Mastering Retrieval Augmented Generation: From Fundamentals to Advanced Techniques
RAG enhances LLMs by linking them to external retrieval systems, while advanced RAG addresses challenges in query formulation, embedding generation, and accuracy.
Join the DZone community and get the full member experience.
Join For FreeDespite their remarkable capabilities in generating text, answering complex questions, and performing a wide range of tasks, Large Language Models (LLMs) have notable limitations that hinder their real-world applicability. One significant challenge is their inability to consistently provide precise, up-to-date responses. This issue is especially critical in fields like healthcare, law, and finance, where the accuracy and explainability of information are paramount. For instance, imagine a financial analyst querying the latest market trends or a doctor seeking updated medical guidelines.
Retrieval-augmented generation (RAG) addresses these limitations by combining the strengths of LLMs with information retrieval systems, ensuring more accurate, reliable, and contextually grounded outputs.
Limitations of LLMs and How RAG Helps
Hallucination
LLMs sometimes generate content that is "nonsensical or unfaithful to the provided source content" (Ji et al., 2023). This phenomenon, known as hallucination, occurs because the models rely on patterns in their training data rather than a solid understanding of the underlying facts. For example, they may produce inaccurate historical dates, fictitious citations, or nonsensical scientific explanations. RAG mitigates hallucination by grounding the generation process in trusted external sources. By retrieving information from verifiable knowledge bases or databases, RAG ensures that outputs are aligned with reality, reducing the occurrence of spurious or incorrect details.
Outdated Knowledge
LLMs are limited by the static nature of their training data, meaning their knowledge is frozen at the time of training. They lack the ability to access new information or keep up with fast-changing fields like technology, medicine, or global affairs. RAG overcomes this limitation by integrating dynamic retrieval mechanisms that allow the model to query up-to-date sources in real time. For instance, when integrated with APIs or live databases, RAG systems can provide accurate responses even in domains with frequent updates, such as real-time stock market analysis or the latest medical guidelines.
Opaque and Untraceable Reasoning
The reasoning process of LLMs is often non-transparent, making it difficult for users to understand or trust how answers are derived. This lack of traceability can be problematic in high-stakes scenarios where accountability is essential. RAG addresses this by incorporating citations and source traceability into its outputs. By linking retrieved information to authoritative sources, RAG not only enhances transparency but also builds user trust. This feature is particularly beneficial in legal, academic, or compliance-focused applications.
How RAG Works
A simple RAG system, as illustrated in the image below, consists of two main components: the Retriever and the Augmented Generator.
Retriever
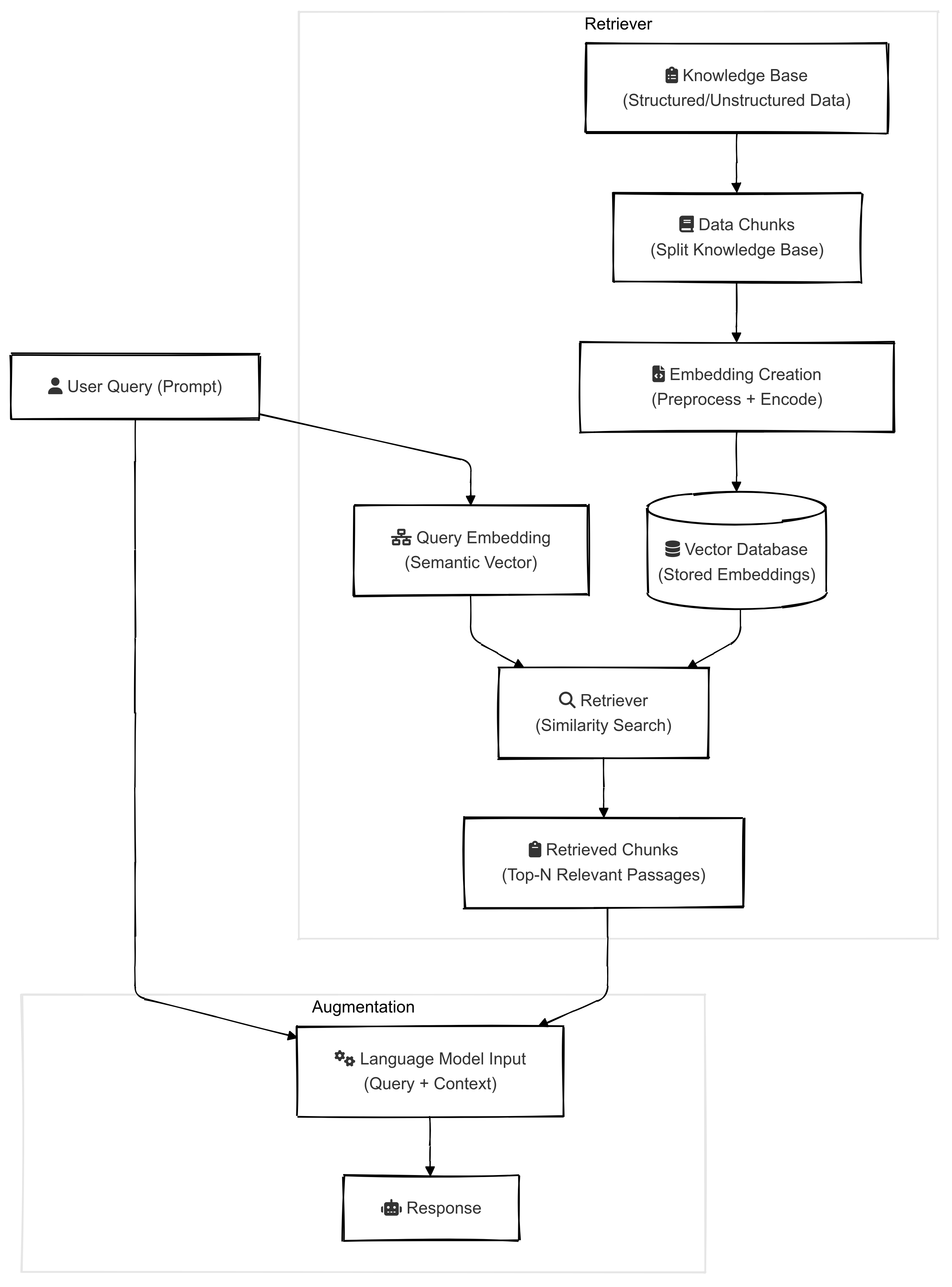
Efficient retrieval methods are at the core of RAG systems, enabling them to identify the most relevant information from a knowledge base to contextualize and ground the outputs of the language model. This knowledge base can include structured or unstructured data sources, such as internal documents, document databases, or the broader internet. The retrieval process involves:
Preprocessing and Indexing
- Chunking: Large documents are segmented into smaller, logically coherent chunks ensuring each chunk captures a meaningful context. For example, a 100-page technical report might be divided into 1-page sections, each covering a distinct topic.
- Knowledge representation: This step converts the chunks into mathematical representations that facilitate retrieval and comparison. It includes both dense and sparse approaches:
- Dense representations: Chunks are converted into dense vector representations (embeddings) using embedding models like Sentence-BERT, OpenAI's embedding models, or other transformer-based approaches.
- Sparse representations: Alternatively, sparse representations such as TF-IDF or BM25 can be computed to create a term-based representation of the chunks.
- Indexing: Indexing organizes the processed representations of document chunks into specialized data structures, enabling efficient and scalable retrieval.Different indexing techniques are used depending on the type of representation:
- Vector store indexing: Dense embeddings are stored in a vector database (e.g., FAISS, Pinecone, Weaviate) for similarity-based retrieval.
- Sparse indexing: TF-IDF or BM25 representations are indexed using traditional inverted indices to support lexical matching.
- Query embedding: The user's query is processed into a sparse or dense vector using the same model used for the knowledge base embeddings. This ensures both reside in the same vector space for meaningful comparisons.
- Similarity search: The query embedding is compared against the stored embeddings using similarity metrics such as cosine similarity or inner product to retrieve relevant data from the knowledge base.
Augmented Generation
The retrieved information is combined with the original user query and provided as input to a language model. The generation process ensures the response is:
- Contextual: Incorporates the user’s query and retrieved-context to generate outputs relevant to the question.
- Grounded: Based on reliable, retrieved knowledge rather than speculative extrapolation.
- Explainable: Traces back to the retrieved sources, enabling users to verify the response.
Advanced RAG Techniques
The simple RAG architecture presented earlier had several potential points of failure that can degrade the quality of the system’s output.
- One of the first challenges occurs at the user query stage, where the query might not be clearly articulated or precisely framed, leading to ineffective retrieval. Additionally, even when the query is well-formed, the query embedding process may fail to capture the full intent behind the query, especially when the query is complex. This can cause a mismatch between the query and the relevant information retrieved from the knowledge base.
- Furthermore, the retrieval stage may introduce additional challenges. The system may return irrelevant or low-confidence documents due to limitations in the retrieval model. If the retrieved context is not highly relevant to the query, the information passed to the LLM is likely to be misleading, incomplete, or out of date. This can lead to hallucinations or a generation of responses that are not grounded in the correct context, undermining the reliability of the system.
To address these challenges, a strong and reliable RAG system must intervene at each of these stages to ensure optimal performance. This is where the concept of an Advanced RAG system comes into play. In an Advanced RAG framework, sophisticated mechanisms are introduced at every stage of the pipeline, from query formulation and embedding generation to retrieval and context utilization. These interventions are designed to mitigate the risks of poor query formulation, inaccurate embeddings, and irrelevant or outdated context, resulting in a more robust system that delivers highly relevant, accurate, and trustworthy outputs. By addressing these points of failure proactively, Advanced RAG ensures that the language model generates responses that are not only contextually grounded but also transparent and reliable.
The Advanced RAG architecture introduces key improvements, as shown in the diagram below. Compared to the simple RAG model, Advanced RAG incorporates additional steps to address the potential points of failure.
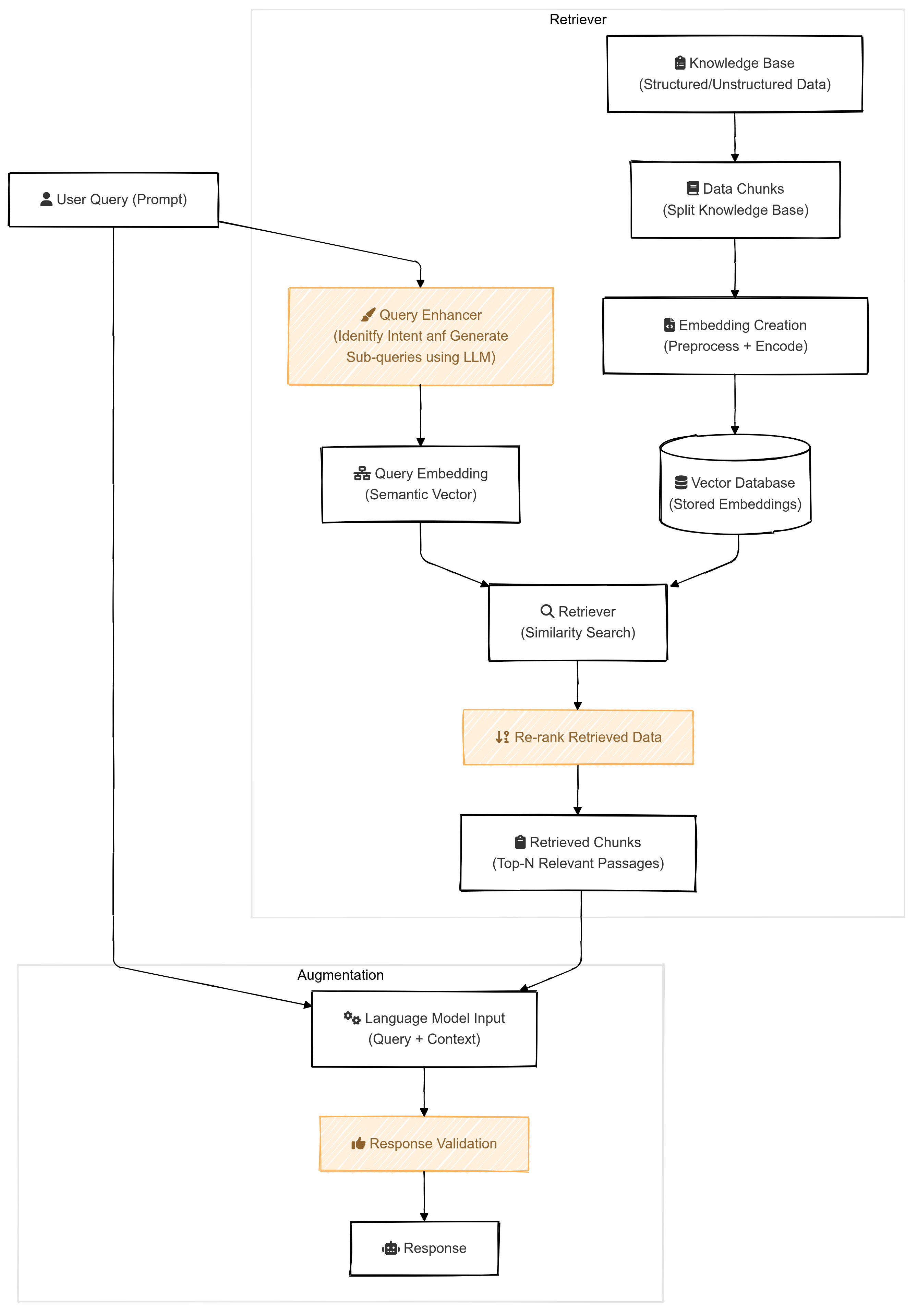
Key Enhancements in Advanced RAG
Data Preprocessing for LLM-Based RAG Systems
Data preprocessing is the foundational step in a RAG system. It involves transforming diverse data formats — such as PDFs, Word documents, web pages, or code files—into a consistent structure that can be efficiently processed by the RAG pipeline. Proper preprocessing is critical for enhancing accuracy, efficiency, and relevance in information retrieval and response generation. Key Steps in Data Preprocessing include:
Tokenization and Text Cleaning
Tokenization and cleaning ensure data is structured in a form suitable for the model. Key considerations include:
Consistent Tokenization
The tokenizer associated with the LLM being used should be employed to ensure compatibility and efficiency (Lewis et al., 2020). For example, GPT models use specialized tokenization schemes optimized for their architecture (OpenAI 2024).
Text Cleaning
Irrelevant characters and noise, such as excessive whitespace or non-meaningful special symbols, should be removed. Semantically relevant characters, such as those in mathematical or programming contexts, should be preserved.
Chunking for Efficient Retrieval
Chunking involves segmenting large documents into smaller, meaningful units to address token limits and context window constraints inherent in LLMs. By organizing similar information into compact chunks, the retrieval process becomes more efficient and precise. Various chunking strategies can be adopted depending on the type of data and specific use case (Weights & Biases, 2024):
- Fixed-length chunking: This method divides text into segments based on a fixed number of tokens or characters. While straightforward, it risks disrupting semantic flow by splitting content arbitrarily.
- Semantic chunking: Text is divided along natural thematic breaks, much like separating a book into chapters. This method enhances interpretability but may require advanced NLP techniques for implementation (Lewis et al., 2020).
- Content-based chunking: Segmentation is tailored to the structure of the document. For instance, code files can be split by function definitions, and web pages can be divided based on HTML elements, ensuring relevance to the document’s format and purpose.
Query Enhancement
Advanced RAG systems employ LLMs and a variety of NLP techniques to enhance the understanding of user queries. These include:
Intent Classification
This helps the system identify the user’s intent, allowing it to better understand the purpose behind the query. For instance, is the query seeking factual information, a product feature comparison, or technical support? Intent classification ensures the retrieval process is customized to meet the user’s specific needs (Weights & Biases, 2024).
Query Decomposition
For complex or multi-faceted queries, the system breaks the query into smaller, more focused subqueries. This approach ensures that the retrieval process comprehensively addresses all aspects of the user’s request and retrieves highly specific and relevant information (Rackauckas et al. 2024).
Conversation History Utilization
This technique enables the RAG system to enhance queries by leveraging past interactions. By maintaining context across multiple exchanges, the system analyzes and incorporates previous queries and responses. Through chat history condensation, key details from prior interactions are distilled to reduce noise and preserve relevance. Additionally, contextual query reformulation refines the current query by integrating historical context, allowing the system to retrieve more accurate and context-aware information. This ensures the delivery of coherent and tailored responses, even in complex or evolving conversational scenarios (Weights & Biases, 2024).
Hypothetical Document Embeddings (HyDE)
HyDE utilizes LLMs to create hypothetical documents that are relevant to the original query. Although these generated documents may include factual inaccuracies and are not real, they serve to capture relevance by offering illustrative examples, which can then aid in the retrieval of the actual documents (Gao et al., 2022).
Advanced Retrieval
In addition to utilizing the enhanced queries for retrieval, information retrieval techniques include:
Classical Information Retrieval
Classical information retrieval techniques focus on scoring and ranking documents based on their relevance to a given query. Two prominent methods are Term Frequency-Inverse Document Frequency (TF-IDF) and Best Matching 25 (BM25). While these approaches are effective for matching tokens, they often fall short when it comes to understanding the content or context of the query and document, relying primarily on surface-level token similarity rather than deeper semantic relationships.
Neural Information Retrieval
Neural information (NI) retrieval methods represent documents using language models, producing dense numeric representations (embeddings) that capture the semantic and contextual meaning of the documents. These dense representations allow for more accurate and nuanced matching between queries and documents compared to traditional approaches. NI retrieval techniques include (Khattab et al. 2020):
Bi-Encoder Model
In a Bi-Encoder model, the query and document are independently encoded into single fixed-length vector representations using separate neural networks, such as a pre-trained BERT model. These representations capture the overall semantic meaning of the query and document rather than token-level details. The similarity between the query and document is then computed using a similarity function, such as the dot product or cosine similarity, to identify relevant documents. This strategy can be further enhanced by fine-tuning the pre-trained BERT model to maximize the similarity between query and document embeddings.
Fine-tuning is typically achieved by optimizing the negative log-likelihood of positive document pairs, as outlined by Karpukhin et al. (2020). This approach improves the alignment of query and document representations, leading to more accurate retrieval. This approach is highly efficient for large-scale retrieval, as document embeddings can be precomputed and indexed, enabling fast nearest-neighbor searches. However, the independent encoding of the query and document limits the ability to capture intricate interactions between them, which can reduce the retrieval quality, particularly for more complex queries.
Cross-Encoder Model
In contrast, a Cross-Encoder model processes both the query and document simultaneously by concatenating them and passing the combined input through a single transformer model. This allows for more complex interactions between the query and document, resulting in potentially higher-quality relevance scores. The fine-grained attention between the query and document typically leads to more accurate relevance assessments. However, this approach is computationally expensive, as each query-document pair must be encoded independently at inference time. As a result, it is less scalable for large datasets.
ColBERT
ColBERT (Contextualized Late Interaction BERT) (Khattab et al. 2020) is an advanced retrieval model designed to strike a balance between the efficiency of Bi-Encoders and the accuracy of Cross-Encoders. Its core innovation lies in computing a matrix of similarity scores between query tokens and document tokens, enabling a fine-grained assessment of relevance. For each document, the overall relevance score is computed as the sum of the maximum similarity scores between individual document tokens and query tokens. This token-wise interaction allows ColBERT to capture nuanced relationships while maintaining scalability. ColBERT achieves high efficiency because, like Bi-Encoder models, it allows documents to be pre-encoded and stored in advance. During query processing, only the query needs to be encoded, after which the maximum similarity scores are computed on the fly. This approach significantly reduces computational overhead while delivering high retrieval performance. This combination of pre-encoded document representations and late interaction makes ColBERT an effective choice for large-scale information retrieval tasks.
Re-Ranker
Neural information retrieval models offer significant advancements in information retrieval but come with considerable computational costs, particularly due to the need for forward inference on transformer-based architectures such as BERT. This is especially challenging in scenarios with stringent latency requirements. To make this practical, these models can be effectively utilized as re-rankers in a two-step retrieval pipeline:
- An initial retrieval phase uses efficient term-based models, such as BM25, to identify the top K candidate documents.
- These K documents are then re-ranked using neural information retrieval models, which assess their relevance through contextual scoring.
In the re-ranking stage, advanced scoring mechanisms — such as cross-encoders or ColBERT, evaluate and reorder the retrieved documents based on their contextual relevance and quality. By incorporating this step, the re-ranking process reduces irrelevant information in the retrieved set, thereby improving the contextual input passed to downstream language models. This methodology not only mitigates computational overheads but also enhances the quality of responses generated in subsequent processing stages.
Response Synthesis and Prompt Engineering
Response synthesis is a critical component that bridges the gap between raw data retrieval and user-friendly output in the RAG system. Prompt engineering plays a crucial role in maximizing the performance of such systems, enabling the model to generate accurate, contextually appropriate, and reliable responses (Brown et al., 2020; Bender et al., 2021). By systematically providing clear instructions and examples and leveraging advanced language models, the quality, accuracy, and trustworthiness of generated responses can be significantly improved.
Key Techniques for Effective Prompt Engineering
Define the Role
Clearly define the role the language model (LM) should play in the given task (e.g., "You are a helpful assistant"). This helps set expectations for how the model should behave and respond.
Define the Goal
Explicitly state the objective of the response (e.g., "Answer the following question"). A well-defined goal ensures that the LM's output aligns with user expectations and task requirements.
Provide Context
Contextual information is crucial for guiding the model’s output. Include relevant background data, domain-specific knowledge, or specific constraints that the model should consider while generating the response.
Add Instructions
Specify detailed instructions on how the model should generate the output (e.g., "Use bullet points to list the steps"). Clear guidance on the structure or format can improve the clarity and usability of the generated response.
Few-Shot Learning
Incorporating a small set of high-quality, diverse examples can significantly enhance the performance and adaptability of LMs in RAG systems (Brown et al., 2020). Few-shot prompting provides the model with a middle ground between zero-shot learning (where no examples are provided) and fine-tuning (where the model is retrained on a specific dataset). By embedding a few representative examples, the model learns the desired output behavior, improving its response accuracy.
Representative Samples
Choose examples that are reflective of the most common query types and desired response formats the RAG system will handle.
Specificity and Diversity
Include examples that balance specificity to your use case with diversity to address a wide range of queries.
Dynamic Example Set
As the system evolves, regularly update the set of examples to align with new query types or business needs.
Balancing Performance and Token Usage
LLMs have limitations on the amount of text they can process in a single prompt (context window). It's essential to find the right balance between including enough examples to guide the model effectively and not overloading the context window, which can degrade performance.
Incorporate Model Reasoning
To enhance the transparency of the RAG system, request the model to explain its thought process (Bender et al., 2021). This helps improve the trustworthiness of the model’s outputs and can assist users in understanding the reasoning behind specific responses, especially when dealing with complex or uncertain queries.
By employing these strategies in prompt engineering, one can significantly improve the functionality, performance, and reliability of a RAG system, ensuring that the generated responses are not only accurate but also aligned with the user’s needs.
Response Validation
Before the response is presented to the user, an additional validation layer assesses the output generated by the language model. This step acts as a quality control mechanism to ensure that the response is accurate, appropriate, and grounded in the retrieved context. It can involve tasks like factual consistency checks, appropriateness scoring, and cross-referencing with trusted sources.
Conclusion
The evolution of RAG systems marks a pivotal shift in how we harness LLMs to provide precise, context-aware, and reliable information. By integrating advanced techniques such as intelligent preprocessing, enhanced query understanding, sophisticated retrieval mechanisms, and effective response synthesis, modern RAG systems address the complexities of real-world applications with remarkable efficiency.
As RAG continues to mature, its role in bridging the gap between vast unstructured data sources and actionable insights becomes increasingly indispensable. Whether applied to domains like customer support, research, or decision-making, RAG systems are poised to redefine how we interact with and benefit from AI-driven knowledge systems.
References
1. Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A. and Fung, P., 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), pp.1-38.
2. Lewis, P., Oguz, B., Rinott, R., Riedel, S., & Stenetorp, P. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS), 33, 9459–9474. https://proceedings.neurips.cc
3. OpenAI, 2024. Tokenization and context window. Retrieved from https://platform.openai.com
4. Weights & Biases, 2024. RAG in Production. [online] Available at: https://www.wandb.courses/courses/rag-in-production [Accessed 5 Oct. 2024].
5. Gao, L., Ma, X., Lin, J. and Callan, J., 2022. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496.
6. Rackauckas, Z., 2024. Rag-fusion: a new take on retrieval-augmented generation. arXiv preprint arXiv:2402.03367.
7. Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D. and Yih, W.T., 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
8. Khattab, O. and Zaharia, M., 2020, July. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval (pp. 39-48).
9. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.
10. Bender, E.M., Gebru, T., McMillan-Major, A. and Shmitchell, S., 2021, March. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610-623).
Opinions expressed by DZone contributors are their own.
Comments