Introduction to Azure Data Lake
In the first part of a series on the Azure Data Lake, get an understanding of the concept behind data lakes and learn how they work.
Join the DZone community and get the full member experience.
Join For FreeThis article is related to the general architecture of Azure Data Lake. I hope it will be a good foundation to start with Azure Data Lake. The article is a representation of my understanding of Azure Data Lake. In the coming days, we are going to be posting more advanced articles on this.
Before jump into Azure Data Lake, we have to understand the concept behind a data lake.
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed. While a hierarchical data warehouse stores data in files or folders, a data lake uses a flat architecture to store data. Each data element in a lake is assigned a unique identifier and tagged with a set of extended metadata tags. When a business question arises, the data lake can be queried for relevant data, and that smaller set of data can then be analyzed to help answer the question.
A data lake, on the other hand, maintains data in their native formats and handles the three Vs of big data — volume, velocity, and variety — while providing tools for analyzing, querying, and processing. Data lakes eliminate all the restrictions of a typical data warehouse system by providing unlimited space, unrestricted file size, schema on read, and various ways to access data (including programming, SQL-like queries, and REST calls).
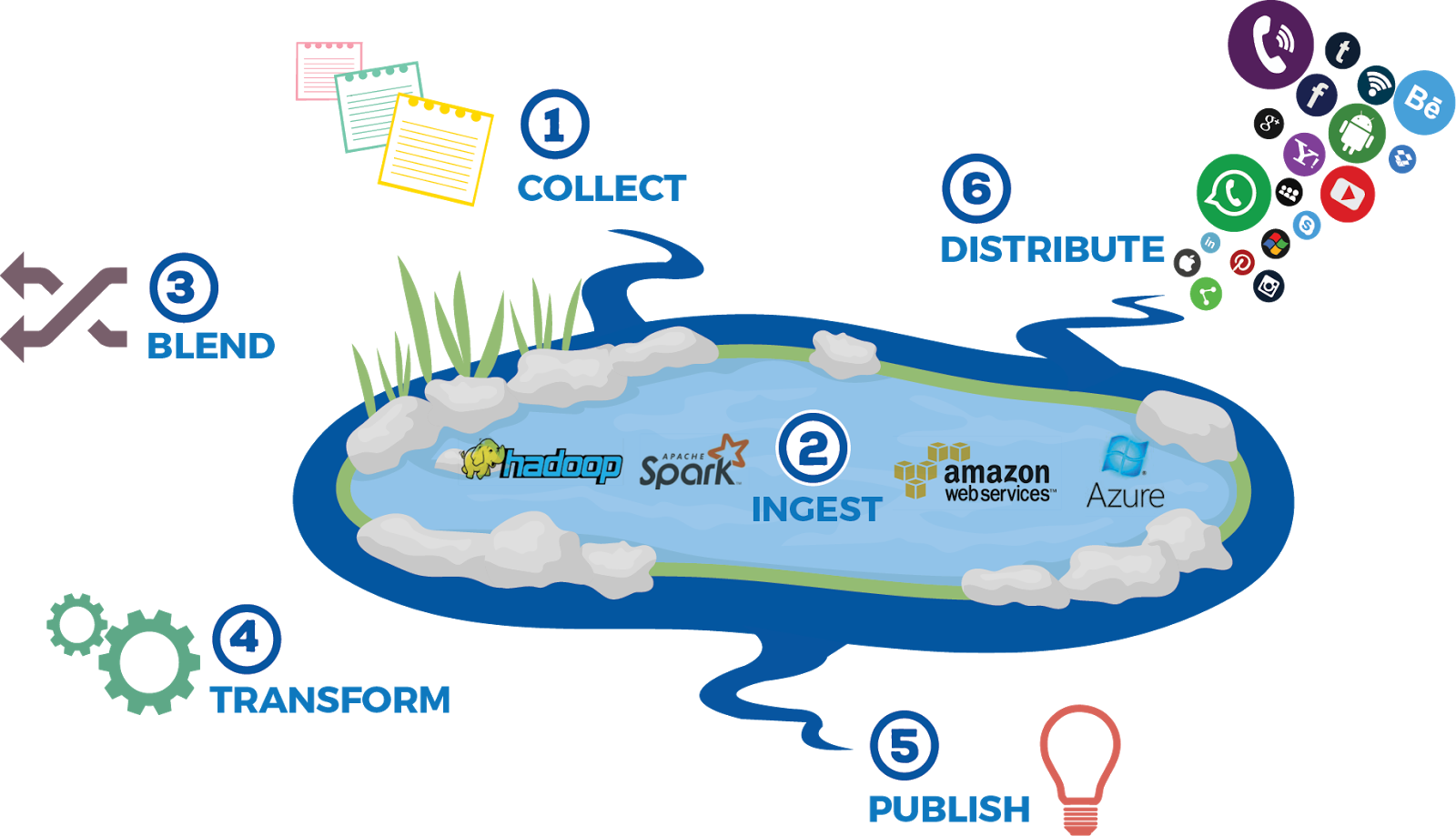
With the emergence of Hadoop (including HDFS and YARN), the benefits of the data lake (previously available only to the most resource-rich companies like Google, Yahoo, and Facebook) became a practical reality for just about anyone. Now, organizations who had been generating and gathering data on a large scale but had struggled to store and process them in a meaningful way have more options.
Feature of Azure Data Lake
Azure Data Lake is a new kind of data lake from Microsoft Azure. The features that it offers are mentioned below.
The ability to store and analyze data of any kind and size.
Multiple access methods including U-SQL, Spark, Hive, HBase, and Storm.
Built on YARN and HDFS.
Dynamic scaling to match your business priorities.
Enterprise-grade security with Azure Active Directory.
Managed and supported by an enterprise-grade SLA.
Broadly, the Azure Data Lake is classified into three parts.


The data lake store provides a single repository where organizations upload data of just about infinite volume. The store is designed for high-performance processing and analytics from HDFS applications and tools, including support for low-latency workloads. In the store, data can be shared for collaboration with enterprise-grade security.
Azure Data Lake Analytics
Data Lake analytics is a distributed analytics service built on Apache YARN that compliments the Data Lake store. The analytics service can handle jobs of any scale instantly with on-demand processing power and a pay-as-you-go model that's very cost effective for short-term or on-demand jobs. It includes a scalable distributed runtime called U-SQL, a language that unifies the benefits of SQL with the expressive power of user code.
Azure HDInsight is a full stack Hadoop Platform as a Service from Azure. Built on top of Hortonworks Data Platform (HDP), it provides Apache Hadoop, Spark, HBase, and Storm clusters.
I hope this was helpful!
Published at DZone with permission of Joydeep Das. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments