Evaluating the Evaluators: Building Reliable LLM-as-a-Judge Systems
LLMs are changing how we evaluate information faster, smarter, and more consistent. This article shows you how they work, where they help, and why we need to use them.
Join the DZone community and get the full member experience.
Join For FreeThe emergence of Large Language Models (LLMs) as evaluators, termed “LLM-as-a-Judge,” represents a significant advancement in the field of artificial intelligence. Traditionally, evaluation tasks have relied on human judgment or automated metrics, each with distinct strengths and limitations, you must have seen this while working with traditional ML models. Now, LLMs offer a compelling alternative, combining the nuanced reasoning of human evaluators with the scalability and consistency of automated tools. However, building reliable LLM-as-a-Judge systems requires addressing key challenges related to reliability, biases, and scalability.
Why LLM-as-a-Judge?
Evaluation tasks often involve assessing the quality, relevance, or accuracy of outputs, such as grading academic submissions, reviewing creative content, or ranking search results. Historically, human evaluators have been the gold standard due to their contextual understanding and holistic reasoning. However, human evaluations are time-consuming, costly, and prone to inconsistencies.
On the other hand, traditional automated metrics like BLEU or ROUGE provide scalability and consistency but often fail to capture deeper nuances such as creativity, coherence, or human-like reasoning. LLMs bridge this gap, offering:
- Scalability: LLMs can process vast amounts of data quickly and consistently.
- Flexibility: They can adapt to diverse domains and handle multimodal inputs with fine-tuning.
- Contextual Reasoning: LLMs leverage in-context learning to provide nuanced judgments.
Core Components of LLM-as-a-Judge Systems
Building a reliable LLM-as-a-Judge system involves several key components:
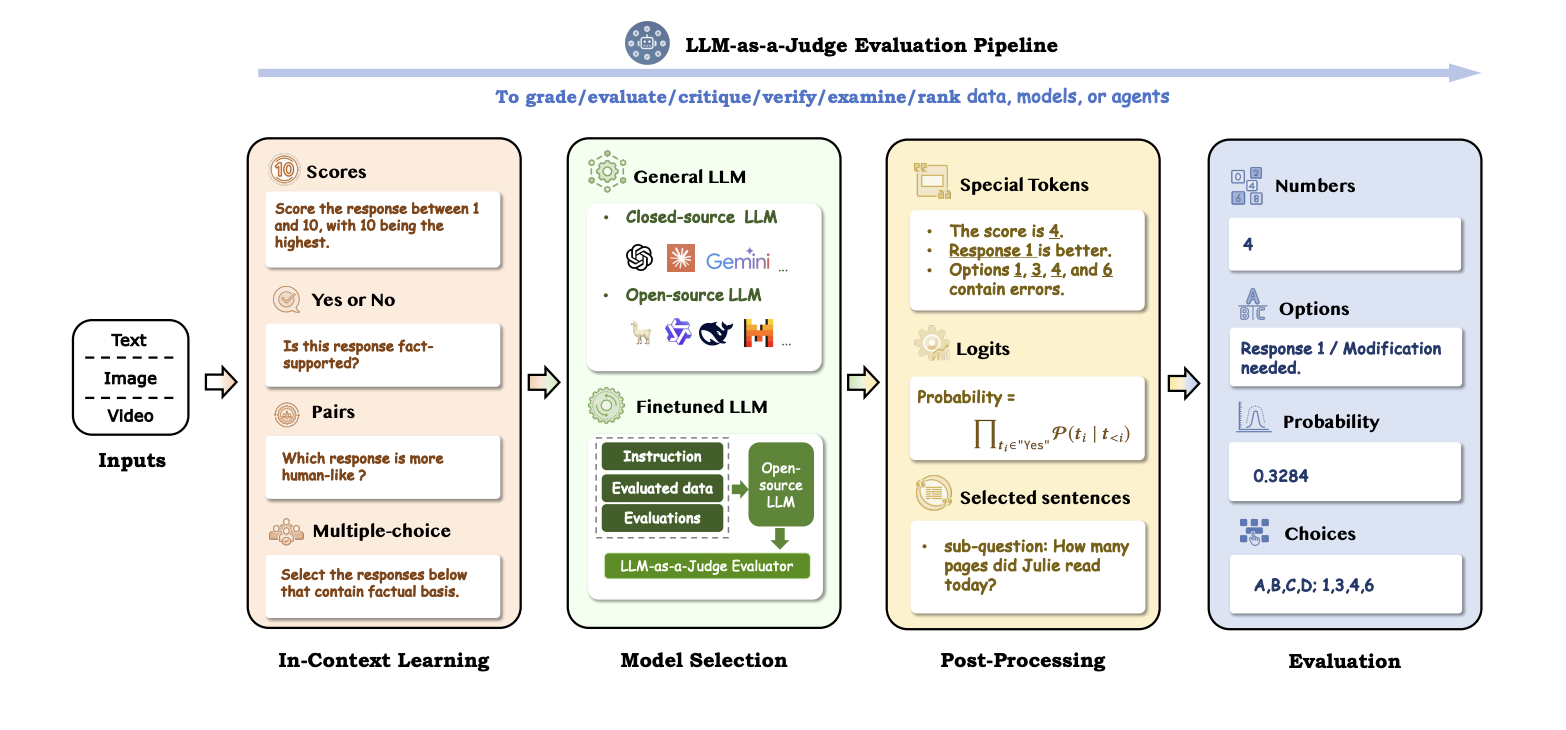
In-Context Learning
In-context learning enables LLMs to perform evaluation tasks without requiring extensive retraining. Instead, they rely on well-designed prompts and examples to guide their reasoning. Common techniques include:
Prompt Design: Crafting clear, structured instructions for tasks like scoring, pairwise comparisons, or multiple-choice selection.
Few-Shot Examples: Providing high-quality examples within the prompt to enhance understanding.
Evaluation Criteria Decomposition: Breaking down complex tasks into smaller, more manageable sub-tasks, such as assessing grammar, coherence, and factuality individually.
Model Selection
The choice of model significantly impacts the performance of an LLM-as-a-Judge system. Options range from general-purpose models like GPT-4 to domain-specific, fine-tuned models. While general models offer versatility, fine-tuned models tailored to specific evaluation tasks provide higher accuracy and alignment with human preferences.
Post-Processing
Post-processing refines the outputs generated by LLMs, ensuring consistency and reliability. Techniques that may include:
Token Extraction: Identifying specific elements in responses, such as scores or labels.
Logit Normalization: Converting probabilities into interpretable metrics for tasks like binary classification.
Structured Outputs: Formatting responses into structured forms (e.g., JSON) to facilitate automation and downstream processing.
Evaluation
The final component of the pipeline is evaluation, where model outputs are interpreted and formatted for decision-making or feedback. Key mechanisms include:
Numerical Scoring: Assigning a numerical value (e.g., 1–10) based on response quality.
Multiple Choice/Options: Selecting the most accurate or appropriate response among several choices.
Probabilistic Confidence: Providing a confidence score to indicate the certainty of the model’s evaluation.
Discrete Judgments: Labeling or categorizing responses based on predefined criteria, such as factual correctness or human-likeness.
These outputs enable downstream applications like grading, ranking, and feedback generation, ensuring LLM assessments are both interpretable and actionable.
Challenges in LLM-as-a-Judge Systems
Despite their potential, LLM-as-a-Judge systems face several challenges:
Bias
LLMs can inherit biases from training data, affecting their judgments. Common biases include:
Position Bias: Preferring responses based on their position within a prompt.
Length Bias: Favoring verbose answers irrespective of content quality.
Cultural and Demographic Bias: Reflecting stereotypes present in the training data.
Reliability and Robustness
LLMs may exhibit inconsistencies or vulnerabilities to adversarial inputs. For instance, subtle changes in prompts or the introduction of misleading phrases can alter their evaluations significantly.
Ethical and Interpretability Concerns
As LLMs take on evaluative roles, ensuring transparency and accountability becomes critical. Users must understand the rationale behind their decisions, especially in high-stakes scenarios such as legal judgments or academic grading.
Improvement Strategies
Researchers and practitioners are actively developing strategies to address these challenges:
Enhancing Prompt Design
Optimizing prompts through step-by-step instructions, criteria decomposition, and examples can improve LLM understanding and reduce biases. Techniques like content shuffling mitigate position biases by randomizing input sequences.
Fine-Tuning Models
Fine-tuning LLMs on domain-specific datasets enhances their performance for specialized tasks. For instance, models can be trained using pairwise comparisons or expert annotations to align closer with human judgment.
Feedback Loops and Iterative Optimization
Incorporating feedback mechanisms enables LLMs to improve over time. For example, iterative fine-tuning based on discrepancies between human and model evaluations helps refine outputs.
Multi-Model Integration
Combining evaluations from multiple LLMs can enhance reliability. By integrating diverse perspectives, organizations can minimize individual model biases and achieve more balanced judgments.
Metrics Used in LLM-as-a-Judge Evaluation
LLM-as-a-Judge systems rely on a variety of metrics to assess their reliability, fairness, and alignment with human judgment. These metrics are tailored to ensure that the evaluations performed by LLMs meet high standards of consistency and effectiveness. Here's a concise overview of key metrics discussed in the context of LLM-as-a-Judge:
Agreement Metrics
Percentage Agreement: Measures the proportion of cases where LLM evaluations match human judgments. It's a direct measure of alignment with human annotators.
Cohen’s Kappa and Spearman’s Correlation: Evaluate the consistency of LLM judgments with human evaluators across a dataset.
Bias Detection Metrics
Position Bias: Quantifies whether an LLM prefers responses based on their placement within a prompt. Metrics like Position Consistency and Preference Fairness are used to measure this bias.
Length Bias: Detects whether the LLM disproportionately favors longer or more verbose responses, which may not always equate to better quality.
Other Biases: Includes demographic biases (gender, race, etc.), concreteness bias (favoring detailed responses), and sentiment bias (favoring certain emotional tones).
Robustness Metrics
Adversarial Robustness: Tests the LLM’s resilience to crafted inputs designed to manipulate evaluation outcomes. For example, inserting irrelevant but authoritative-sounding phrases to boost scores.
Self-Enhancement Bias: Checks whether an LLM evaluator tends to favor outputs generated by itself or a similar model.
Evaluation Pipeline Metrics
Token-Based Extraction: Evaluates the reliability of extracting specific answers or scores from the LLM’s output using predefined rules.
Normalized Logit Scores: Converts token probabilities into interpretable metrics for continuous or binary classification tasks.
Structured Outputs: Assesses how well LLMs adhere to specified output formats like JSON or tabular structures for easier downstream processing.
Benchmark Datasets
Datasets like MTBench, LLMEval2, and EvalBiasBench provide a foundation for systematically evaluating LLM-as-a-Judge performance. These benchmarks include tasks like pairwise comparisons, scoring, and alignment with human annotations across multiple domains.
Applications of LLM-as-a-Judge
The versatility of LLMs as evaluators opens up numerous applications across industries:
The concept of Large Language Models (LLMs) as evaluators, or “LLM-as-a-Judge,” opens up a wide range of applications across industries and domains. Beyond commonly cited examples like content moderation and academic peer review, here are additional areas where LLMs as judges can add value:
Legal and Compliance Reviews
Contract Analysis: Evaluating contracts for compliance with legal requirements, flagging ambiguities, or identifying potential risks.
Regulatory Compliance: Assessing business practices or documentation against regulations, such as GDPR or HIPAA, to ensure adherence.
Case Law Summarization: Judging the relevance and quality of case law summaries to support legal professionals.
Financial Decision-Making
Loan Risk Assessment: Analyzing borrower profiles, credit histories, and application documents to evaluate loan approval risks.
Fraud Detection: Reviewing transactions or financial reports to flag suspicious activities.
Investment Analysis: Evaluating the quality of investment proposals or market predictions for alignment with financial goals.
Healthcare
Medical Diagnosis: Reviewing diagnostic models or medical responses for accuracy, relevance, and adherence to clinical guidelines.
Drug Discovery and Research: Judging the validity and quality of research outputs in pharmaceutical development.
Patient Communication: Evaluating automated responses in telemedicine systems for clarity, empathy, and accuracy.
Hiring and Talent Management
Resume Screening: Assessing resumes or cover letters for alignment with job descriptions, reducing recruiter workloads.
Candidate Interview Evaluation: Judging candidate responses in virtual interviews to identify the best-fit talent.
Performance Reviews: Evaluating employee contributions using predefined criteria for more consistent and objective appraisals.
Creative and Content Industries
Content Quality Assessment: Judging articles, blogs, or creative content for originality, coherence, and audience relevance.
Game Design and Testing: Reviewing game narratives, character development, or functionality based on user experience criteria.
Artwork and Design Feedback: Assessing visual or graphic content for adherence to artistic briefs or market trends.
Education and Learning
Curriculum Evaluation: Judging the quality and relevance of course materials or syllabi.
Automated Tutoring Systems: Evaluating the effectiveness of AI tutors in explaining concepts or answering student queries.
Standardized Test Grading: Scoring open-ended answers in large-scale exams consistently and efficiently.
Marketing and Advertising
Ad Copy Evaluation: Judging ad campaigns or slogans for creativity, impact, and alignment with target audiences.
Sentiment Analysis: Evaluating the tone and effectiveness of marketing materials in generating positive audience sentiment.
Data Annotation
Labeling for ML Models: Automating the annotation of datasets, such as tagging images, summarizing texts, or categorizing data.
Quality Control in Annotation: Evaluating human annotations for consistency and correctness in large-scale datasets.
Ethical AI Oversight
Bias Detection: Reviewing outputs from AI systems for signs of bias or discriminatory behavior.
Policy Adherence: Evaluating whether AI systems comply with ethical guidelines or organizational principles.
Scientific Research
Peer Review Assistance: Helping journal editors evaluate research papers for coherence, originality, and adherence to standards.
Hypothesis Validation: Assessing the plausibility and rigor of hypotheses in experimental designs.
Dataset Evaluation: Judging the quality and relevance of datasets for specific research applications.
Supply Chain Management
Vendor Evaluation: Assessing supplier performance based on criteria like delivery timelines, quality, and adherence to contracts.
Inventory Analysis: Evaluating stock levels and predicting replenishment needs based on historical data.
Conclusion
As LLMs evolve from content generators to capable evaluators, the concept of “LLM-as-a-Judge” offers a compelling new direction for scalable, consistent, and context-aware assessment across industries. These systems hold the promise of augmenting human judgment, streamlining evaluations in areas as diverse as education, compliance, healthcare, and creative review.
But this promise is not without its challenges. Bias, transparency, and robustness remain critical concerns that must be addressed with rigor and responsibility. Success lies not just in deploying these systems, but in designing them thoughtfully, anchored in sound evaluation practices, ethical safeguards, and continuous feedback loops.
Ultimately, LLM-as-a-Judge is not just a technical milestone, it’s a call to reimagine how we assess value, quality, and truth in an AI-enabled world. The opportunity is here. The responsibility is ours.
Disclaimer: The views presented in this article are the views of the author and do not necessarily reflect the views of the global EY organization or its member firms.
Opinions expressed by DZone contributors are their own.
Comments