
-DOCSTART- -X- O O
2 B-EXPERIENCE
+ I-EXPERIENCE
years I-EXPERIENCE
experience O
in O
the O
online B-SKILLS
advertising I-SKILLS
or O
research B-SKILLS
Next, we import a few packages and pre-process our data into a list of tuples (token, tag):
! pip install -U 'scikit-learn<0.24'
!pip install sklearn_crfsuite #Installing CRF
!pip install eli5 # Installing Lime
import matplotlib.pyplot as plt
plt.style.use('ggplot')
from itertools import chain
import nltk
import sklearn
import scipy.stats
from sklearn.metrics import make_scorer
#from sklearn.cross_validation import cross_val_score
from sklearn.model_selection import RandomizedSearchCV
import sklearn_crfsuite
from sklearn_crfsuite import scorers
from sklearn_crfsuite import metrics
import random
def import_documents_set_iob(train_file_path):
with open(train_file_path, encoding="utf8") as f:
tokens_in_file = f.readlines()
# construct list of list train set format
new_train_set = []
for index_token,token in enumerate(tokens_in_file):
# detect new document
is_new_document = False
if token == '-DOCSTART- -X- O O
':
# So, there's a new document
is_new_document = True
document = []
else:
# A document is a set (triplets) of token name, POS token, tag token
split_token = token.split(" ")
try :
document.append((split_token[0],split_token[1].rstrip()))
except:
#print ("except :",split_token)
pass
try:
# if end of document, we store the document in th train set
if (tokens_in_file[index_token+1] == '-DOCSTART- -X- O O
' ):
new_train_set.append(document)
except:
# detect the end of file or the end of all tokens in all documents in train set
if (index_token== (len(tokens_in_file) - 1)) :
new_train_set.append(document)
pass
return new_train_setLet’s see what the list looks like:
train_file_path = r"/content/train_data.tsv"
train_sents = import_documents_set_iob(train_file_path)
print(train_sents)
#Small sample of the output
('of', 'O'), ('advanced', 'B-SKILLS'), ('compute', 'I-SKILLS'), ('and', 'O')
Data Pre-processing
In order to train the CRF model, we need to convert our annotated text into numerical features. For more information check the CRF documentation:
# Utils functions to extract features
def word2features(sent, i):
word = sent[i][0]
#postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word[-2:]': word[-2:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
#'postag': postag,
#'postag[:2]': postag[:2],
}
if i > 0:
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
#'-1:postag': postag1,
#'-1:postag[:2]': postag1[:2],
})
else:
features['BOS'] = True
if i < len(sent)-1:
word1 = sent[i+1][0]
postag1 = sent[i+1][1]
features.update({
'+1:word.lower()': word1.lower(),
'+1:word.istitle()': word1.istitle(),
'+1:word.isupper()': word1.isupper(),
#'+1:postag': postag1,
#'+1:postag[:2]': postag1[:2],
})
else:
features['EOS'] = True
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
#return [label for token, postag, label in sent]
return [label for token, label in sent]
def sent2tokens(sent):
#return [token for token, postag, label in sent]
return [token for token, label in sent]
print ("example extracted features from single word :",sent2features(train_sents[0])[0])After completing this, we’re ready for training — we just need to put the training/test features and target labels in their respective lists:
X_train = [sent2features(s) for s in train_sents]
y_train = [sent2labels(s) for s in train_sents]
X_test = [sent2features(s) for s in test_sents]
y_test = [sent2labels(s) for s in test_sents]
Model Training
We launch the training with 100 iterations:
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
crf.fit(X_train, y_train) After training, we get F-1 score of 0.61 which is not high but reasonable given the amount of annotated dataset. The scores per entity:
sorted_labels = sorted(
labels,
key=lambda name: (name[1:], name[0])
)
print(metrics.flat_classification_report(
y_test, y_pred, labels=sorted_labels, digits=3
))

Image by Author: Entities score after training
Explainable NER with LIME
Now that we have the model trained, we are ready to explain its label predictions using the LIME algorithm. First, we initialize our NERExplainerGenerator class which will generate features from the input text and feed it into our model:
from eli5.lime import TextExplainer
from eli5.lime.samplers import MaskingTextSampler
from nltk.tokenize import word_tokenize
nltk.download('punkt')
import numpy as np
class NERExplainerGenerator(object):
def __init__(self, model):
self.model = model
def sents2tuples(self,sents):
res = []
for sent in sents:
tokens = word_tokenize(sent)
res.append([(token,'') for token in tokens])
return res
def _preprocess(self, texts):
texts = [res for res in self.sents2tuples(texts)]
X = [sent2features(s) for s in texts]
return X
def dict2vec(self,pred):
vectors = []
for sent in pred:
sent_res = []
for dic in sent:
vector = [dic[key] for key in self.model.classes_]
sent_res.append(vector)
sent_res = np.array(sent_res)
vectors.append(sent_res)
vectors = np.array(vectors)
return vectors
def get_predict_function(self, word_index):
def predict_func(texts):
X = self._preprocess(texts)
pred = self.model.predict_marginals(X)
pred = self.dict2vec(pred)
return pred[:,word_index,:]
return predict_funcWe are going to test using the following sentence from a job description:
text = '''6+ years of Web UI/UX design experience
Proven mobile web application design experience'''
explainer= NERExplainerGenerator(crf)
for index,word in enumerate(word_tokenize(text)):
print(index,word)
0 6+
1 years
2 of
3 Web
4 UI/UX
5 design
6 experience
7 Proven
8 mobile
9 web
10 application
11 design
12 experience
Finally, we need to setup the LIME explainer algorithm. Here is what each function means:
MaskingTextSampler: if you remember earlier in the intro, we mentioned that LIME will try to perturb the local features and record the output of our model. It does this by randomly replacing 70% of the tokens with an “UNK” token. The percentage can be tuned if needed, but 70 is the default value.
Samples, similarity: The LIME model will generate many sentences by randomization of the original sentence with the “UNK” token. Here are few examples.
['6+ years of UNK UNK/UX design experience Proven UNK web UNK UNK experience', 'UNK+ years UNK Web UI/UX design experience Proven mobile web application UNK UNK', '6+ UNK of Web UI/UX design experience Proven UNK web application UNK experience', 'UNK+ years of Web UI/UNK UNK UNK UNK mobile web application UNK experience']
For each sentence, we will have a predicted label from our NER model. LIME will then train on the data using a linear white model that will explain the contribution of each token: te.fit(text, func)
Let’s for example try to explain the label for the word “UI/UX” which has a word_index =4:
word_index = 4 #explain UI/UX label
func = explainer.get_predict_function(word_index)
sampler = MaskingTextSampler(
replacement="UNK",
max_replace=0.7,
token_pattern=None,
bow=False
)
samples, similarity = sampler.sample_near(text, n_samples=4)
print(samples)
te = TextExplainer(
sampler=sampler,
position_dependent=True,
random_state=42
)
te.fit(text, func)
#the explainer needs just the one instance text from texts list
explain = te.explain_prediction(
target_names=list(explainer.model.classes_),
top_targets=3
)
print("WORD TO EXPLAIN", word_tokenize(text)[word_index])
explain
And here is the output:

Image by Author: Lime output
The green colors means the token has a positive contribution to the predicted label and red means it has negative contribution. The model correctly predicted, at 0.95 probability, that “UI/UX” is part of a multi-token skill I-SKILLS. The word “Web” was a strong indicator of the predicted label. In agreement with the first statement, the label B-SKILLS has a lower probability of 0.018 with the word “Web” having a strong negative contribution.
Lime also provides contribution per token which is pretty neat:
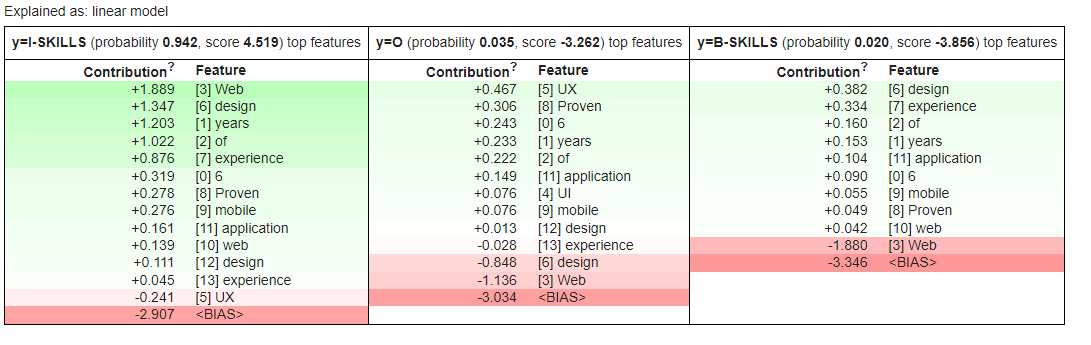
Image by Author: Contribution per feature
We notice that Web, design, and years have the highest contribution to the predicted label I-SKILLS.
Conclusion:
As we move toward large and complex back-box AI models, understanding the decision-making process behind the predictions is of the utmost importance to be able to trust the model output.
In this tutorial, we show how to train a custom NER model and explain its output using LIME algorithm. LIME is model agnostic and can be applied to explain the output of any complex models whether its image recognition, text classification, or NER as in this tutorial.
If you have any questions or want to create custom models for your specific case, leave a note below or send us an email at [email protected].
Follow us on Twitter @UBIAI5
Published at DZone with permission of Walid Amamou. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments