Java Thread Synchronization and Concurrency Part 2
Join the DZone community and get the full member experience.
Join For FreeIntroduction
This is the second part of my two-part series on thread synchronization. If you missed the first article, check it out. In the previous article, we covered concepts of threads, synchronization techniques, and memory model of both Java and CPU. In this article, we'll focus on concepts of concurrency, how to execute tasks in concurrent mode, and the various classes and services in Java that offer concurrency (thread-pool).
Multi-Threading Costs
Before getting into concurrency, we have to understand the costs associated with multi-threading. The costs include application design, CPU, memory, and context switching. Below are some of the considerations for concurrency:
- The application design has to be very detailed, covering all possible cases to support concurrency using multiple threads. It will be better to cover all corner cases in the design so that developers know how to handle scenarios that don't lead the application to a dead-lock or similar issues. Multi-threading makes the application design more complex in areas associated with shared data access, read-write locks, and critical sections.
- Context switching — when CPU switches from executing one thread to another, the CPU needs to save local data, program pointers, etc. of the current thread. Then, the CPU loads data and the program pointer of the next thread that will be executed. This is called context switching, and it uses a lot of CPU cycles if there are too many context switches.
- Context switching is always an overhead, and it is not cheap. It is a resource and CPU intensive process, as the CPU has to allocate memory for the thread stack and CPU time for context switches!
You may also like: Java Concurrency, Part 3: Synchronization With Intrinsic Locks.
Concurrency Models
A concurrency model is an approach of designing applications that executes a set of tasks to achieve concurrent execution, and thereby parallelism. Some types of concurrency models that are generally used are:
- Parallel Workers (Stateful or Stateless).
- Event-Driven (E.g: Akka, Vert.x) - does not share states.
Shared State
As the name suggests, the states are shared across threads to achieve concurrency. The states could be instances of objects or even primitives.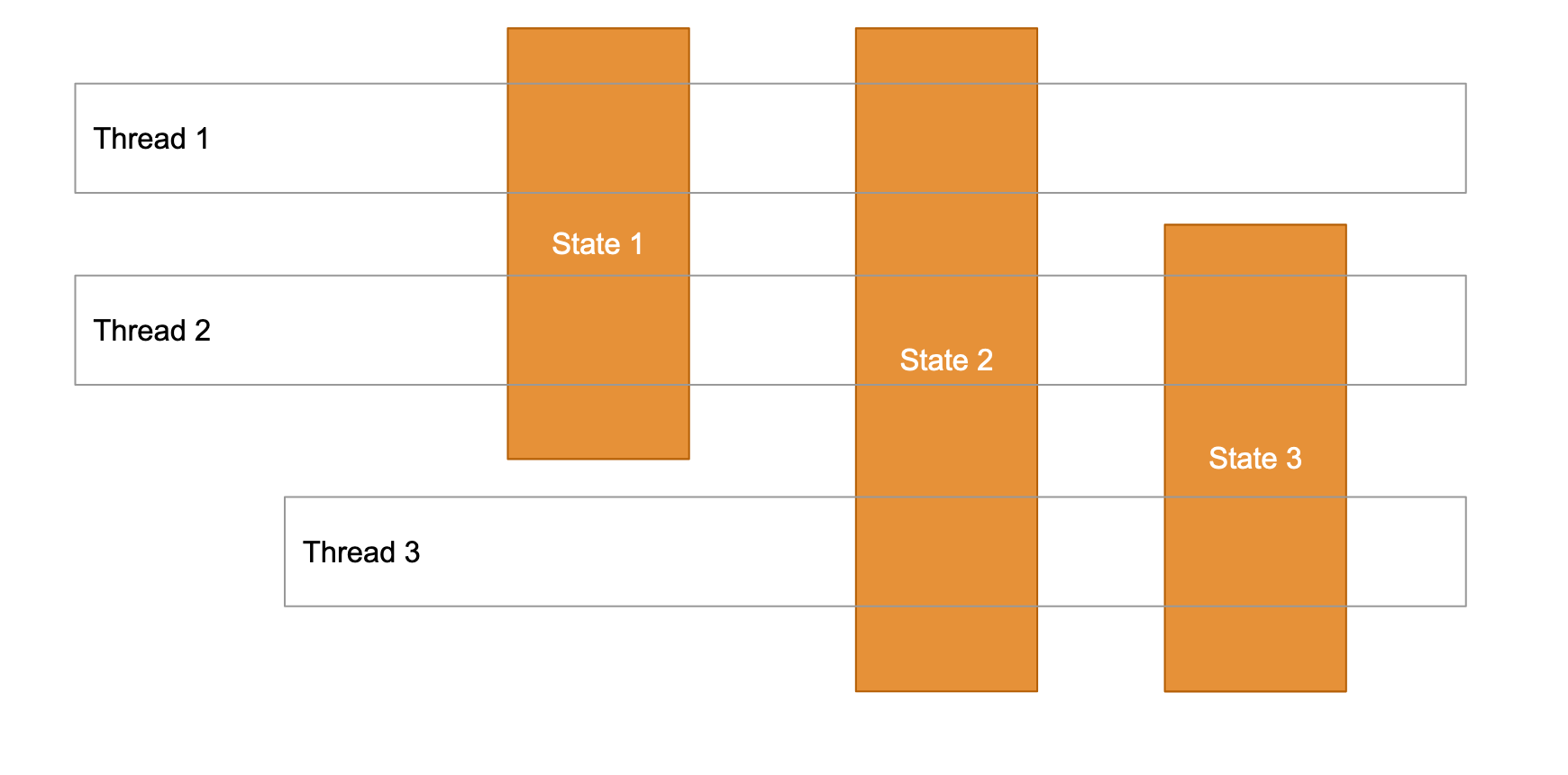
In a shared state model, some issues that may arise are race conditions and dead locks due to synchronization. As more threads increase in the system, it becomes more complex to manage the state/object access control, debugging, etc.
Independent State
In this concurrency model, the states are not shared across threads and they work on independent copies on data.
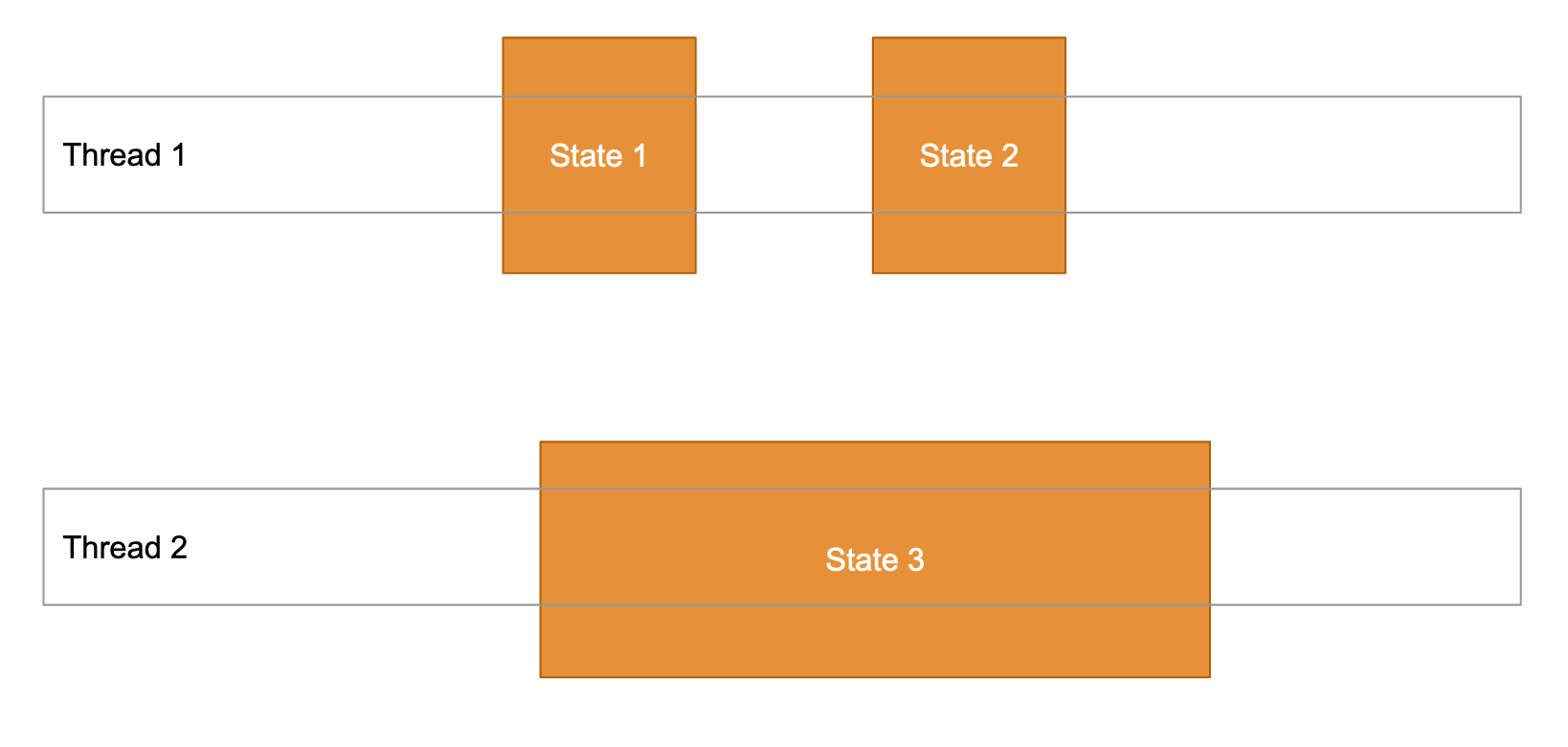
This is a preferred approach, as threads work on independent copies of data. Threads can be synchronized by external, immutable objects and avoid the most concurrency problems.
Java Executor Framework (Thread Pool)
The Java Executor framework consists of Executor, ExecutorService, and Executors. A thread pool is represented by an instance of the ExecutorService. A task can be submitted to the ExecutorService that will be completed in the future.
Executor - This is the core interface, which is an abstraction for parallel execution. This separates the task from the execution (unlike Thread which combines both). The Executor can run on any number of Runnable tasks, but a thread can run only on one task.
ExecutorService - This is also an interface and an extension of the Executor interface. It provides a facility for returning a Future object (result), and terminate or shut down the thread pool. The two main methods of the ExecutorService are execute() (executes a task with no return object) and submit() (executes a task and returns a Future). Future.get() returns the result and is a blocking method that will wait until the execution is complete. It is also possible to cancel the execution using a Future object.
Executors - This is a utility class (similar to Collections in the Java Collection framework). This class provides factory methods to create different types of thread pools. This is covered more in detail a little later.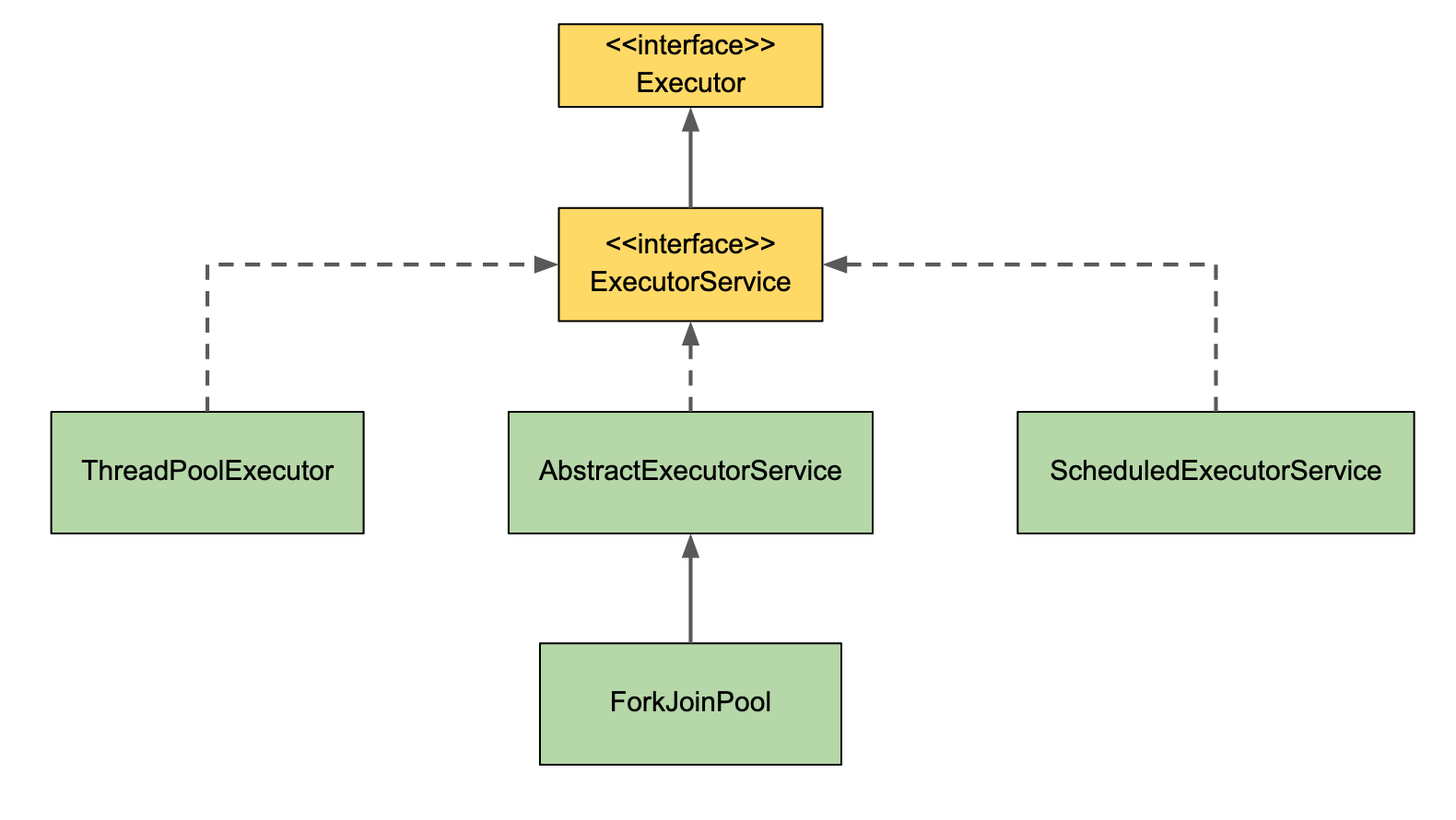
Finer Points
- Executor defines the
execute()method, which accepts aRunnablewhileExecutorService.submit()accepts aRunnableorCallable. submit()returns aFutureobject.ExecutorServiceprovides methods toshutdown()andshutdownNow()to control the thread pool.shutdown()allows previously submitted tasks to complete before terminating the pool.shutdownNow()is similar toshutdown(), but the pending tasks in the queue will be aborted.
Thread Pool for Concurrency
As mentioned earlier, the thread pool instance is represented by an instance of the ExecutorService. There are flavors of thread pools that can be created based on each use case:
SingleThreadExecutor - A thread pool with only one thread. All tasks submitted will be executed sequentially. E.g: creating an instance of this thread pool, Executors.newSingleThreadExecutor().
Cached Thread Pool - A thread pool that creates as many threads as it needs to execute in parallel. Older available threads will be reused for new tasks. If a thread is not used in the last 60 seconds, it will be terminated and removed from the pool. E.g: creating an instance of this thread pool Executors.newCachedThreadPool().
Fixed Thread Pool - A thread pool with a fixed number of threads. If a thread is not available for a task, then the task will be put into a queue. This task remains in the queue until other tasks are completed or when a thread becomes free, it picks this task from the queue to execute it. E.g: creating an instance of this thread pool Executors.newFixedThreadPool().
Scheduled Thread Pool - A thread pool made to schedule future tasks. Use this Executor if the need is to execute tasks as a fixed or scheduled interval. E.g: creating instance of this thread pool Executors.newScheduledThreadPool().
Single Thread Scheduled Pool - A thread pool with only one thread to schedule tasks in the future. E.g: creating an instance of this thread pool Executors.newSingleThreadScheduledPool().
ForkJoinPool
A ForkJoinPool works on the work-stealing principle and was added in Java 7. The ForkJoinPool is similar to the ExecutorService, but with one difference being that the ForkJoinPool splits work units into smaller tasks (fork process) and then is submitted to the thread pool.
This is called the forking step and is a recursive process. The forking process continues until a limit is reached when it is impossible to split into further sub-tasks. All the sub-tasks are executed, and the main task waits until all the sub-tasks have finished their execution. The main task joins all the individual results and returns a final single result. This is the joining process, where the results are collated and a single data is built as an end result.
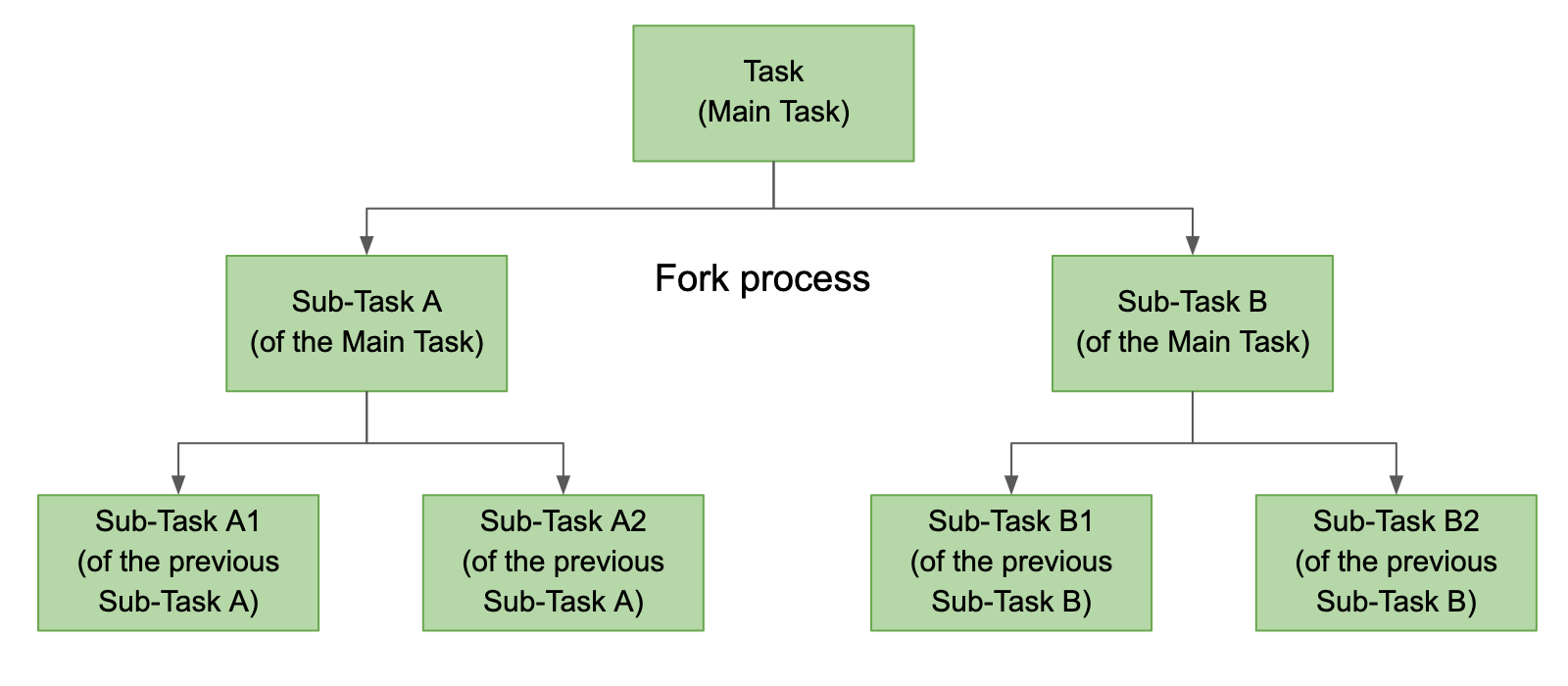
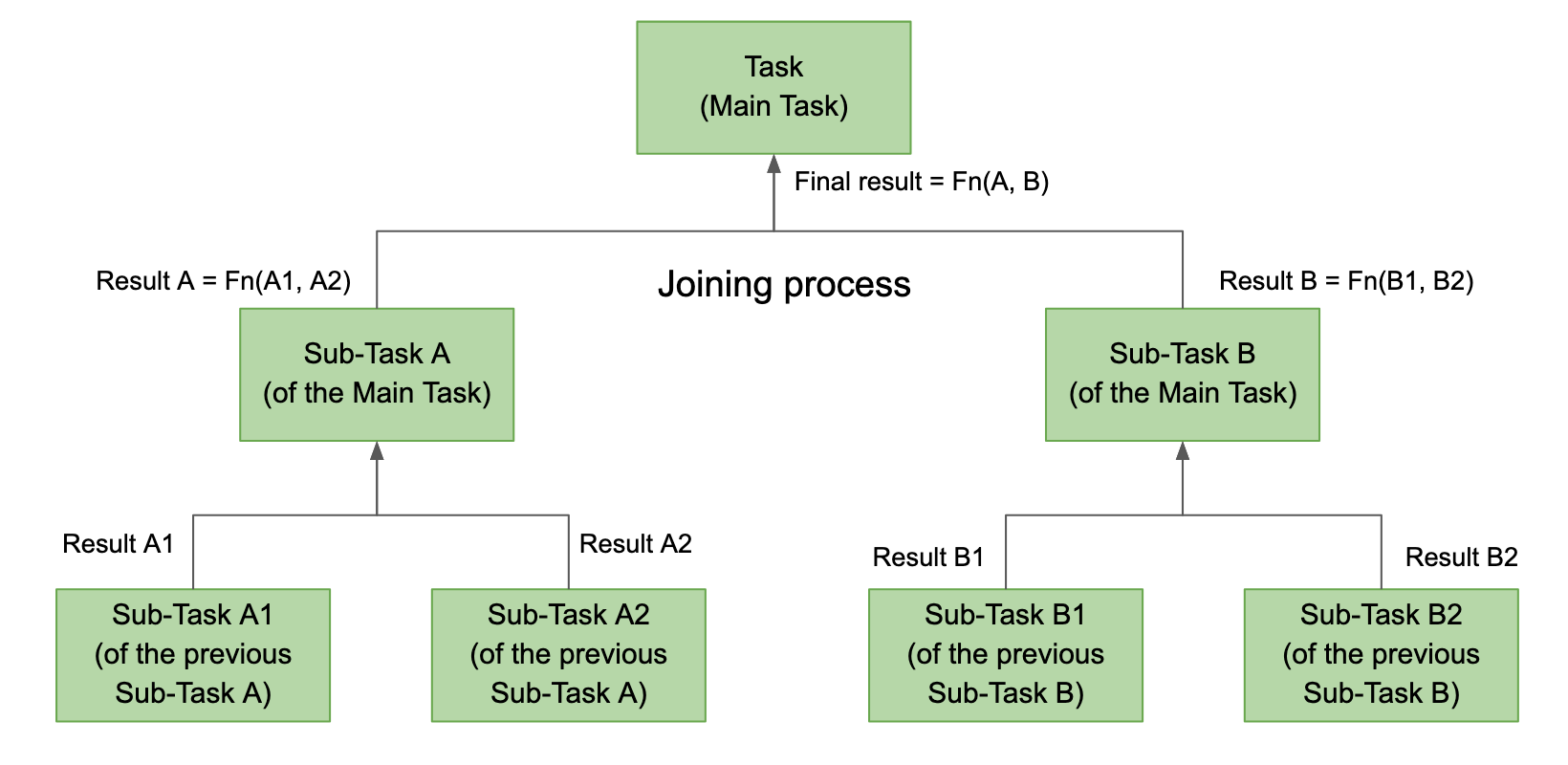
There are two ways to submit a task to a ForkJoinPool:
RecursiveAction - A task which does not return any value. It does some work (e.g. copying a file from disk to a remote location and then exit). It may still need to break up its work into smaller chunks, which can be executed by independent threads or CPUs. A RecursiveAction can be implemented by sub-classing it.
RecursiveTask - A task that returns a result to the ForkJoinPool. It may split its work up into smaller tasks and merge the result of the smaller tasks into one result. The splitting of work into sub-tasks and merging may take place at several levels.
Summary
Hopefully, this series has helped readers to better understand the various aspects of threads, synchronization mechanisms, memory models, and thread pooling for concurrency and parallelism in Java. This is a large topic and requires a lot those new to it to dig deep to get a strong understanding of how to build robust, concurrent applications.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments