Migrating Data in Couchbase From One Bucket to Another Using XDCR
In this tutorial, learn about XDCR, a feature provided by Couchbase, can make your life simpler when it comes to data migration.
Join the DZone community and get the full member experience.
Join For FreeCouchbase provides XDCR, which makes your life simpler when it comes to data migration.
Following are my assumptions for this exercise.
There is a bucket Metrics that holds data like user events info, push notifications sent from a system, the actual user data, etc.
You are running the latest version of Couchbase (current 4.6.3).
You have admin access to execute queries.
Events document has
uuidas a key, i.e.c0f55f62-b990-47bc-8caa-f42313669948.{ "type": "EventType", "eventName": "Event name", "uuid": "000008F6-DF77-4C9F-B5A9-E94065639A07", "timestamp": 1426206242415, "localTimestamp": 1426188242415, "couchbaseCreationTimestamp": 1426206242536 }Push notifications documents have
uuidkey asPUSH_N_XXXXXXX.{ "couchbaseCreationTimestamp": 1457476557919, "eventName": "SentPushnotificationEvent", "type": "EventtYPE", "uuid": "PUSH_N_893579367597", "timestamp": 1457476557919 }
Problem: We need to separate out events and push notifications entries from the Metrics bucket and put them in a new bucket called Events.
Solution steps:
Using the Couchbase UI, create a new bucket named Events.
Set views if required.
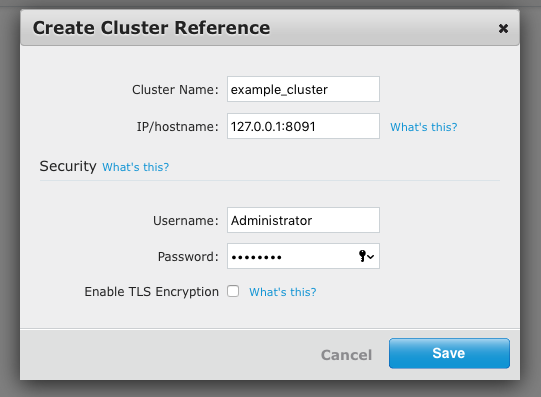
Create a Cluster Reference in XDCR. This is required for server reference.
For events, create a replication filter using the following regex:
[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}
Once the above replication is complete, delete this replication and create another replication for push notifications.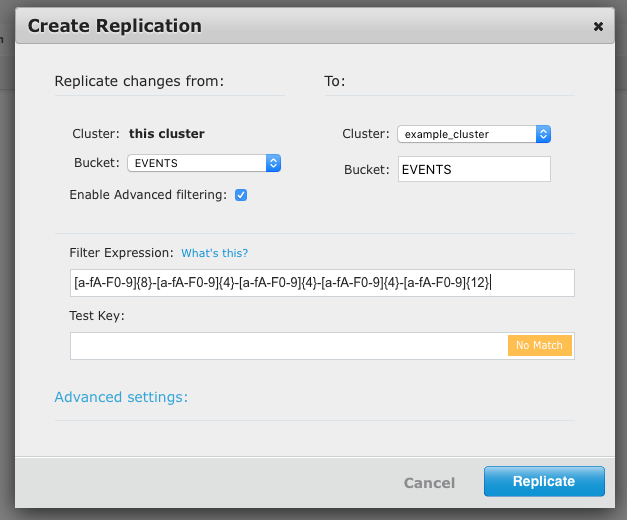
For push notifications, create a replication filter using the following regex:
PUSH_N_*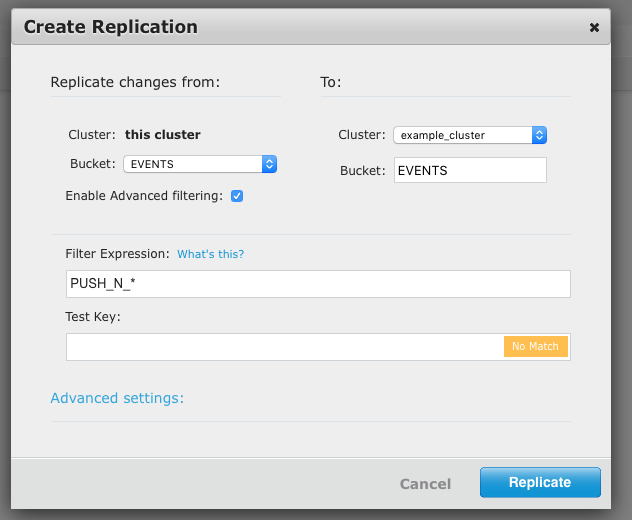
Once the replication is over, delete this filter, as well.
Now, we will work on deleting the existing documents in the Metrics bucket.
Deletion requires indexes. If the primary index does not exist, create one.
CREATE PRIMARY INDEX `metrics-primary-index` ON `METRICS` USING GSI;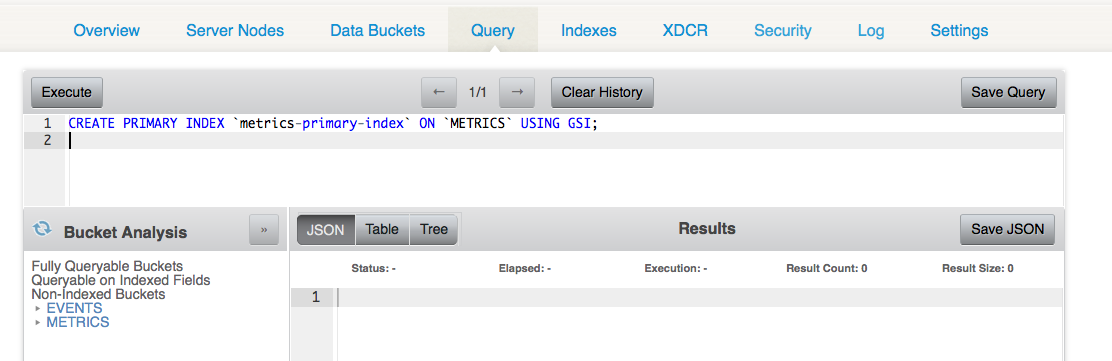
- Check if the index exists:
SELECT * FROM system:indexes WHERE name="metrics-primary-index"; Delete all events documents from the Metrics bucket:
DELETE FROM METRICS m WHERE REGEX_LIKE(uuid, "[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}")Delete push notifications:
DELETE FROM METRICS m WHERE REGEX_LIKE(uuid, "PUSH_N_+.*");
Migration is completed!
Opinions expressed by DZone contributors are their own.
Comments