AI-Powered Knowledge: LlamaIndex and Apache Tika for Enterprises
LlamaIndex leverages Apache Tika to extract data from legacy Word .doc files, helping businesses unlock decades-old content for modern AI tasks like search and analysis.
Join the DZone community and get the full member experience.
Join For FreeLlamaIndex is an open-source Python framework that’s like an intelligent librarian for your data, supercharging AI with your documents. It’s built for retrieval-augmented generation (RAG), where AI searches your files, databases, or records to find the right info before answering questions or generating content. This makes AI answers more accurate, unlike generic chatbots that lean on pre-trained knowledge.
LlamaIndex works in three steps:
- Loading data (reading files like PDFs or Word docs)
- Indexing it (organizing it like a library catalog)
- Querying it (letting AI search the catalog for answers). It’s user-friendly, versatile, and handles all sorts of data, making it a top pick for developers crafting AI-driven apps.
Uses of LlamaIndex
LlamaIndex shines wherever AI needs to tap into your data. Here are key uses:
- Enterprise search: Companies create AI search tools to scan documents or emails, answering questions like “What’s our vacation policy?” or “Find the latest budget report.”
- Customer support: Businesses build chatbots that pull answers from manuals or FAQs, delivering fast, accurate help.
- Data analysis: Analysts use LlamaIndex to summarize reports, extract research insights, or compare data across files.
- Knowledge management: Organizations index old records or technical documents, keeping vital knowledge accessible to AI.
For example, a law firm could index case files, letting AI spot legal precedents in seconds. A manufacturer might analyze old production logs to boost efficiency. LlamaIndex makes these tasks seamless and powerful.
LlamaIndex Architecture and Tika Integration
To understand how LlamaIndex works with Apache Tika, check out its architecture:
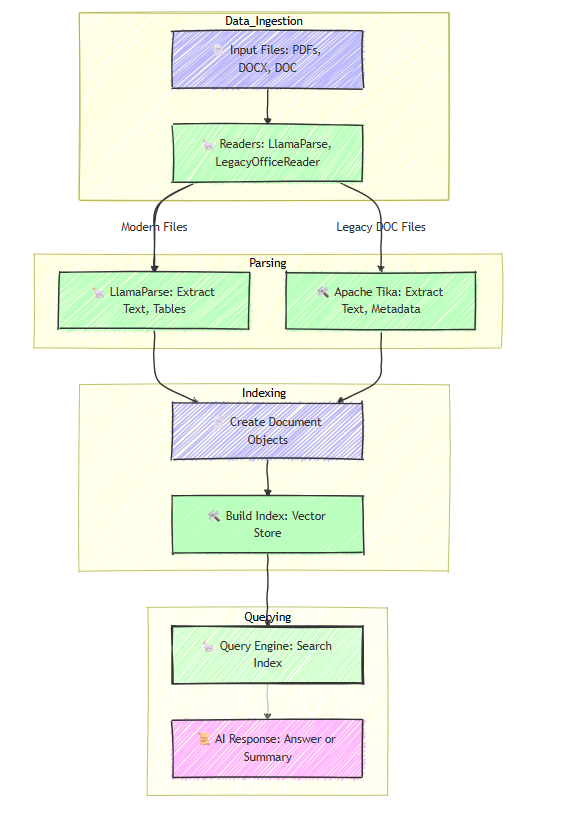
This diagram shows Tika in the parsing step, handling legacy .doc files that LlamaParse can’t, making LlamaIndex a complete solution for all file types.
Introducing Apache Tika
Apache Tika is an open-source tool that’s like a universal translator for files. It reads over 1,000 file types, from PDFs to old Microsoft Word .doc files from 1997-2003, extracting text and details like the author or creation date. Maintained by the Apache Software Foundation, Tika is a developer’s go-to for pulling data from tough formats, especially legacy files using the complex OLE2 structure [3].
Think of Tika as a librarian who can crack open any book, no matter how ancient, and summarize its contents. In LlamaIndex, Tika tackles .doc files that modern tools can’t handle, making them AI-ready. Its ability to grab text and metadata (like titles or dates) enriches the data, helping AI give better answers. Tika’s open-source roots keep it free and ever-improving, making it a perfect match for LlamaIndex.
Apache Tika’s Architecture
Tika’s strength lies in its clever design, shown below:
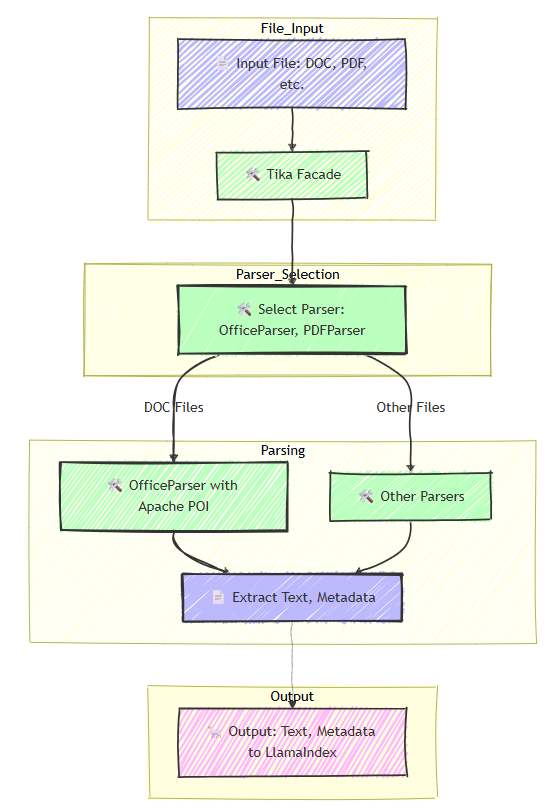
Imagine Tika as a librarian who gets a book (Input File) and decides how to read it (Tika Facade). They choose the right assistant, like a specialist for old Word files (OfficeParser) or other file types (Parser Selection). The assistant pulls out the story and notes like the author’s name (Parsing). The librarian hands this summary to LlamaIndex (Output) for AI to use. For .doc files, Tika uses a tool called Apache POI to decode the tricky format, capturing every detail.
This design makes Tika versatile and powerful, handling any file type with ease [3].
Tika in LlamaIndex: The Legacy Document Key
In LlamaIndex, Tika powers the LegacyOfficeReader, a module added in early 2025, as shared by contributor Wey Gu [1]. Found in the LlamaIndex GitHub under llama_index/readers/file/legacy_office/ [2], this module processes .doc files like this:
- You feed LlamaIndex a .doc file.
- The LegacyOfficeReader sends it to Tika, which runs on a small Java program.
- Tika extracts the text and details, like the file’s title or creation date.
- LlamaIndex stores this in a format AI can search.
Here’s a snippet of the code [2]:
from tika import parser
from llama_index.core.readers.base import BaseReader
from llama_index.core.schema import Document
class LegacyOfficeReader(BaseReader):
def load_data(self, file_path: str) -> List[Document]:
parsed = parser.from_file(file_path)
text = parsed.get("content", "")
metadata = parsed.get("metadata", {})
return [Document(text=text, metadata=metadata)]Tika is optional, so you only need it for old files, keeping LlamaIndex lightweight. It’s like calling in a vintage book expert only when you need to read an ancient manuscript.
Real-World Impact Examples
The Tika-LlamaIndex integration is impactful across all industries by integrating and leveraging diverse datasets. Here are some impactful examples:
- Legal firms: Quickly identify precedents by indexing years-old .doc case files alongside recent legal documents. Accelerate legal research by querying indexed contracts, court rulings, and memos.
- Manufacturing: Analyze decades of production logs to identify inefficiencies and optimize workflows. Monitor maintenance records and identify patterns that predict equipment failure, reducing downtime.
- Healthcare: Organize and index legacy patient records and modern digital health files for faster diagnoses and treatment planning. Summarize medical research papers to assist doctors in staying updated on new treatments.
- Education: Universities can index legacy academic and research papers, dissertations, and research documents for AI-driven academic searches. Create AI-assisted study tools that draw from syllabi, past lectures, and textbooks.
- Finance: Analyze historical financial statements, legacy agreements, or policy documents to identify trends or compliance risks. Enable AI-powered search across internal databases for quick access to policy updates or customer inquiries.
- Retail and E-commerce: Index and query years of sales reports, inventory logs, and supplier contracts to streamline operations. Use AI to analyze customer feedback or social media data to improve product offerings.
- Government and public sector: Digitize and index legacy records like census data or municipal documents for quick AI-driven searches. Assist policymakers by providing insights from historical data and reports.
- Media and publishing: Index archived newspapers, manuscripts, and articles, enabling journalists and researchers to access historical context efficiently. Summarize lengthy reports or books for quick review.
- Energy and utilities: Organize data from decades-old project files, environmental reports, and technical specs to optimize energy output. Enable AI to identify potential risks in legacy compliance documents or operational data.
- Startups and SMEs: Integrate old and new files without a heavy technical lift, allowing small teams to access vital insights quickly. Use AI to identify customer trends from feedback stored across legacy and current formats.
Conclusion
LlamaIndex is your AI-powered bridge to smarter data, organizing everything for easy access. From enabling cutting-edge insights to preserving institutional knowledge, Tika and LlamaIndex empower organizations to unlock the full potential of their data.
With Apache Tika, it reaches back to old .doc files, unlocking decades of knowledge for modern AI apps. Whether you’re a law firm, factory, or startup, this duo helps you maximize every file, driving sharper decisions and bigger wins. As AI reshapes business, LlamaIndex and Tika are your keys to leading the way, turning every document into a tool for success.
Happy AI learning. :-)
References
Opinions expressed by DZone contributors are their own.
Comments