Stop Leap-Second AI Drift in IoT Streams With PySpark
Leap seconds can corrupt timestamps and trigger AI drift in fintech IoT systems. Learn about drift types and how PySpark streaming fixes them in real time.
Join the DZone community and get the full member experience.
Join For FreeFintech and Enterprise platforms ingest massive volumes of timestamped data (big data) from IoT devices such as payment terminals, wearables, and mobile apps. Accurate timing is essential for fraud detection, risk scoring, and customer analytics. Yet a subtle irregularity called the leap second can corrupt timestamps and trigger AI drift, gradually degrading model performance in production.
In this article, I will attempt to explain clearly what drift types are and how they can be prevented, based on my research paper. Details can be found here. Let's start.
What Is AI Drift?
AI drift (also known as model drift) occurs when a deployed machine learning model loses accuracy because live data no longer matches the training data distribution. In fintech IoT pipelines, this leads to more false-positive fraud alerts, inaccurate risk scores, and lost revenue.
Four key types of drift are relevant:
1. Data Drift (Covariate Shift)
The statistical distribution of input features changes while the relationship to the target stays the same.
Fintech example: A fraud model trained on average transaction amounts of $50–$200 suddenly sees many $1–$10 micro-payments from new IoT wearables. The feature distribution shifts, causing excessive false positives.
2. Concept Drift
The underlying relationship between inputs and the target evolves.
Fintech example: Fraudsters switch from large one-time charges to repeated small "card-testing" transactions across IoT devices. The model’s learned fraud patterns become outdated.
3. Label Drift (Prior Probability Shift)
The overall proportion of target classes changes.
Fintech example: During economic stability, the fraud rate drops from 2% to 0.2%. A model calibrated on the old rate over-predicts fraud and floods teams with alerts.
4. Temporal Drift
Timestamp inconsistencies corrupt time-based features (often grouped under data drift).
Fintech example: Leap seconds create duplicate timestamps or negative deltas. Features such as "seconds since last transaction" or velocity checks break, distorting every downstream score.
These drift types frequently compound. Temporal drift from leap seconds can cascade into data, concept, or label drift if timestamps are not cleaned in real time.
Verified Historical Leap-Second Incidents
- 2012 (June 30): Reddit, LinkedIn, and other major services suffered outages. A Linux kernel timing bug caused 100% CPU spikes and lockups when the extra second was inserted.
- 2015 (June 30): Major exchanges took precautionary measures. The Intercontinental Exchange (ICE), which operates NYSE platforms, paused certain operations for 61 minutes, and other venues shortened after-hours sessions to avoid timestamp-related failures.
- 2017 (January 1): Cloudflare experienced a partial global DNS outage. A negative time delta in their Go-based resolver caused a random-number generator to panic and crash.
These documented events show why real-time leap-second handling is essential in financial systems.
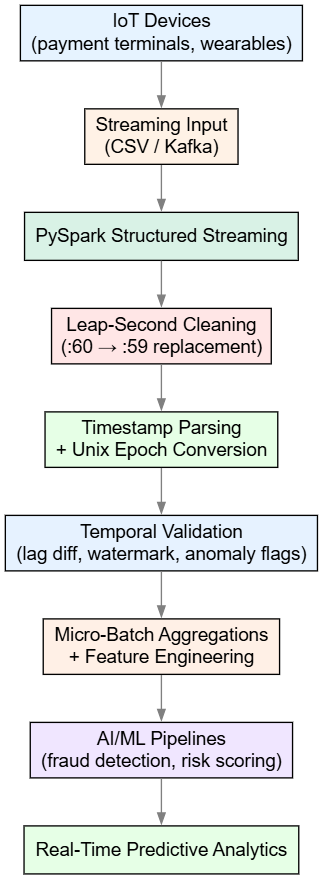
The Solution: PySpark Structured Streaming Pipeline
The framework published in the original research uses Apache Spark Structured Streaming to detect and correct leap-second anomalies in real time, enforce temporal order, and deliver clean monotonic timestamps to AI/ML pipelines.
Complete PySpark Implementation
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, DoubleType
from pyspark.sql.window import Window
import os
# Initialize Spark session
spark = SparkSession.builder \
.appName("LeapSecondsStreaming") \
.master("local[*]") \
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
# Create input directory for streaming files
input_dir = "input_data"
os.makedirs(input_dir, exist_ok=True)
# Define input schema
schema = StructType([
StructField("transaction_id", StringType(), True),
StructField("timestamp", StringType(), True), # format: yyyy-MM-dd HH:mm:ss
StructField("amount", DoubleType(), True)
])
# Read streaming CSV data (easily replaceable with Kafka)
raw_df = spark.readStream \
.schema(schema) \
.option("header", True) \
.option("maxFilesPerTrigger", 1) \
.csv(input_dir)
# Leap-Second Cleaning
cleaned_df = raw_df.withColumn(
"cleaned_ts", regexp_replace(col("timestamp"), r":60$", ":59")
)
# Parse timestamps and convert to Unix epoch
parsed_df = cleaned_df \
.withColumn("event_time", to_timestamp(col("cleaned_ts"), "yyyy-MM-dd HH:mm:ss")) \
.withColumn("unix_ts", unix_timestamp(col("event_time"))) \
.filter(col("event_time").isNotNull())
# Real-time Temporal Validation in Micro-batches
def process_batch(df, epoch_id):
print(f"\n=== Processing micro-batch {epoch_id} ===")
window_spec = Window.orderBy("event_time")
df = df.withColumn("prev_unix_ts", lag("unix_ts").over(window_spec)) \
.withColumn("time_diff_sec", col("unix_ts") - col("prev_unix_ts")) \
.withColumn("anomaly_flag",
when((col("time_diff_sec") == 0) |
(col("time_diff_sec") > 2) |
col("time_diff_sec").isNull(), "LEAP_SECOND_OR_GAP")
.otherwise("OK"))
df.select("transaction_id", "event_time", "amount",
"time_diff_sec", "anomaly_flag") \
.orderBy("event_time") \
.show(truncate=False)
# Write cleaned data to Delta Lake / feature store here
# Start the streaming query
query = parsed_df.writeStream \
.foreachBatch(process_batch) \
.outputMode("append") \
.option("checkpointLocation", "checkpoint_leapsecond") \
.start()
query.awaitTermination()PySpark Logic Explanation
The PySpark Structured Streaming pipeline processes fintech IoT data in real time by first initializing a SparkSession and reading incoming CSV files (or Kafka topics) as a continuous streaming DataFrame using a predefined schema for transaction_id, timestamp, and amount. The leap-second correction is applied immediately via regexp_replace to convert any invalid :60 second to :59, followed by to_timestamp parsing and conversion to Unix epoch seconds (unix_timestamp) for numerical stability.
In every micro-batch processed by foreachBatch, a window function ordered by event_time computes the previous timestamp using lag and derives the time_diff_sec; any zero-difference, null, or excessively large gap is flagged as a leap-second anomaly with an anomaly_flag column. Cleaned, monotonic timestamps and validated time differences are then passed downstream for aggregations and feature engineering, ensuring temporal consistency before data reaches AI/ML pipelines.
Why This Matters for All Types of Drift
The leap-second cleaning and temporal validation steps directly eliminate temporal drift — the root cause in fintech IoT streams. By making timestamps monotonic and gap-free, the pipeline ensures that all derived features (time deltas, velocity checks, rolling windows, and event ordering) remain accurate. This single fix prevents temporal drift from cascading into the other 3 drift types.
This pipeline achieved 100% detection and correction of injected leap-second anomalies in the paper’s controlled experiment (1,000 synthetic transactions with 10 anomalies) at an average batch latency of only 0.8 seconds.
How the Pipeline Prevents All Types of Drift
- Data drift is eliminated by producing consistent Unix epoch timestamps and valid time deltas.
- Concept drift is avoided because accurate temporal sequences preserve true fraud and risk patterns.
- Label drift is controlled by reliable time windows that do not artificially inflate or deflate class balances.
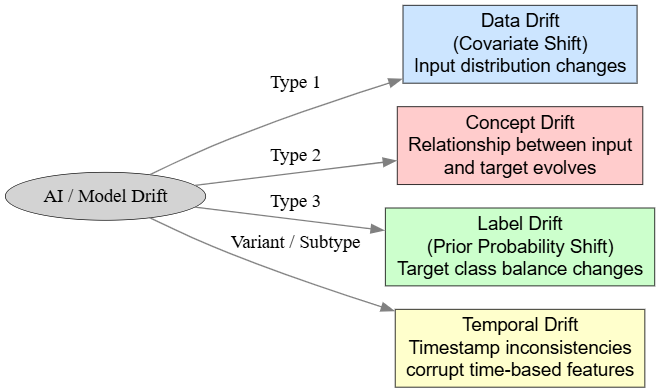
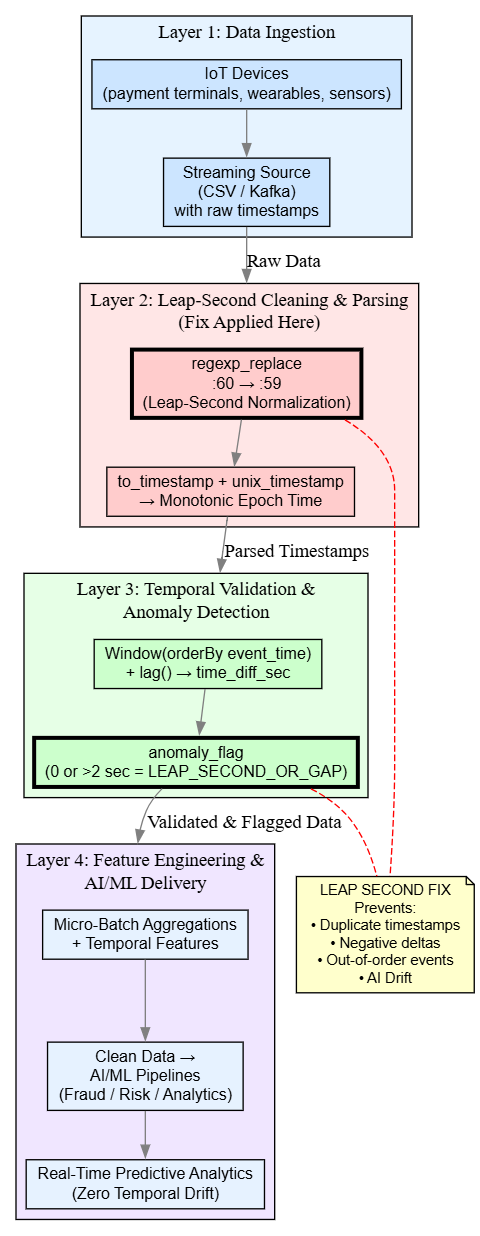
Figure 3. Complete Layered PySpark Architecture – How Leap-Second Anomalies Are Detected and Fixed
Conclusion
Handling temporal anomalies such as leap seconds is often overlooked in large-scale data systems, yet it plays a critical role in ensuring the reliability of time-sensitive applications, especially in fintech and IoT environments. By leveraging PySpark and designing resilient data pipelines, organizations can proactively mitigate AI drift and maintain the integrity of predictive models operating at scale.
As real-world data continues to grow in complexity, engineering systems that are both time-aware and fault-tolerant become essential. The approaches discussed here provide a foundation for building robust, production-grade data processing systems that can handle such edge cases effectively.
References
[1] Ram Ghadiyaram, Durga Krishnamoorthy, Vamshidhar Morusu, Jaya Eripilla, "Addressing AI Drift in Fintech IoT Data Processing: Handling Leap Seconds with PySpark for Robust Predictive Analytics," International Journal of Computer Trends and Technology, vol. 73, no. 5, 2025. https://doi.org/10.14445/22312803/IJCTT-V73I5P101
Opinions expressed by DZone contributors are their own.
Comments