K8s Know-How: Service Discovery and Networking
In this post, we will take a look at how Kubernetes provides networking and service discovery features which allow microservices to communicate.
Join the DZone community and get the full member experience.
Join For FreeThis is the seventh article of my Kubernetes Know-How series.
In first six articles, we have learned how to use pod, service, replicaset, deployment, configmap, and secret in K8s.
In this article, we will see how K8s provides networking and service discovery features. In the microservices world, when services are distributed, it's absolutely essential to have service discovery and load balancing. Imagine you have a front-end talking to a backend and there are one or multiple instances. For a front-end, the most important thing is to find a backend instance and get the job done. It's nothing but networking your containers. In fact, service discovery mechanisms in K8s are very similar to those of Docker Swarm.
Before I get into the details of K8s service discovery, let me clarify something. Many developers think, 'why can’t we have multiple containers in the same pod?' One needs to understand that, even though technically its possible to pack multiple containers in the same pod, it comes at the cost of higher mantainence and lower flexibility. Imagine you have a MySQL and Java-based web app in the same container. How cumbersome it would be to manage that pod. Upgrade, maintenance and release would become complicated. Even if you are ready to take accountability for it, just imagine a scenario in which a pod crashed. Prima facie, you can not assume anything as either MySQL could be a culprit or your web app could have been the root cause. It’s a pain in the neck and don’t forget that you have different teams responsible for managing these containers. Therefore, in almost all of the cases one pod represents on container.
K8s services provide discovery and load balancing. We have already seen K8s service and how to use it and different types of services – clusterIP, nodeport, and so on. Let’s refresh our memory by going through an example.

Now let me slightly change the example to have two service: a front-end and a backend. In addition, I am changing the type of the service from NodePort to ClusterIP. We used NodePort as we wanted to access the web console running inside a K8s cluster from the outside world. However, in a production environment you would not want to do so. In fact, you just want service collaboration inside a K8s cluster and for that we only require ClusterIP. Notice that I have used the word “only.” I am emphasizing this as NodePort involves two services: one for exposing a service on a port of a node and one for the ClusterIP service that comes included by default.
Now, in the example, we are going to have backend and front-end services. The front-end service gets the HTTP request and then invokes the backend service, which is REST-based and using RestController.
A basic service generates a random IP address, referred to as ClusterIP, that occupies a defined range (10.32.0.0/16 by default). Now accessing any entity in K8s cluster using the IP address is a naïve thing to do. K8s dynamically allocates IP addresses to pods and services. Each time we restart a cluster or a pod or a service, any resource most probably gets a new IP address. Therefore, you should always use a unique name for the service. We require a tool to resolve the name to the IP address of any instance of the desired service. That tool is called as Kube-DNS.
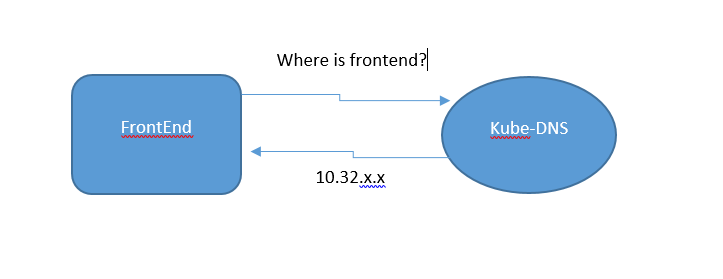
Kube-DNS is a database containing key-value pairs for lookup. Keys are names of K8s's services and values are IP addresses on which those services are running. K8s gurantees to maintain this service and you don’t have to manage anything about this service. This service wraps up a pod named 'Kube-DNS.'
Okay, let me just take a pause here. This is a lot of theory without any action. Time to get into action.

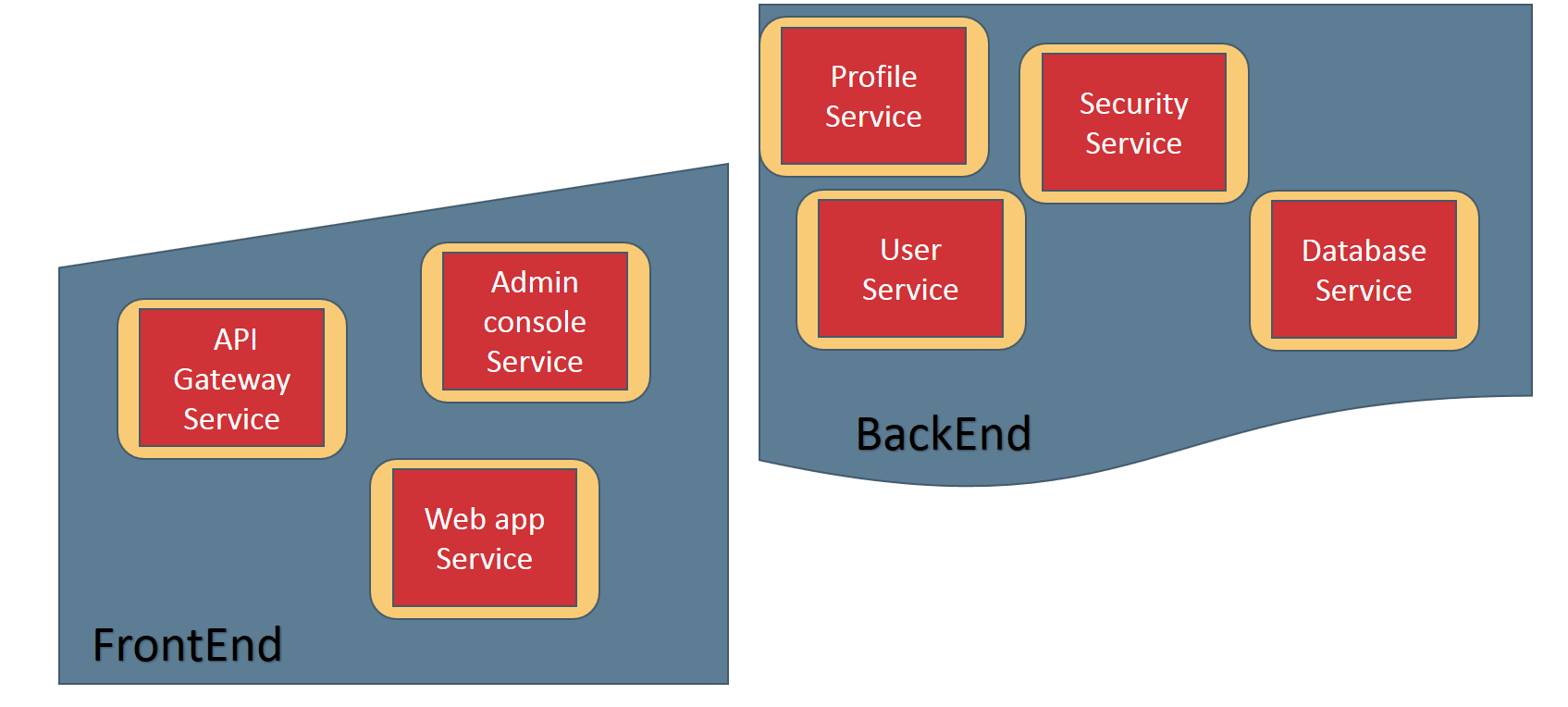
Did you notice the Kube-DNS pod? You cannot find the Kube-DNS entry as we are querying the “default” namespace. Yes, it's time to introduce one more K8s object – namespaces. Namespaces are a way of arranging the different resources. In a production environment, you will typically have thousnads of resources (pods, services or deployments). You require an elegant way to manage all of those resource. Let's take a typical web app. Together let's think about the basic component that needs to be part of this web app. You require a web app container, an admin console container, a security service, a database service, an API gateway, a profile service, a user service, and so on. Can you categorize these components or services into two buckets. The API gateway, admin console, and web app services are categorized as front-end. The others are categorized into the backend. Now it's ideal to have two namespaces: 'FrontEnd' and 'BackEnd.'
Let’s start minikube and execute the command kubectl get all. Until now, we have focused on pods, services, replica sets, and deployments (which we have manually deployed). Now it’s time to understand which namespaces exist in the K8s system. In order to take a look at the namespaces, use the command kubectl get namespaces.
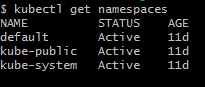
Namespaces are pretty much similar to folders in operating system or packages in programming languages. In fact, languages such as C# have the namespace concept. Whenever you create a resource or any object in K8s, default namespace is used. Similar logic is used whenever any command is fired without a namespace, i.e. a default namespace is used. The purpose of namespaces is to provide isolation.
In order to get details from a specific namespace, you have to use the command:
kubectl get all –n <namespace_name>K8s uses kube-public and kube-system namespacs for internal implementation.
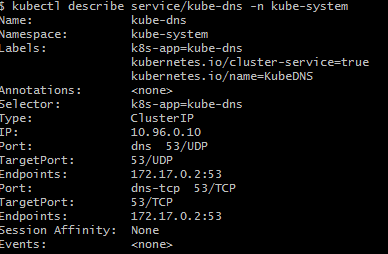
Now use the command: kubectl describe svc kube-dns. It turnes out that if you want to use any command with any object in K8s, you have to provide namespace details as well.

Did you get the same error as I did? What went wrong?
This happens with many experts, especially DevOps folks, while working in production as well. People tear their hair out wondering why their pod disappeared even if describe command format is correct and object name exists. I emphasizing this as I have seen many make this mistake (including myself!).
Now let’s learn how to make use of the Kube-DNS service. For that, we need to get into the implementation of our Spring Boot front-end and backend applications. These are really straight forward and simple apps. Our front-end consumes a REST service from the backend and, therefore, there is a service collaboration. Now, in a normal scenario, we would have directly used a REST URL from the backend in the front-end as follows:
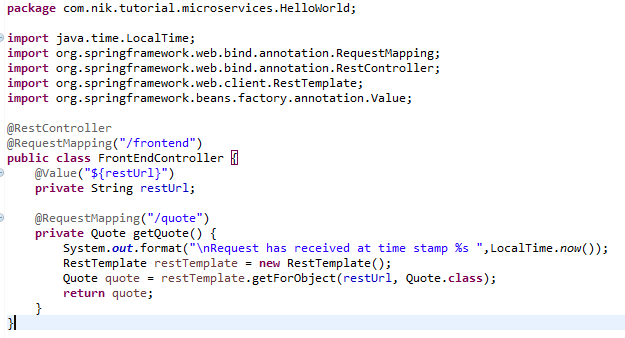

In case of K8s deployment, we cannot do this, as we don’t know three important things:
- The hosts on which the backend and front-end services are running.
- IP address of the container that backend is in.
- How many instances of the backend service are running.
Now let's containerize these applications. For example purposes, I have already uploaded Docker images to my Dockerhub.

There is only one change needed in the application.properties file in order to factor in K8s cluster. Instead of localhost, I am using front-end-service-name. I will explain this in a moment.

Let's take a look at the pod and service definition.
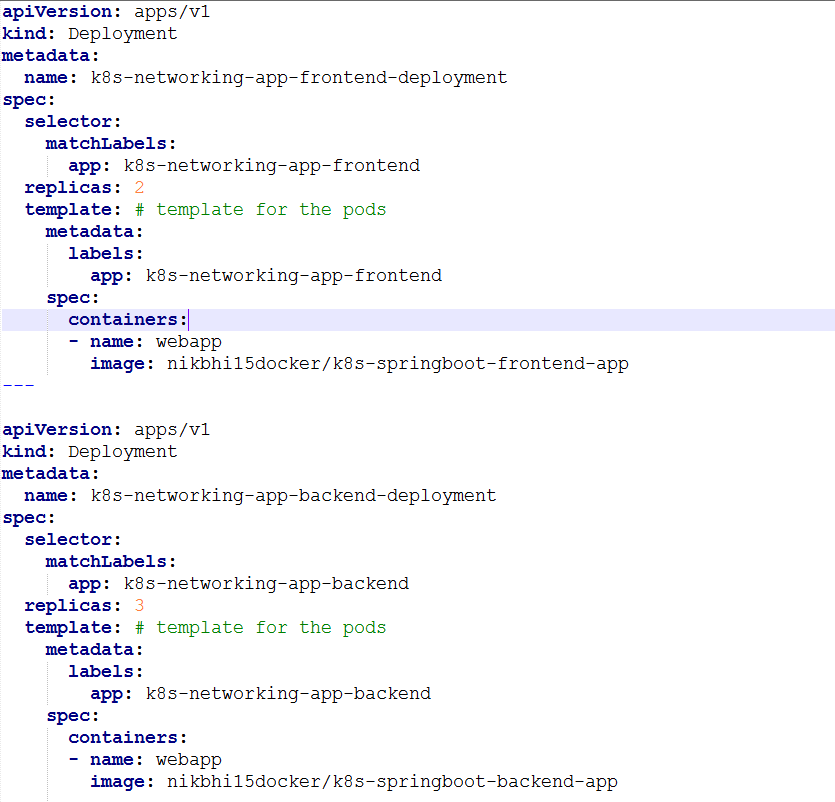

Now apply the changes.
Now let's see what has happened in the cluster. You will notice that there are two instances of front-end deployment and three instances of backend deployment. Lets sh one of the instances and figure out the service name. Then nslookup the service names used in the service definition.
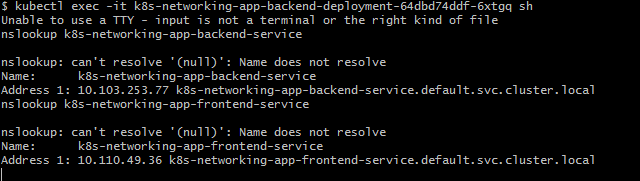
You can see that the service name is getting resolved and nslookup gives the name and address of the services. Why? Let's dig down a bit deeper. If you are familiar with Linux file systems, then you must have sensed what the next step would be. The next step is to find the resolv.conf file. It is the name of a computer file used in various operating systems to configure the system's Domain Name System (DNS) resolver.
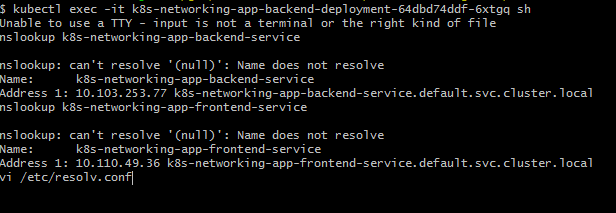
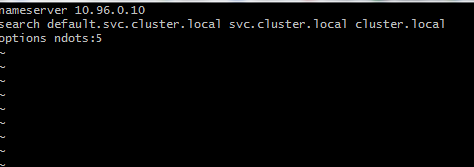
Now note down the IP address of the naming server and the name of the service. Doesn’t the name of the service match to REST URL that we have configured in the application.properties file?
Just now we have learned how to discover any service in K8s just by using a service name. Now one may wonder why we cannot use only a service name to discover a service. For instance, why not just use “k8s-networking-app-backend-service,” as nslookup works with it? Here, I want to bring in the concept of a fully qualified domain name (FQDN). It's recommended to use FQDN, as namespace is part it. Also, if you meticulously look at the resolv.conf entry on line two, then you will find three entries against the key, “search.” This means that, in case a service is not discovered, we can append the first string to the service name, i.e. <service_name>.default.svc.cluster.local. In case of failure, we can append the second string, and in case of failure again resort to a third string. It’s a clunky string, however, i'ts essential to recognize that it's a very important part of service discovery.
This is how a service deployed in K8s can collaborate with any other service. The key to it is the DNS entry and there is a pattern for any service : <service_name>.<name_space>. svc.<cluster_name>:<ClisterIP port>. This is all about service discovery in K8s.
You can this find project in my GitHub repo.
Opinions expressed by DZone contributors are their own.
Comments