Migrating Monolith Application to Microservices
Migrating a monolith application to microservices is time and resource-consuming and needs proper planning. This guide outlines the details of the migration process.
Join the DZone community and get the full member experience.
Join For FreeOver the years, I have worked with various Monolith applications and migrated a few of them to micro-services. I am going to write about what I learned and the strategy I used from my experience for a successful migration. In this post, I’ll use AWS for the reference, but the underlying principle will remain the same and can be used for any type of infrastructure.
The Monolith
A monolith is a large code repository with all the functionality implemented in a single place. This makes it complex and hard to maintain as application features and complexity increase. The code repository contains not only all the core logic to support related functionality but also code to support unrelated functionality. Even a minor bug fix or feature release will need testing to complete the application. The main pains I have faced are:
- Collaboration: There are the 'n' number of engineers working on a single repository. Due to this, there are high chances of merge conflict, which leads to an unnecessary burden on fixing the conflict rather than focusing on core development, thus slowing the pace of feature release.
- Bugs: With time, separation of concerns, code quality, and best practices fade away. Due to this, there are high chances of introducing bugs for unrelated features. Oftentimes, we do a sanity test for core functionality and miss these bugs or find ourselves surprised to see a bug for distantly unrelated changes.
- Time to production: The pace of innovation is hampered by various factors in a monolith system. In the case of a full CI/CD system and all tests in place, due to the size of the repository and tests, it takes time for dev testing, integration testing, etc., and release in production.
- Tech stack: A monolith system is implemented in a single tech stack, which limits the flexibility to adapt to emerging technology. Also, this introduces a learning curve.
- Fault isolation: A monolith system has all the components tied together, and failure in one module/component could lead to complete system failure.
- Time to fix: Sometimes, It’s not easy to identify a bug and fix it. As different components are tied together, there are chances a change in one module causes an issue in another module. This increases the time to debug, fix, and apply the patch to the production.
- Scalability: Scaling is not always an easy task in terms of time and cost in a monolith system. As a monolith has all the components together, there is a high chance some of the components/code block is heavily utilized while other are less. Due to this, If some component requires horizontal scaling, the whole system needs scaling.
There are other issues than the one mentioned above. Having said that, A monolith is not always a bad option, and there are various advantages:
- Implement fast, fail fast: In a fast-paced environment where there is no liberty to follow all the best practices and wait to implement a proper software application to test its product market fit, It’s always preferred to implement the MVP and do a UAT to understand PMF.
- Development: As monolith systems have all the components implemented in a single codebase, there is no overhead of inter-service communication/collaboration, and they are implemented faster.
- Operational overhead: There will be only one system to take care of. It is easy to implement alarm monitors and ensure a healthy application. This reduces the operational overhead of maintaining various services as well.
- Performance: Having all the code in one place, the operations could be faster. This, again, depends on the size and components of the monolith as well.
These advantages are on a case-to-case basis and highly depend on the magnitude of features a monolith has implemented.
Typical Monolith Flow
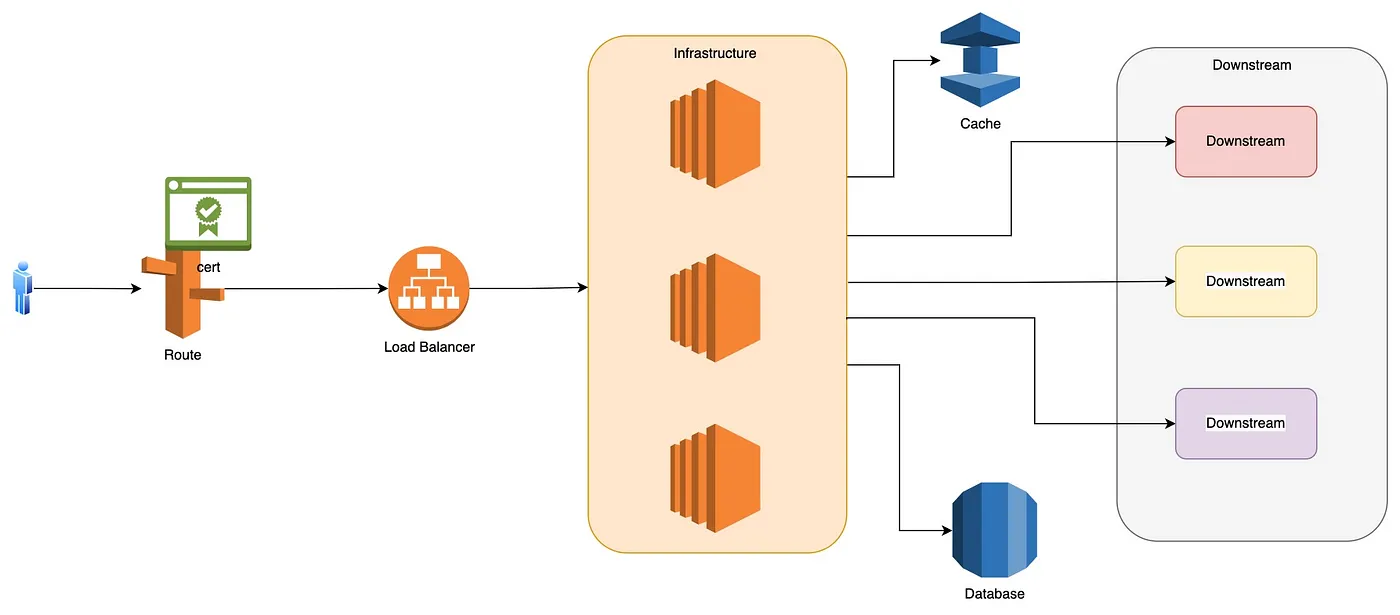
- The infrastructure hosting the application is backed by a load balancer
- A DNS mapping redirects the interaction to the infrastructure, which then invokes the business logic
- A single database is implemented to persist data
- For optimization, there can be a cache layer
- In order to complete the user request, there could be interactions between various downstream systems, and orchestration is managed within the infrastructure layer
This simplifies a lot of things like:
- Routing: All the traffic routes to a single piece of code running on a single or multiple infrastructure
- Database: No need to worry about data isolation, data sharing, etc. The data is accessed by a single application.
- Authn and Authz: A single point of auth implementation is easy to implement and manage.
The Microservices
In recent years, the microservice pattern has become popular and proved itself. It is easier to implement, manage, contribute, and scale these services. A microservice can be as small as a single API to multiple co-related functionality APIs. There are various benefits of using microservices like:
- Ease of development: It’s faster to develop, deploy, test, and manage a microservice. Related functionality can be clubbed together and developed independently.
- Debugging: Easier to debug, fix and deploy.
- Scalability: As required, different microservices can be scaled without impacting others.
- Tech stack: Flexibility in choosing different stacks to implement different functionality
There are other benefits as well. Having said that, Microservices are not all about benefits, but there are pitfalls too, like:
- Cost: Each service runs on independent infrastructure, which could lead to a higher cost
- Operation: There will be more and more operational overhead associated with more and more microservices
- Dependency: A microservice can depend on a lot of other microservices, which could lead to latency, authn, authz, isolation challenges
- Data consistency: Each microservice can have its own data stores. Data synchronization has its own issue in a distributed system.
Typical Microservice Flow
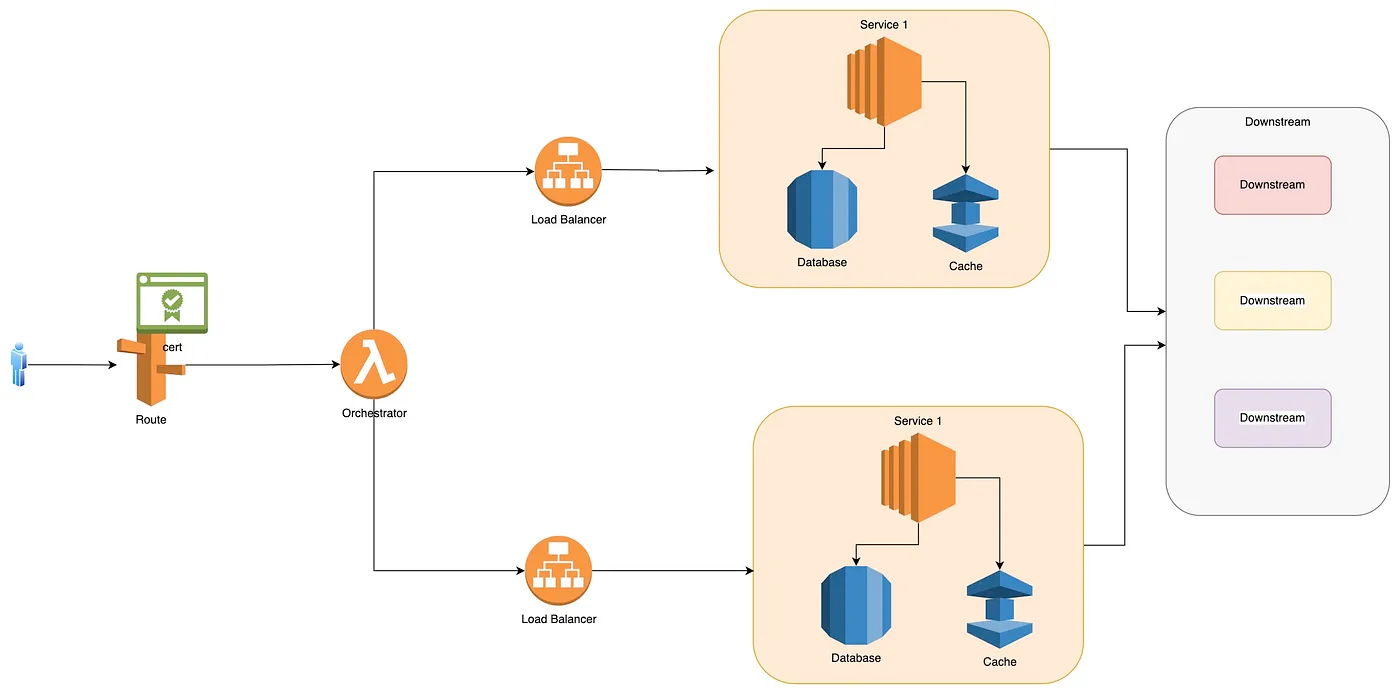
Migration Strategy
Migrating a monolith system to a microservice is not an easy and simple task. Before proceeding, A complete understanding of the monolith system in terms of code, functionality, dependencies, etc., is needed. Once documented:
- Identify common pieces of functionality that could go together. This will help you design the various microservices needed. Once identified, you can design individual services independently.
- Once you’ve identified the various microservices needed, you might need an orchestration layer. For example, earlier, a single endpoint was enough for a webpage to interact with a monolith, but with microservices, each of them will have separate endpoints. I prefer the BFF (Backend For Frontend) orchestration layer, which will orchestrate calls from the front end to different microservices.
- Authentication and authorization is a very important aspect of the application. With microservices, it will be the responsibility of each microservice to authenticate and authorize. Identify an auth mechanism to protect each microservice.
- Data storage is another aspect that needs proper investigation. It is recommended to isolate the related data in each microservice, but there could be cases when complete isolation is not possible. In such a scenario, identify such kind of data and have a proper implementation plan to mitigate any race conditions, data leakage, data sharing, etc.
- There could be common functionality like reading from the database, writing to the database, reading from the cache, etc., which can be abstracted into a common library and used in these microservices.
- Set up a common coding practice. With various different services, there could be a possibility of different coding conventions or practices in different services. Setting up a common ground will make it standard across various microservices.
- Release planning is another important aspect. This includes rollout strategy, identifying UAT customers, test plan, rollback plan, etc.
- Canaryservice is very important for your migration. This will provide a clear picture of your microservice health.
- Comparator service is another important piece to have. Design a service that will route your traffic to both monolith and microservice. This service will compare results from both monolith and microservices for data accuracy to avoid any security incident of over-exposing information. Once you have enough confidence, the routing can be changed from monolith to microservices.
- Operation health and rollback strategy are other points to consider. Have a well-defined runbook for incidents and mitigation plans.
- Implement Scaling for each microservice to avoid any downtime
Published at DZone with permission of Pranav Kumar Chaudhary. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments