What We Learned Migrating to a Pub/Sub Architecture: Real-World Case Studies from High-Traffic Systems
Kafka-powered migration of an e-commerce platform—focused on scalability, fault tolerance, and clean event-driven design.
Join the DZone community and get the full member experience.
Join For FreeModern e-commerce platforms must handle millions of users and thousands of simultaneous transactions. Our case study involves a large retail monolith serving millions of customers (~4,000 requests/s). The monolith struggled with scalability, so we re-architected it into microservices using Apache Kafka as the core Pub/Sub backbone. Kafka was chosen for its high throughput and decoupling: it “decouple[s] data sources from data consumers” for flexible, scalable streaming. For example, Figure 1 illustrates typical retail event-streaming use cases: real-time inventory, personalized marketing, and fraud detection. Major retailers like Walmart deploy ~8,500 Kafka nodes processing ~11 billion events per day to drive omnichannel inventory and order streams , while others (e.g. AO.com) correlate historical and live data for one-on-one marketing. These examples reflect Kafka’s strengths: massive throughput (millions of events/sec ) and service decoupling (Kafka can “completely decouple services” ). We set a goal to replicate these capabilities in our e-commerce migration.
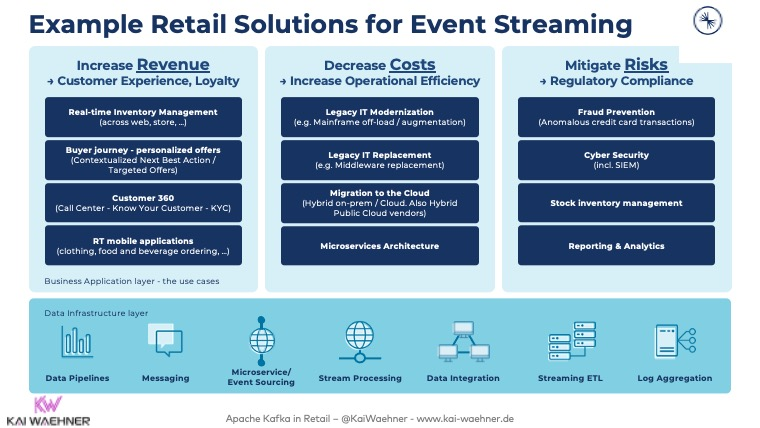
Figure 1: Business use-case categories enabled by Kafka event streaming in retail (source: Kai Waehner ). Kafka applications span revenue-driving features (customer 360, personalization), cost-savings (modernizing legacy systems, microservices), and risk mitigation (real-time fraud and compliance). In our migration, we similarly targeted these areas: for example, we replaced a monolithic order-flow (lock-step API calls) with independent services that exchange OrderPlaced, InventoryUpdated, etc. events via Kafka topics. This eliminated tight coupling between services, aligning with Kafka’s role as a “dumb pipe” where only endpoints enforce logic.
Case Study Background and Motivation
The legacy e-commerce platform was a PHP-based monolith handling catalog, orders, inventory, and customer data. With business growth, the monolith could not scale further. Maintaining feature velocity was hard because every change risked the entire system. We needed scalability, resilience, and faster releases. Shifting to event-driven microservices promised to address these issues. In practice we adopted Kafka on Kubernetes, similar to other online retailers .
Our priorities were (1) decoupling services so each team could deploy independently, (2) modeling business events consistently across domains, and (3) ensuring reliable delivery at scale (with retries and DLQs for failures). As a starting point, we documented key domain events (e.g. OrderCreated, PaymentProcessed, InventoryAllocated) and sketched a target architecture. Like other high-traffic systems, we planned horizontal scaling: adding Kafka brokers and topic partitions to match consumer parallelism. We also planned for observability from Day 1 (metrics, logs, traces) to monitor performance and troubleshoot issues.
Architecture After Migration
In the new architecture (Figure 2) each domain publishes events to Kafka and subscribes to the topics it needs. Producers write to topics (e.g. orders.created.v1, inventory.updated.v1, users.registered.v1) and consumers in other services read them. We enforced a domain-driven design: every service owned its data and produced immutable events for other services. There are no synchronous REST calls between most services – all communication is via Kafka. This fully embraces Kafka’s design as a scalable event log with “decoupling effects” . In practice we ran a multi-node Kafka cluster (on Kubernetes) and mapped each service group to relevant topics.
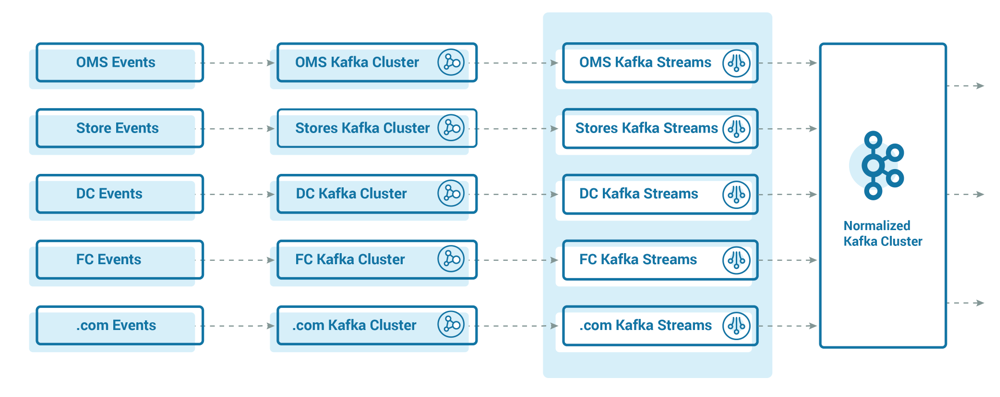
Figure 2: Multi-stage Kafka pipeline example (adapted from Walmart’s inventory system). Events (left) from various sources feed domain-specific Kafka clusters and Kafka Streams applications (center), producing a unified “normalized” stream (right). In our migration we implemented a similar pipeline: e.g. order-management (OMS) events and store-inventory events are published to Kafka, then processed (via Kafka Streams) into consolidated inventory and order summaries. This log-centric design allows independent scaling of each stage .
Kafka’s publish-subscribe model provided two key benefits. First, it decouples services: consumers have no knowledge of producers’ internals. Confluent notes that Kafka “completely decouples services from one another” in event-driven microservices . For instance, after migration the inventory service simply consumes OrderShipped events; it never calls the order service APIs. Second, Kafka acts as a persistent buffer: events are durably stored and replayable, so downstream services can reprocess or recover state if needed. This also enabled us to implement new consumers without impacting producers (a key advantage over tightly-coupled REST APIs).
Partitioning and Throughput
To meet high traffic demands, we scaled Kafka partitions and consumers together. Each topic was partitioned so that many consumers (in the same group) could read in parallel. We followed the rule that the number of consumer threads should roughly equal the number of partitions on each topic. For example, our orders topic initially had 24 partitions; we ran 24 consumers (workers) to maximize throughput. As Redpanda explains, Kafka is built for massive throughput – it can process millions of events per second when tuned properly. We achieved tens of thousands of messages/sec in our tests with small messages and batching.
We tuned producer and broker settings for throughput vs. latency. We adjusted linger.ms and batch.size so producers would accumulate a full batch of records before sending. We chose acks=1 (only leader ack) as a compromise: waiting for all replicas (acks=all) gave stronger durability but higher latency, so for non-critical streams we accepted the leader-only ack. Replication factor was typically 3 for production topics to tolerate broker failure. These tunings followed lessons from large users (e.g. Walmart’s Kafka team). On the consumer side, we monitored consumer lag metrics and added more instances when demand spiked.
Event Modeling and Topics
A rigorous event model was critical. We defined each business event schema (using Avro) and registered it in Confluent Schema Registry to enforce correctness. Topic names followed a clear convention combining domain, event name, and version (e.g. Orders.OrderCreated.v1). Confluent best practices suggest embedding these parts in the name. For example, after a schema change we would release Orders.OrderCreated.v2, leaving v1 in place for backward compatibility. This naming makes it easy for developers to discover and subscribe to relevant streams.
Each event message included a unique event ID and a correlation ID in the header. This ID flows through the system to link together related events and logs. We implemented middleware to automatically propagate the correlation ID from inbound HTTP requests into Kafka records. As one expert notes, correlation IDs are “essential for observability in distributed systems, including asynchronous messaging like Kafka”. By logging this ID in every service, we could trace a single user request end-to-end: from web frontend to order service to payment and shipping services. This greatly simplified debugging.
We also designed events to be idempotent. Consumers used keys (e.g. order ID, user ID) so Kafka’s log compaction could deduplicate if needed. Since Kafka provides at-least-once delivery by default, we made sure processing was safe to repeat (e.g. inserting an order is idempotent if a duplicate offset is reprocessed). In general, the schema-driven approach and clear domain events prevented many errors from occurring in the first place.
Decoupling Services
A major benefit of Kafka was enabling microservices to evolve independently. In the monolith, functionality was entangled; after the migration, each service only knew about its own events. For instance, the inventory service only consumes OrderPlaced and InventoryRequested events; it has no database connection to the orders system. Similarly, the shipping service consumes OrderFulfilled events without contacting billing. This aligns with the “dumb pipes, smart endpoints” principle – Kafka (the pipe) is agnostic, and endpoints enforce business logic.
As a result, teams could release services without coordinating on a central deployment. We also avoided the anti-pattern of using a single consumer group for multiple distinct event types (which would serialize processing and reduce throughput). Instead, each service had its own group or topics. In effect, Kafka acted as an enterprise service bus replacement without the tight coupling – each piece scales and fails in isolation, with Kafka absorbing spikes and outages between them. Confluent captures this advantage: Kafka enables a new class of resilient, event-driven microservices by decoupling service dependencies .
Reliability: Retry Logic and Dead-Letter Queues
Despite careful schema design, some events still failed processing (e.g. due to temporary downstream errors or bad data). We implemented a retry-and-DLQ pattern to handle these robustly. On consuming a message, if a transient error occurred (timeout on an external API, database lock, etc.), the consumer would retry processing with exponential backoff (using in-memory retries or re-polling with delay). After a configurable number of attempts (usually 3), if the error persisted, the event was produced to a Dead-Letter Queue (DLQ) topic for manual intervention. Each DLQ entry included the original payload and metadata (error message, timestamp, originating service). We monitored DLQ topics so that operations teams could review and fix issues without blocking the main stream.
This pattern follows the standard DLQ concept: a Dead Letter Queue in Kafka is simply one or more topics that receive and store messages that could not be processed. Importantly, we adhered to best practices: only truly non-recoverable errors were DLQ’ed. For example, a schema validation error or missing field would go to DLQ immediately, whereas a temporary network glitch would be retried. Kai Waehner advises exactly this: “only push non-retryable error messages to a DLQ – connection issues are the responsibility of the consumer”. Following that guidance, we did not use DLQs to throttle or for ephemeral failures. In fact, using a DLQ for backpressure (e.g. spikes) or for brief network outages is an anti-pattern – Kafka’s commit log and consumer lag handling naturally buffer those cases.
After a message lands in a DLQ, it does halt its own flow, but all other events continue normally. We logged the offset at DLQ entry so consumer groups could advance past the bad message. In practice, sending a record to the DLQ is equivalent to acknowledging it so it won’t be retried again in the main topic. This ensured one “poison-pill” message didn’t block others. The DLQ topics were partitioned by domain (e.g. orders.errors, inventory.errors) rather than one global DLQ, which improved clarity for analysts.
As an additional precaution, we leveraged the Schema Registry to prevent many errors up front. By enforcing all producers to register schemas, invalid payloads were rejected at write time (broker-side schema check), eliminating a class of format-related DLQ entries. Overall, our error-handling strategy made the system robust: transient failures auto-retry, bad records park for manual fixes, and the stream never fully stops due to a single bad event.
Observability and Metrics
We treated observability as a first-class concern. As one source explains, “observability is the ability to measure the internal state of a system by examining its outputs”. In our case that meant logs, metrics, and traces across all services and Kafka itself.
Logging and Tracing: Each service logs key events including errors and processing times, always tagging logs with the correlation ID from the Kafka header. We instrumented services with OpenTelemetry so that spans are collected in Jaeger. This allowed tracing a user session end-to-end through multiple asynchronous hops. The correlation ID is critical – as the author Anil Goyal notes, correlation IDs unify microservices (including Kafka messaging) for observability. For instance, we could query Jaeger for a trace ID and see when an Order event was produced, when it was consumed by billing, and then by shipping, with timing information.
Metrics: We exposed application and Kafka metrics to Prometheus. On the Kafka side, we enabled JMX metrics (via a JMX exporter) to capture broker and topic stats. Important Kafka metrics include BytesInPerSec, BytesOutPerSec, and MessagesInPerSec (tracking incoming/outgoing throughput) , as well as partition count and under-replicated partitions. We built Grafana dashboards to monitor overall load and identify bottlenecks. For example, a sudden rise in consumer lag or pending messages triggered alerts. We also gathered service-level metrics (request rate, processing latency) via Micrometer.
Correlation of Telemetry: To tie everything together, we relied on the OpenTelemetry “three pillars”: metrics, logs, and traces. Prometheus/Grafana give us metrics charts, Jaeger provides trace visualizations, and logs (with correlation ID) allow deep dive. In practice we found the triage approach recommended by observability guides effective: spikes in metrics lead us to check traces or logs for root causes . This holistic visibility was vital during the migration: we could verify that messages were flowing as expected and quickly spot failures or slowdowns in the event pipeline.
Performance and Scaling Results
After migration, the system’s capacity improved dramatically. Kafka’s inherent high throughput meant we could handle peaks of tens of thousands of events per second without backpressure. For comparison, before we were often CPU- or DB-bound; afterwards we hit Kafka limits. As Redpanda’s guide notes, Kafka is engineered for scale, supporting ingestion in the millions of events/sec. In our benchmark of concurrent checkouts, the event pipeline sustained ~50,000 messages/s end-to-end with sub-second latency.
Key to this performance was horizontal scaling. We added Kafka brokers and increased partition counts as load grew. For example, the cart.events topic started with 12 partitions and 3 brokers; after traffic doubled we expanded to 30 partitions across 5 brokers. Consumer groups also scaled: each microservice could scale instances independently to match partition count. This linear scaling property matched expectations: more partitions + more consumers = higher throughput, limited only by network and I/O.
We also learned practical limits: Kafka only parallelizes consumers up to the number of partitions, so super-high fan-out topics needed extra partitions. We monitored disk usage (each partition’s log) and memory. For example, early versions of Kafka required each partition to live on one broker’s disk, so we manually balanced partitions across disks with RAID storage. In newer Kafka versions (2.4+), partitions can span mount points. We tuned server hardware (multiple disks per broker) and Kafka configs (log directories) following Walmart’s lessons.
In summary, after migration the platform’s throughput and resilience met our targets. Kafka’s design meant that adding brokers or consumers increased capacity predictably. We continue to measure metrics like “records per second” and end-to-end latency to ensure SLAs, but the move to pub/sub architecture has successfully accommodated the growth we projected.
Lessons Learned and Best Practices
From this migration, several lessons and trade-offs emerged:
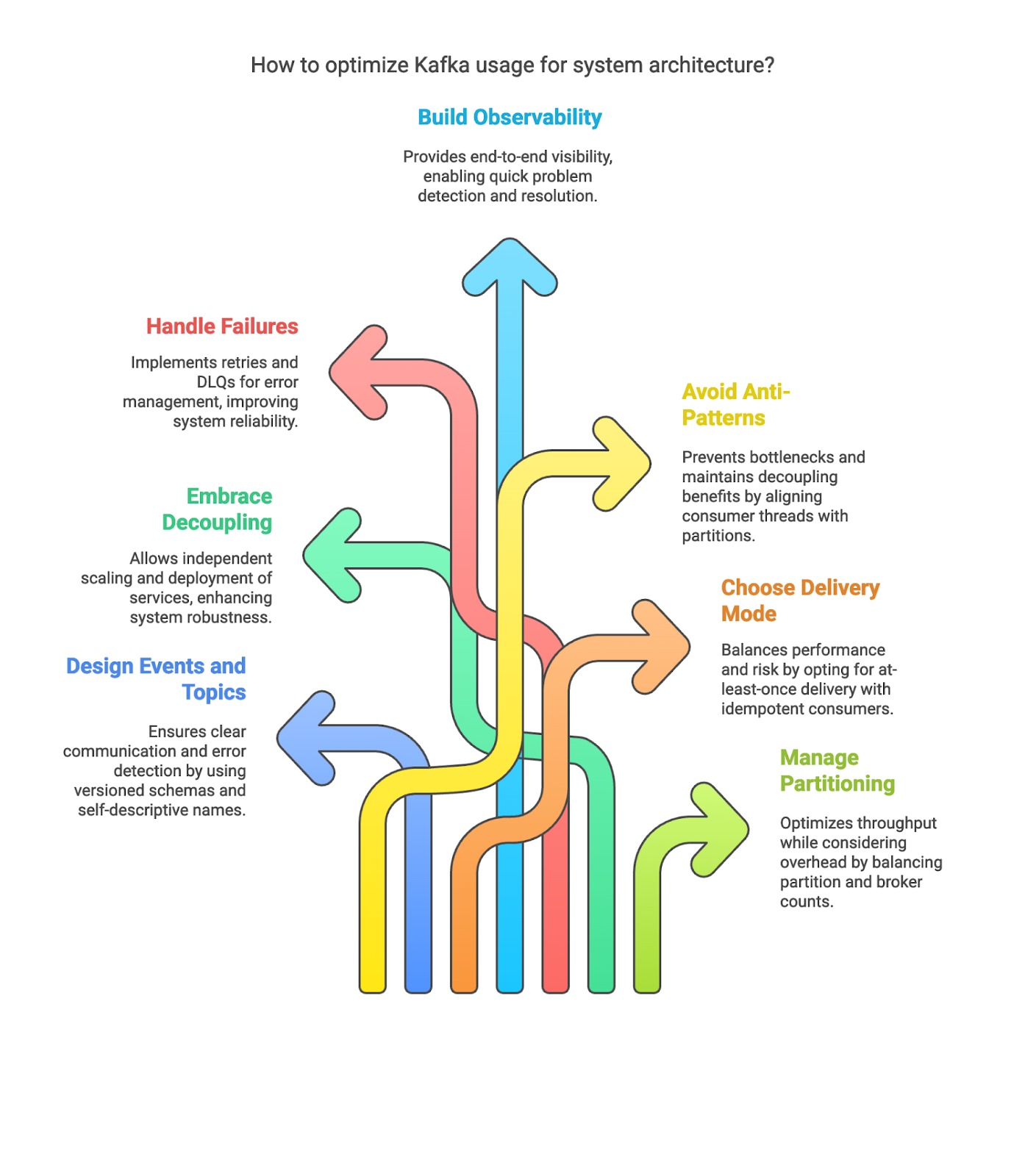
- Design Events and Topics Thoughtfully: Define clear, versioned event schemas and use self-descriptive topic names. We avoided the anti-pattern of a “flat” topic with mixed events. Topics were owned by domains, matching team boundaries. Enforce schemas (e.g. via Schema Registry) to catch errors early.
- Embrace Decoupling: Let Kafka disconnect services. Producers should know nothing about consumer logic. This allowed us to deploy and scale services independently. We followed Kafka’s design goal: decoupling leads to simpler, more robust systems.
- Handle Failures with Retries and DLQs: Implement consumer retries with exponential backoff for transient faults. Use DLQ topics for non-recoverable errors. Include error metadata in the DLQ for traceability. We learned not to use DLQs for backpressure or temporary outages – instead, scale consumers or fix the underlying issue. In practice, keeping the original message and error info in the DLQ was invaluable for debugging.
- Build Observability In: Instrument everything (metrics, logs, traces). We used Prometheus/Grafana and Jaeger, which are industry standards. Correlation IDs in Kafka headers tied together disparate service logs. The ability to observe the system end-to-end proved critical: one can detect and isolate problems in a distributed pipeline only if each component’s health and message flow are visible.
- Watch for Anti-Patterns: Some patterns were pitfalls. For example, processing a Kafka topic with one consumer thread can create a bottleneck; we avoided this by aligning consumer threads with partitions. We also avoided treating Kafka as a synchronous RPC layer – doing so negates its decoupling benefits. Moreover, we never used a single DLQ for all errors, which complicates triage. Using separate error topics per domain made troubleshooting much easier.
- Trade-offs – At-least-once vs. Exactly-once: We chose at-least-once delivery (simpler, higher throughput) and made consumers idempotent, rather than the more expensive exactly-once mode. This decision balanced performance with acceptable risk (duplicate events can be filtered at the application level).
- Partitioning and Concurrency: Adding partitions boosts throughput, but also increases overhead (more file handles, memory usage). We found a practical limit on how many partitions per broker we could handle reliably, so we balanced partition count against broker count. Similarly, we sized consumer thread pools to avoid overloading downstream services.
Conclusion
Migrating our high-traffic e-commerce system to a Kafka-based pub/sub architecture proved transformative. The new design decouples services, enabling independent scaling and faster feature delivery. Event modeling enforced clean interfaces between domains, and robust error handling (with retries and DLQs) made the system resilient to faults. Observability tooling gave us confidence in production. Overall, Kafka delivered on the promises of high throughput and flexibility: we handled order-of-magnitude more events without hitting the limits of our old stack .
This case study echoes others in industry: from Walmart’s 11-billion-event pipelines to countless Kafka deployments in retail, the lessons are consistent. Kafka excels when designed around domain events, with careful schema management and attention to operational concerns. Avoiding anti-patterns (like misusing DLQs or tightly coupling consumers) is critical. In the end, the migration taught us that a well-architected pub/sub system can form the backbone of a robust, cloud-scale e-commerce platform, but only if coupled with diligent design and monitoring .
Lessons Learned and Best Practices (Summary):
- Use clear event schemas and naming (e.g. Domain.Event.v1) to version and discover data streams .
- Decouple services via Kafka; let each service subscribe to only what it needs . Avoid synchronous calls.
- Implement retries + DLQs carefully: retry transient errors and send truly invalid records to a DLQ topic (with error details) . Do not use DLQs for normal load spikes or temporary outages .
- Prioritize observability: propagate correlation IDs and use tools (Jaeger, Prometheus/Grafana) to trace messages and monitor system health .
- Scale thoughtfully: match consumer instances to partitions, tune producer batch settings, and monitor throughput metrics (e.g. BytesInPerSec, MessagesInPerSec) to guide scaling .
- Watch out for anti-patterns: e.g. don’t funnel unrelated data into one topic or DLQ, and don’t assume ordering guarantees across partitions if your data needs it.
By following these guidelines and learning from real-world case studies, engineers can successfully migrate monolithic systems to Kafka-driven architectures at production scale, reaping the benefits of agility and performance in the process .
Opinions expressed by DZone contributors are their own.
Comments