Low-Level Optimizations in ClickHouse: Utilizing Branch Prediction and SIMD To Speed Up Query Execution
ClickHouse accelerates queries using SIMD and optimizes block processing. It picks the best function implementation, boosting performance on AVX2 processors.
Join the DZone community and get the full member experience.
Join For FreeIn data analysis, the need for fast query execution and data retrieval is paramount. Among numerous database management systems, ClickHouse stands out for its originality and, one could say, a specific niche, which, in my opinion, complicates its expansion in the database market.
I’ll probably write a series of articles on different features of ClickHouse, and this article will be a general introduction with some interesting points that few people think about when using various databases.
ClickHouse was created from scratch to process large volumes of data as part of analytical tasks, starting with the Yandex.Metrica project in 2009. The development was driven by the need to process many events generated by millions of websites to provide real-time analytical reports for Metrica’s clients. The requirements were very specific, and none of the existing databases at that time met the criteria.
Let’s take a look at these requirements:
- Maximize query performance
- Real-time data processing
- Ability to store petabytes of data
- Fault tolerance in terms of data centers
- Flexible query language
The list is pretty obvious, except perhaps for “fault tolerance in terms of data centers.” Let me expand on this point a bit more. Living in countries with unstable infrastructure and high infrastructure risks, ClickHouse developers face various unforeseen situations, such as accidental damage to cables, power outages, and flooding with water from a burst pipe that, for some reason, was near the servers. All of this can interrupt the work of data centers. Yandex strategically designs services, including the database for Metrics, to ensure continuous operation even under such extreme conditions. This requirement is especially true given the need to process and store petabytes of data in real time. It’s as if the database was designed to survive an “infrastructure apocalypse.”
There was nothing suitable on the market at that time. Only a few databases could realize, at most, three out of five parameters and that with some pretensions, five was out of the question.
Key Features
ClickHouse focuses on interactive queries that run in a second or faster. This is important because a user won’t wait if a report takes longer to load. Analysts also benefit from instant query responses, allowing them to ask more queries and focus on working with the data, improving the quality of analysis.
ClickHouse uses SQL; it’s obvious. The advantage is that SQL is known to all analysts. However, SQL is not flexible for arbitrary data transformations, so ClickHouse has added many extensions and features.
It is rare for ClickHouse to aggregate data in advance to maintain the flexibility and accuracy of reports. Storing individual events avoids loss of aggregation. Developers working with ClickHouse should allocate event attributes in advance and pass them to the system in a structured form, avoiding using unstructured formats to preserve the interactivity of queries.
How To Execute a Query Quickly
- Quick read:
- Only the required columns
- Read locality, i.e., index is needed
- Data compression
2. Fast processing:
- Block processing
- Low-level optimizations
1. Quick Read
The easiest way to speed up a query in basic analytics scenarios is to use columnar data organization, i.e., storing data by column. This allows you to load only those columns needed for a particular query. When the number of columns reaches hundreds, loading all the data will slow down the system — and this is a scenario we need to avoid!
Since the data usually does not fit into RAM, organizing local readings from disk is necessary. Full loading of the entire table is inefficient, so it is required to use an index to limit reading to only the essential parts of the data. However, even when reading this part of the data, access to the data must be localized — moving around the disk in search of the necessary data will significantly slow down the query execution.
Finally, data must be compressed. This reduces their volume and significantly saves disk bandwidth, which is critical for high processing speeds.
2. Fast Processing
And now, finally, I’m getting to the point where I’m summarizing the primary purpose of this article.
Once the data has been read, it needs to be processed very quickly, and ClickHouse provides many mechanisms for this.
The main advantage is the processing of data in blocks. A block is a small part of a table consisting of several thousand rows. This is important because ClickHouse works like an interpreter, and interpreters can be notoriously slow. However, if you spread the processing overhead over thousands of rows, this becomes imperceptible. Working with blocks allows using SIMD instructions, significantly speeding up data processing.
When analyzing weblogs, a block may contain data on thousands of queries. These queries are processed simultaneously using SIMD instructions, providing high performance and minimal time consumption.
Block processing also has a favorable effect on processor cache utilization. When a block of data is loaded into the cache, processing it in the cache is much faster than if the data were constantly unloaded and loaded from main memory. For example, when working with large analytics tables in ClickHouse, caching allows you to process data faster and minimize memory access costs.
ClickHouse also uses many low-level optimizations. For example, data aggregation and filtering functions are designed to minimize the number of operations and maximize the capabilities of modern processors.
SIMD
Again, in ClickHouse, data is processed in blocks that include multiple columns with a set of rows. By default, the maximum block size is 65,505 rows. A block is an array of columns, each an array of primitive-type data. This approach to array processing in the engine provides several key benefits:
- Optimizes cache and CPU pipeline usage
- Allows the compiler to automatically vectorize code using SIMD instructions to improve performance
Let’s start with the difficulties associated with SIMD implementation:
- There are many SIMD instruction sets, and each requires a different implementation.
- Not all processors, especially older or low-cost models, support modern SIMD instruction sets.
- Platform-dependent code is challenging to develop and maintain, which increases the likelihood of bugs.
- Incorporating platform-dependent code requires a specific approach for each compiler, making it difficult to use in different environments.
Besides, you should consider that when developing code using SIMD, it is important to test it on different architectures to avoid compatibility and correctness problems.
So, how were these challenges met? Briefly:
- Insertion and generation of platform-specific code are done through macros, simplifying the management of different architectures.
- All platform-specific objects and functions are in separate namespaces, which improves code organization and support.
- If the code is unsuitable for any architecture, it is automatically excluded, and the current platform is automatically determined.
- The optimal implementation is selected from the available options using the Bayesian multi-armed bandit method, which allows dynamically selecting the most efficient approach depending on the execution conditions.
This approach allows you to consider different architectural features and customize your code for a specific platform without excessive complexity or the risk of bugs.
A Little Bit of Code
If you look at the code, the most crucial class that takes care of the basic functionality of implementation selection is ImplementationSelector.
Let’s take a look at what this class is all about:
template <typename FunctionInterface>
class ImplementationSelector : WithContext
{
public:
using ImplementationPtr = std::shared_ptr<FunctionInterface>;
explicit ImplementationSelector(ContextPtr context_) : WithContext(context_) {}
ColumnPtr selectAndExecute(const ColumnsWithTypeAndName & arguments, const DataTypePtr & result_type, size_t input_rows_count) const
{
if (implementations.empty())
throw Exception(ErrorCodes::NO_SUITABLE_FUNCTION_IMPLEMENTATION,
"There are no available implementations for function " "TODO(dakovalkov): add name");
bool considerable = (input_rows_count > 1000);
ColumnPtr res;
size_t id = statistics.select(considerable);
Stopwatch watch;
if constexpr (std::is_same_v<FunctionInterface, IFunction>)
res = implementations[id]->executeImpl(arguments, result_type, input_rows_count);
else
res = implementations[id]->execute(arguments, result_type, input_rows_count);
watch.stop();
if (considerable)
{
statistics.complete(id, watch.elapsedSeconds(), input_rows_count);
}
return res;
}
template <TargetArch Arch, typename FunctionImpl, typename ...Args>
void registerImplementation(Args &&... args)
{
if (isArchSupported(Arch))
{
const auto & choose_impl = getContext()->getSettingsRef().function_implementation.value;
if (choose_impl.empty() || choose_impl == detail::getImplementationTag<FunctionImpl>(Arch))
{
implementations.emplace_back(std::make_shared<FunctionImpl>(std::forward<Args>(args)...));
statistics.emplace_back();
}
}
}
private:
std::vector<ImplementationPtr> implementations;
mutable detail::PerformanceStatistics statistics;
};
It is this class that provides flexibility and scalability when working with different processor architectures, automatically selecting the most efficient function implementation based on statistics and system characteristics.
The main points to look out for are:
FunctionInterface: This is the interface of the function that is used in the implementation. This is usuallyIFunctionorIExecutableFunctionImpl, but it can also be any interface with an execute method. This parameter specifies which particular implementation will be used to execute the function.context_: This is a pointer to a context (e.g.,ContextPtr) that stores information about the current execution environment. This allows the implementer to choose an optimal strategy based on the context information.SelectAndExecute: This method selects the best implementation based on processor architecture and statistics of previous runs. Depending on the function, the interface calls eitherexecuteImplorexecute. The default selection will be made if there is not enough data to gather statistics (e.g., too few rows).registerImplementation: This is a method that registers a new function implementation for the specified architecture. If the architecture is supported by the processor, an instance of the implementation is created and added to the list of available implementations.std::vector<ImplementationPtr> implementations: This stores all registered implementations of the function. Each vector element is a smart pointer to a specific implementation, depending on the architecture.mutable detail::PerformanceStatistics statistics: Performance statistics collected from previous runs. It is protected by an internal mutex, which allows you to safely collect and analyze data about execution time and the number of processed rows.
The code uses macros to generate platform-dependent code, making managing different implementations for different processor architectures easy.
Example of Using ImplementationSelector
As an example, let’s look at how UUID generation is implemented.
And a little bit of code again:
#include <DataTypes/DataTypeUUID.h>
#include <Functions/FunctionFactory.h>
#include <Functions/FunctionHelpers.h>
#include <Functions/FunctionsRandom.h>
namespace DB
{
#define DECLARE_SEVERAL_IMPLEMENTATIONS(...) \
DECLARE_DEFAULT_CODE (__VA_ARGS__) \
DECLARE_AVX2_SPECIFIC_CODE(__VA_ARGS__)
DECLARE_SEVERAL_IMPLEMENTATIONS(
class FunctionGenerateUUIDv4 : public IFunction
{
public:
static constexpr auto name = "generateUUIDv4";
String getName() const override { return name; }
size_t getNumberOfArguments() const override { return 0; }
bool isDeterministic() const override { return false; }
bool isDeterministicInScopeOfQuery() const override { return false; }
bool useDefaultImplementationForNulls() const override { return false; }
bool isSuitableForShortCircuitArgumentsExecution(const DataTypesWithConstInfo & /*arguments*/) const override { return false; }
bool isVariadic() const override { return true; }
DataTypePtr getReturnTypeImpl(const ColumnsWithTypeAndName & arguments) const override
{
FunctionArgumentDescriptors mandatory_args;
FunctionArgumentDescriptors optional_args{
{"expr", nullptr, nullptr, "any type"}
};
validateFunctionArguments(*this, arguments, mandatory_args, optional_args);
return std::make_shared<DataTypeUUID>();
}
ColumnPtr executeImpl(const ColumnsWithTypeAndName &, const DataTypePtr &, size_t input_rows_count) const override
{
auto col_res = ColumnVector<UUID>::create();
typename ColumnVector<UUID>::Container & vec_to = col_res->getData();
size_t size = input_rows_count;
vec_to.resize(size);
/// RandImpl is target-dependent and is not the same in different TargetSpecific namespaces.
RandImpl::execute(reinterpret_cast<char *>(vec_to.data()), vec_to.size() * sizeof(UUID));
for (UUID & uuid : vec_to)
{
UUIDHelpers::getHighBytes(uuid) = (UUIDHelpers::getHighBytes(uuid) & 0xffffffffffff0fffull) | 0x0000000000004000ull;
UUIDHelpers::getLowBytes(uuid) = (UUIDHelpers::getLowBytes(uuid) & 0x3fffffffffffffffull) | 0x8000000000000000ull;
}
return col_res;
}
};
) // DECLARE_SEVERAL_IMPLEMENTATIONS
#undef DECLARE_SEVERAL_IMPLEMENTATIONS
class FunctionGenerateUUIDv4 : public TargetSpecific::Default::FunctionGenerateUUIDv4
{
public:
explicit FunctionGenerateUUIDv4(ContextPtr context) : selector(context)
{
selector.registerImplementation<TargetArch::Default,
TargetSpecific::Default::FunctionGenerateUUIDv4>();
#if USE_MULTITARGET_CODE
selector.registerImplementation<TargetArch::AVX2,
TargetSpecific::AVX2::FunctionGenerateUUIDv4>();
#endif
}
ColumnPtr executeImpl(const ColumnsWithTypeAndName & arguments, const DataTypePtr & result_type, size_t input_rows_count) const override
{
return selector.selectAndExecute(arguments, result_type, input_rows_count);
}
static FunctionPtr create(ContextPtr context)
{
return std::make_shared<FunctionGenerateUUIDv4>(context);
}
private:
ImplementationSelector<IFunction> selector;
};
REGISTER_FUNCTION(GenerateUUIDv4)
{
factory.registerFunction<FunctionGenerateUUIDv4>();
}
}
The code above contains the generateUUIDv4 function, which generates a random UUID and can choose the best implementation depending on the processor architecture (e.g., using SIMD instructions on AVX2-enabled processors).
How It Works
Declaring Multiple Implementations
The DECLARE_SEVERAL_IMPLEMENTATIONS macro declares multiple versions of a function depending on the processor architecture. In this case, two implementations are declared: the standard (default) and AVX2-enabled version for processors supporting the corresponding SIMD instructions.
FunctionGenerateUUIDv4 Class
This class inherits from the IFunction, which we have already met in the previous section, and implements the basic logic of the UUID generation function.
getName(): Returns the name of the function —generateUUUIDv4getNumberOfArguments(): Returns 0 since the function takes no argumentsisDeterministic(): Returns false since the function’s result changes with each callgetReturnTypeImpl(): Determines the function’s return data type, the UUIDexecuteImpl(): This is the main part of the function where UUID generation is performed
UUID Generation
The executeImpl() method generates a vector of UUIDs for all rows (defined by the input_rows_count variable).
randimpl::executeis used to generate random bytes that populate each entry in the column.- Each UUID is then modified as required by RFC 4122 for UUID v4. This includes setting certain bits in the high and low parts of the UUID to indicate version and variant.
Selecting the Optimal Implementation
The second version of the FunctionGenerateUUIDv4 class uses ImplementationSelector, which allows you to select the optimal implementation of a function depending on the processor architecture.
selector.registerImplementation(): The constructor registers two implementations: the default (Default) and for AVX2-enabled processors (ifUSE_MULTITARGET_CODEis enabled).selectAndExecute(): TheexecuteImpl()method calls this method, which selects the most efficient implementation of the function based on the architecture and statistics of previous runs.
Registering the Function
At the end of the code, the function is registered in the function factory using the REGISTER_FUNCTION(GenerateUUIDv4) macro. This allows ClickHouse to use it in SQL queries.
Now let’s look at the operation of the code step by step:
- When calling the
generateUUIDv4function, ClickHouse first checks which processor architecture is being used. - Depending on the architecture (for example, whether the processor supports AVX2), the best function implementation is selected using
ImplementationSelector. - The function generates random UUIDs using the
RandImpl::executemethod and then modifies them according to the UUID v4 standard. - The result is returned as a UUID column that is ready for queries.
Thus, processors without AVX2 support will use the standard implementation, and processors with AVX2 support will use an optimized version with SIMD instructions to speed up UUID generation.
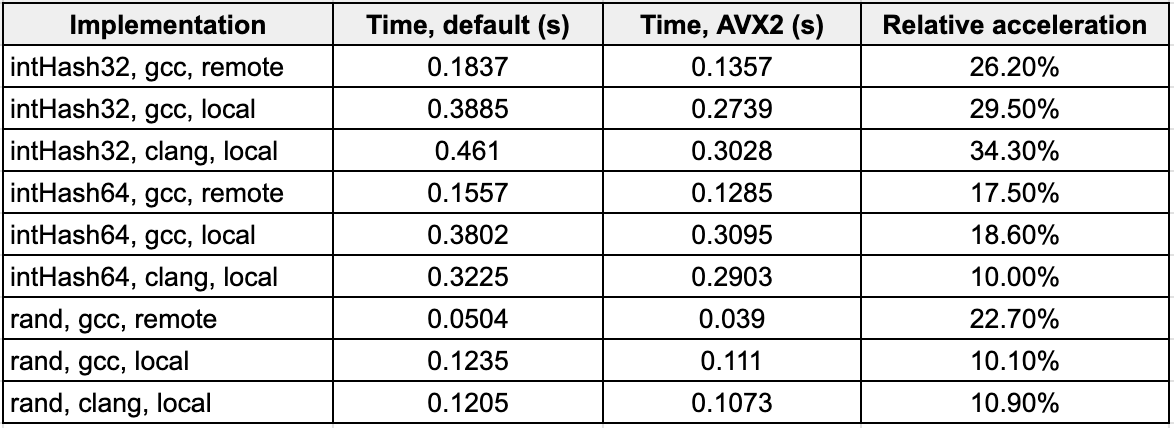
Some Statistics
For a query like this:
SELECT count()
FROM
(
SELECT generateUUIDv4() AS uuid
FROM numbers(100000000)
)
… you get some nice speed gain numbers at the expense of SIMD.
Opinion
From my experience with ClickHouse, I can say that there are many things under the hood that greatly simplify the lives of analysts, data scientists, MLEs, and even DevOps. All this functionality is available absolutely free of charge and with a relatively low entry threshold.
There is no perfect database, just as there is no ideal solution to any problem. But I believe that ClickHouse is close enough to this limit. And it would be a significant omission not to try it as one of the practical tools for creating large systems.
Opinions expressed by DZone contributors are their own.
Comments