Local and Distributed Graph Traversal Engines
Join the DZone community and get the full member experience.
Join For Free
in the
graph database
space, there are two types of traversal engines: local and distributed.
local traversal engines
are typically for single-machine graph databases and are used for real-time production applications.
distributed traversal engines
are typically for multi-machine graph databases and are used for batch
processing applications. this divide is quite sharp in the community,
but there is nothing that prevents the unification of both models. a
discussion of this divide and its unification is presented in this post.
local traversal engines
in a local traversal engine, there is typically a single processing agent that obeys a program. the agent is called a traverser and the program it follows is called a path description . in gremlin , a friend-of-a-friend path description is defined as such:
g.v(1).oute('friend').inv.oute('friend').inv
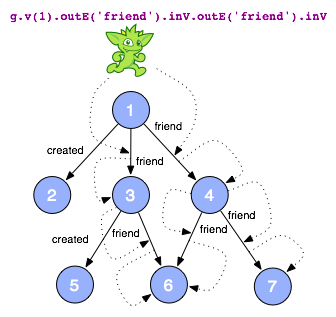 when this path description is interpreted by a traverser over a graph,
an instance of the description is realized as actual paths in the graph
that match that description. for example, the gremlin traverser starts
at vertex 1 and then steps to its outgoing
friend
-edges. next, it will move to the head/target vertices of those edges (i.e. vertices 3 and 4). after that, it will go to the
friend
-edges
of those vertices and finally, to the head of the previous edges (i.e.
vertices 6 and 7). in this way, a single traverser is following all the
paths that are exposed with each new atomic graph operation (i.e. each
new step after a .). the abstract syntax being:
step.step.step
. what is returned by this friend-of-a-friend path description, on the example graph diagrammed, is vertices 6 and 7.
when this path description is interpreted by a traverser over a graph,
an instance of the description is realized as actual paths in the graph
that match that description. for example, the gremlin traverser starts
at vertex 1 and then steps to its outgoing
friend
-edges. next, it will move to the head/target vertices of those edges (i.e. vertices 3 and 4). after that, it will go to the
friend
-edges
of those vertices and finally, to the head of the previous edges (i.e.
vertices 6 and 7). in this way, a single traverser is following all the
paths that are exposed with each new atomic graph operation (i.e. each
new step after a .). the abstract syntax being:
step.step.step
. what is returned by this friend-of-a-friend path description, on the example graph diagrammed, is vertices 6 and 7.
in many situations, its not the end of the path that is desired, but some side-effect of the traversal. for example, as the traverser walks it can update some global data structure such as a ranking of the vertices. this idea is presented in the path description below, where the oute.inv path is looped over 1000 times. each time a vertex is traversed over, the map m is updated. this global map m maintains keys that are vertices and values that denote the number of times that each vertex has been touched ( groupcount ‘s behavior).
m = [:]
g.v(1).oute.inv.groupcount(m).loop(3){it.loops < 1000}
the local traversal engine pattern is abstractly diagrammed on the right, where a single traverser is obeying some path description ( a.b.c ) and in doing so, moving around on a graph and updating a global data structure (the red boxed map).
given the need for traversers to move from element to element, graph
databases of this form tend to support strong data locality by means of a
direct-reference graph data structure (i.e. vertices have pointers to
edges and edges to vertices). a few examples of such graph databases
include
neo4j
,
orientdb
, and
dex
.
distributed traversal engines
in a distributed traversal engine, a traversal is represented as a flow of messages between the elements of the graph. generally, each element (e.g. vertex) is operating independently of the other elements. each element is seen as its own processor with its own (usually homogenous) program to execute. elements communicate with each other via message passing . when no more messages have been passed, the traversal is complete and the results of the traversal are typically represented as a distributed data structure over the elements. graph databases of this nature tend to use the bulk synchronous parallel model of distributed computing. each step is synchronized in a manner analogous to a clock cycle in hardware. instances of this model include agrapa , pregel , trinity , and goldenorb .
an example of distributed graph traversing is now presented using a ranking algorithm in java. [ note : in this example, edges are not first class citizens. this is typical of the state of the art in distributed traversal engines. they tend to be for single-relational, unlabeled-edge graphs.]
public void evaluatestep(int step) {
if(!this.inbox.isempty() && step < 1000) {
this.rank = this.rank + this.inbox.size();
for(vertex vertex : this.adjacentvertices()) {
for(int i=0; i<this.inbox.size(); i++) {
this.sendmessage(vertex);
}
}
this.inbox.clear();
}
}
each vertex is provided the above piece of code. this code is executed by every vertex at each step (in the bulk synchronous parallel sense — “clock cycle”). for a concrete example, a “start message” to, lets say, vertex 1 initiates the process. vertex 1 will increment its rank by 1. it will then send messages to its adjacent vertices. on the next step, the vertices adjacent to 1 update their rank by the number of messages they received in the previous step. this process continues until no more messages are found in the system. the aggregation of all the rank values is the result of the algorithm. the general pattern of a bulk synchronous parallel step is: 1.) get messages 2.) process messages 3.) send messages.

when edges are labeled (e.g. friend, created, purchased, etc. — multi-relational graphs ), its necessary to have greater control over how messages are passed. in other words, its necessary to filter out particular paths emanating from the start vertex. for instance, in a friend-of-a-friend traversal, created -edges should be ignored. to do so, one can imagine using the gremlin language within a distributed graph traversal engine. in this model, a step in gremlin is a step in the bulk synchronous parallel model.
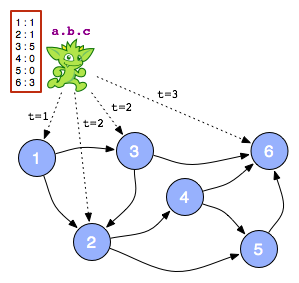
given the running example of a.b.c in the local engine model, a gremlin-esque distributed engine example is as follows. a “start message” of a.b.c is sent to vertex 1. vertex 1 will “pop off” the first step a of the path description and then will pass a message of b.c to those vertices that satisfy a . in this way, at step 2, vertices 2 and 3 have b.c waiting for them in their inbox. finally, at step 3, vertex 6 receives the message c . if a side-effect is desired (e.g. vertex rankings), a global data structure should be avoided. given the parallel nature of distributed traversal engines, it is best to avoid thread blocking when writing to a global data structure. instead, each vertex can maintain a portion of the data structure (the red boxes). moreover, for non-regular path descriptions (require memory), local data structures can serve as a “scratch pad.” finally, when the computation is complete a “reduce”-phase can yield the rank results as an aggregation of the data structure components (the union of the red boxes).
there is much work to be done in this area and members of the tinkerpop team are currently researching a unification of the local and distributed models of graph traversal. in this way, certain steps of a path description may be local and then others may be “fanned out” to run in parallel. we are on the edge of our seats to see what will come out of this thought traversal .
acknowledgements
the contents of this post have been directly inspired by conversations with alex averbuch , peter neubauer , andreas kollegger , and ricky ho . indirect inspiration has come from my various collaborators and all the contributors to the tinkerpop space.
source:
http://markorodriguez.com/2011/04/19/local-and-distributed-traversal-engines/
Opinions expressed by DZone contributors are their own.
Comments