Top-K: A Probabilistic Addition to RedisBloom
Look at Top-K, a probabilistic addition to RedisBloom.
Join the DZone community and get the full member experience.
Join For Free
Background
You may find yourself wondering whether you should use more probabilistic data structures in your code. The answer is, as always, it depends. If your data set is relatively small and you have the required memory available, keeping another copy of the data in an index might make sense. You’ll maintain 100% accuracy and get a fast execution time.
However, when the data set becomes sizeable, your current solution will soon turn into a slow memory hog as it stores an additional copy of the items or items’ identifiers. Therefore, when you deal with a large number of items, you might want to relax the requirement of 100% accuracy in order to gain speed and save memory space. In these instances, using the appropriate probabilistic data structure could work magic — supporting high accuracy, a predefined memory allowance and a time complexity that’s independent of your data set size.
Top-K Introduction
Finding the largest K elements (a.k.a. keyword frequency) in a data set or a stream is a common functionality requirement for many modern applications. This is often a critical task used to track network traffic for either marketing or cyber-security purposes or serve as a game leaderboard or a simple word counter. The latest implementation of Top-K in our RedisBloom module uses an algorithm called HeavyKeeper1, which was proposed by a group of researchers. They abandoned the usual count-all or admit-all-count-some strategies used by prior algorithms, such as Space-Saving or different Count Sketches. Instead, they opted for a count-with-exponential-decay strategy. The design of exponential decay is biased against mouse (small) flows and has a limited impact on elephant (large) flows. This ensures high accuracy with shorter execution times than previous probabilistic algorithms allowed, while keeping memory utilization to a fraction of what is typically required by a Sorted Set.
An additional benefit of using this Top-K probabilistic data structure is that you’ll be notified in real time whenever elements enter into or expelled from your Top-K list. If an element add-command enters the list, the dropped element will be returned. You can then use this information to help prevent DoS attacks, interact with top players or discover changes in writing style in a book.
Initializing Top-K key in RedisBloom requires four parameters:
- K — the number of items in your list;
- Width — the number of counters at each array;
- Depth — the number of arrays; and
- Decay — the probability of a counter to be decreased in case of collision1.
As a rule of thumb, the width of k*log(k), depth of log(k) or minimum of 5 and decay of 0.9, yield good results. You could run a few tests to fine-tune these parameters to the nature of your data.
Leaderboard Benchmark Using Sorted Set vs. Top-K
Redis’ Sorted Set data structure provides an easy and popular way to maintain a simple, accurate leaderboard2. With this approach, you can update members’ scores by calling ZINCRBY and retrieve lists by calling ZREVRANGE with the desirable range. Top-K, on the other hand, is initialized with the TOPK.RESERVE command. Calling TOPK.ADD will update counters, and if your Top-K list has changed, the dropped item will be returned. Finally, TOPK.LIST, as you would expect, returns the current list of K items. To compare these two options, we ran a simple benchmark with the leaderboard use case.
In this benchmark, we extracted a list of the most common words in the book War and Peace, which contains over 500,000 words. To accomplish this task, Redis Sorted Set took just under 6 seconds and required almost 4MB of RAM with guaranteed 100% accuracy. By comparison, Top-K took, on average, a quarter of that time and a fraction of the memory, especially for lower K values. Its accuracy was 100% in most cases, except for very high Ks where it ‘only’ achieved 99.9% accuracy3.
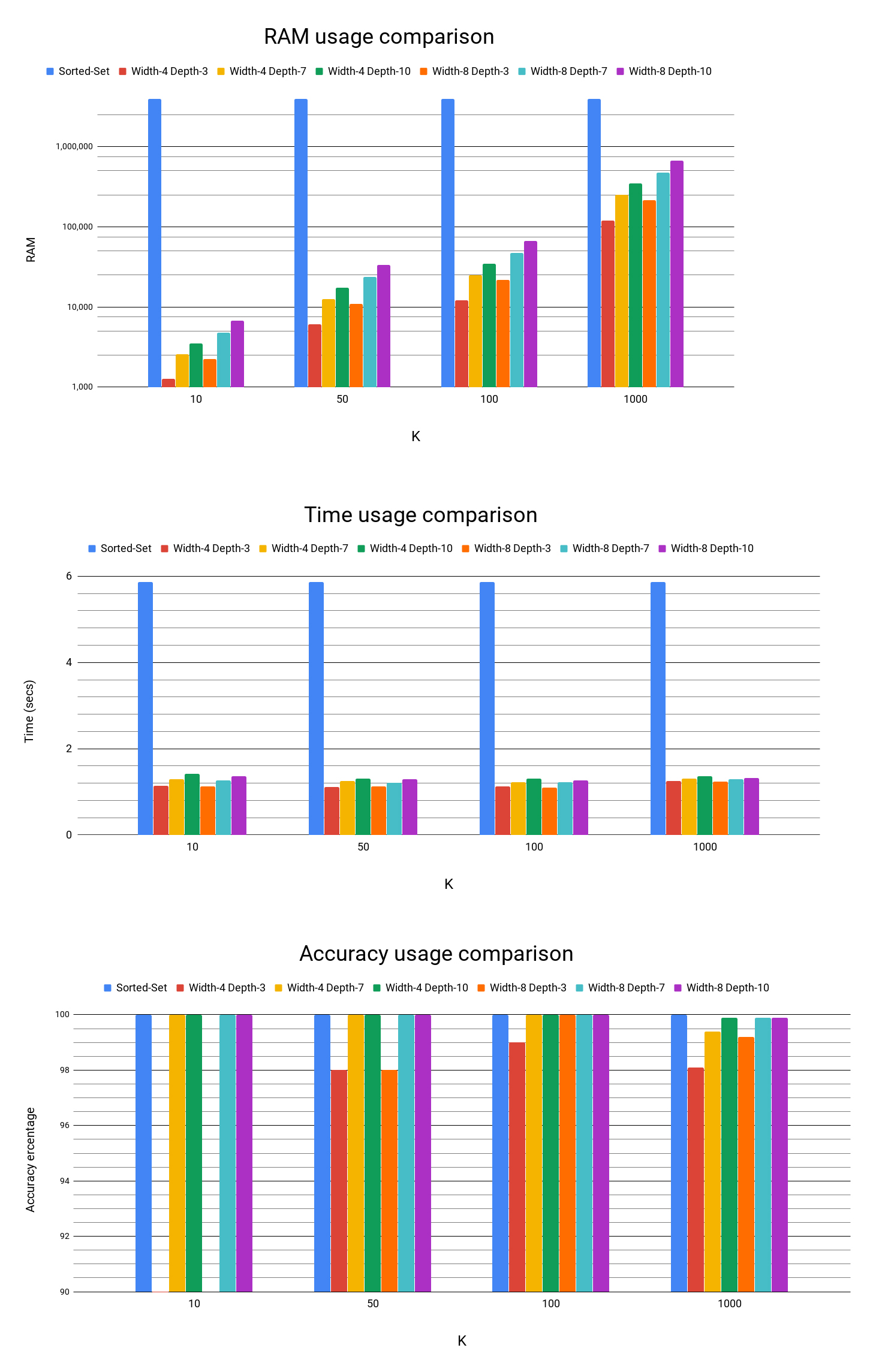
Some interesting takeaways from the results above include:
- Execution time was hardly affected by the K value.
- Insufficient depth not only reduced accuracy but also increased execution time. This might be due to frequent changes to the Top-K list and the processing time that entails.
- Space efficiency was great, and for any reasonable use case, we’d expect a 99% RAM saving.
It is important to note that different types of data might be sensitive to different variables. In my experiments, some data sets’ execution time was more sensitive to ‘K.’ In other instances, lower decay values yielded higher accuracy for the same width and depth values.
The new Top-K probabilistic data structure in RedisBloom is fast, lean, and super accurate. Consider it for any projects with streams or growing data sets that have a low memory usage requirement. Personally, this was my first project at RedisLabs and I feel lucky to be given the opportunity to work on such a unique algorithm. I could not be more happy with the results!
If you have a use case you would like to discuss, or just want to share some ideas, please feel welcome to email me.
Footnotes
[1] HeavyKeeper: An Accurate Algorithm for Finding Top-K Elephant Flows by co-primary authors: Junzhi Gong and Tong Yang.
[2] The Top 3 Game Changing Redis Use Cases.
[3] Lower results in the graph didn’t follow guidelines for width and depth.
Published at DZone with permission of Ariel Shtul. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments