Mixtral: Generative Sparse Mixture of Experts in DataFlows
Explore the use of a new type of GenAI LLM with streaming pipelines in this tutorial about how to build a real-time LLM flow with Mixtral AI's new open model.
Join the DZone community and get the full member experience.
Join For Free“The Mixtral-8x7B Large Language Model (LLM) is a pre-trained generative Sparse Mixture of Experts.”
When I saw this come out it seemed pretty interesting and accessible, so I gave it a try. With the proper prompting, it seems good. I am not sure if it’s better than Google Gemma, Meta LLAMA2, or OLLAMA Mistral for my use cases.
Today I will show you how to utilize the new Mixtral LLM with Apache NiFi. This will require only a few steps to run Mixtral against your text inputs.

This model can be run by the lightweight serverless REST API or the transformers library. You can also use this GitHub repository. The context can have up to 32k tokens. You can also enter prompts in English, Italian, German, Spanish, and French. You have a lot of options on how to utilize this model, but I will show you how to build a real-time LLM pipeline utilizing Apache NiFi.
One key thing to decide is what kind of input you are going to have (chat, code generation, Q&A, document analysis, summary, etc.). Once you have decided, you will need to do some prompt engineering and will need to tweak your prompt. In the following section, I include a few guides to help you improve your prompt-building skills. I will give you some basic prompt engineering in my walk-through tutorial.
Guides To Build Your Prompts Optimally
The construction of the prompt is very critical to make this work well, so we are building this with NiFi.
Overview of the Flow
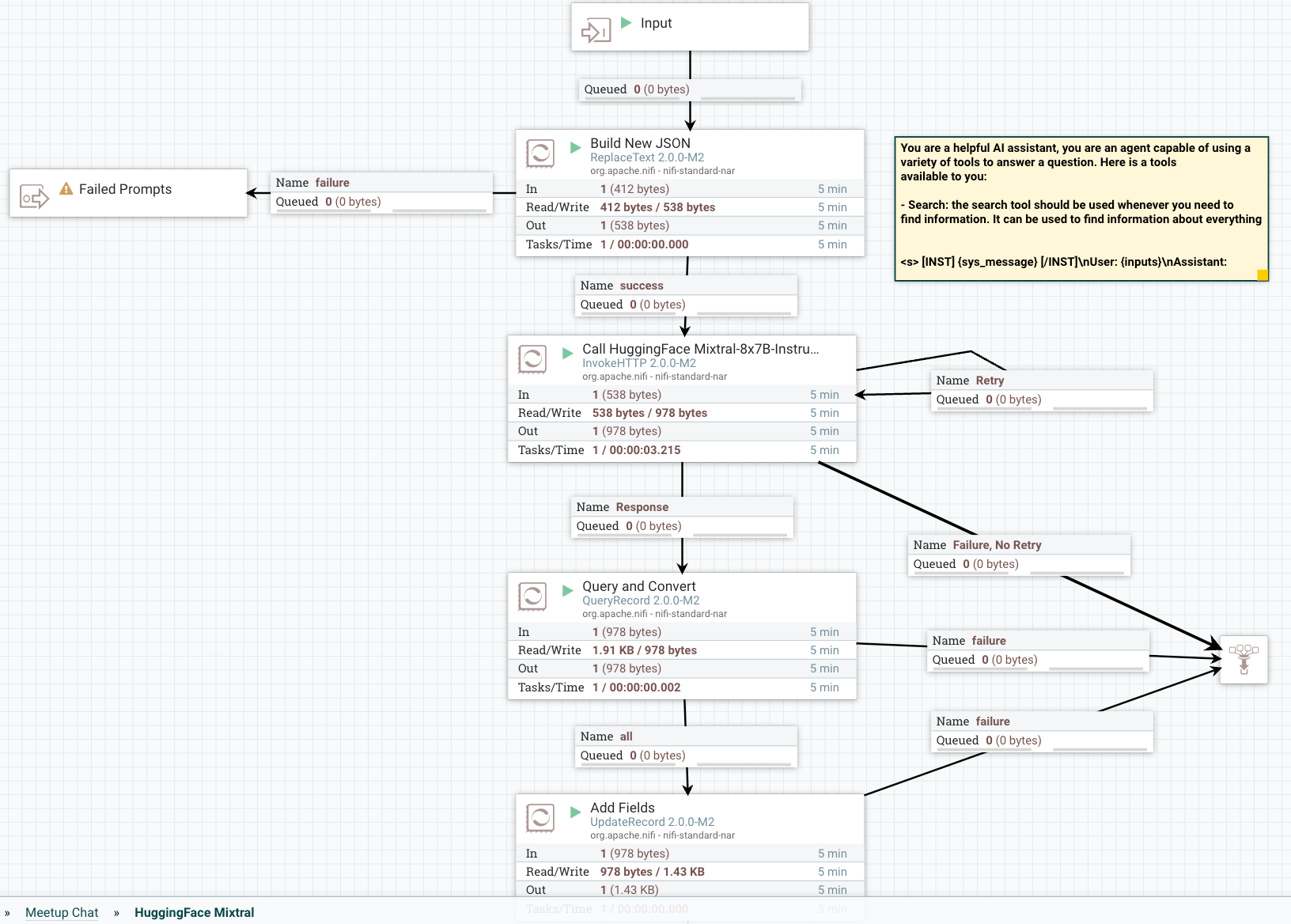
Step 1: Build and Format Your Prompt
In building our application, the following is the basic prompt template that we are going to use.
Prompt Template
{
"inputs":
"<s>[INST]Write a detailed complete response that appropriately
answers the request.[/INST]
[INST]Use this information to enhance your answer:
${context:trim():replaceAll('"',''):replaceAll('\n', '')}[/INST]
User: ${inputs:trim():replaceAll('"',''):replaceAll('\n', '')}</s>"
}
You will enter this prompt in a ReplaceText processor in the Replacement Value field.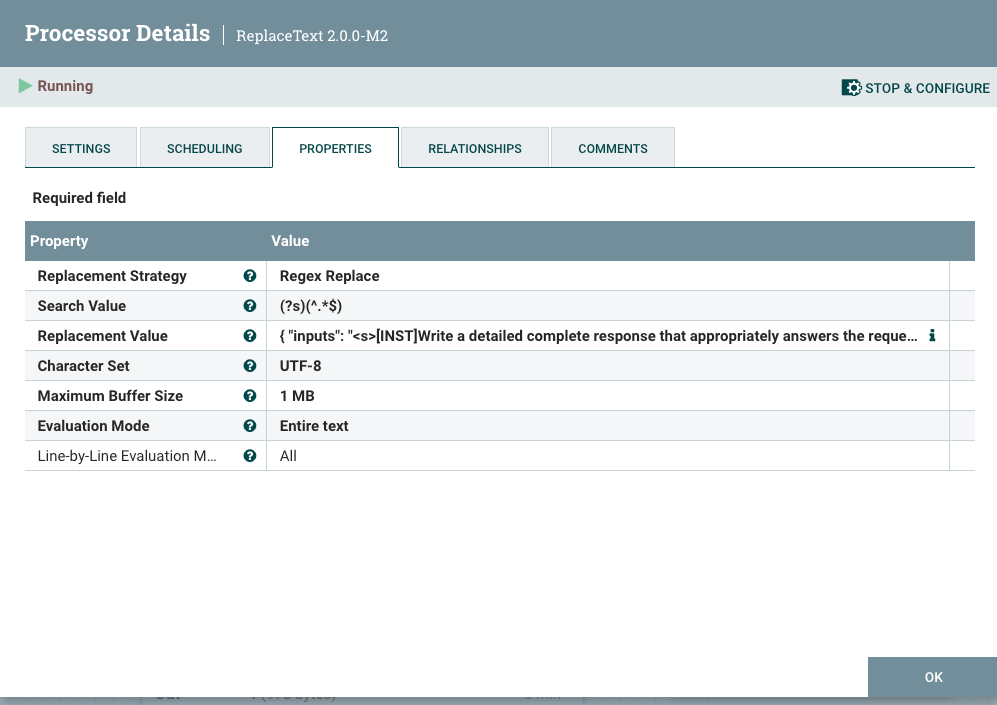
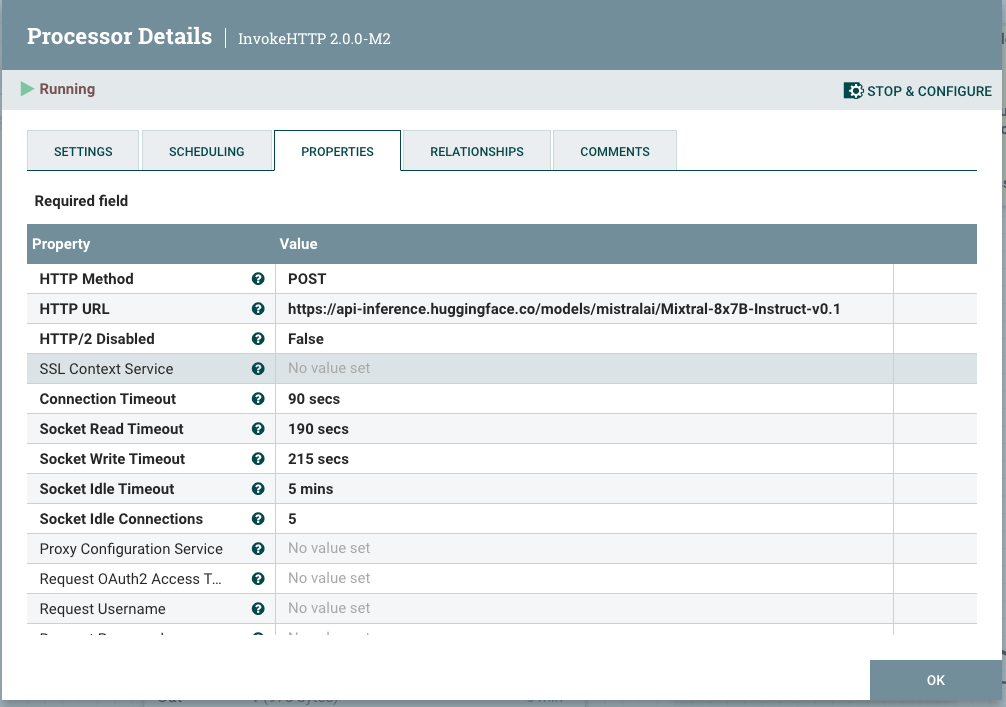
Step 2: Build Our Call to HuggingFace REST API To Classify Against the Model
Add an InvokeHTTP processor to your flow, setting the HTTP URL to the Mixtral API URL.
![Add an InvokeHTTP processor to your flow, setting the HTTP URL to the Mixtral API URL]() Step 3: Query To Convert and Clean Your Results
Step 3: Query To Convert and Clean Your Results
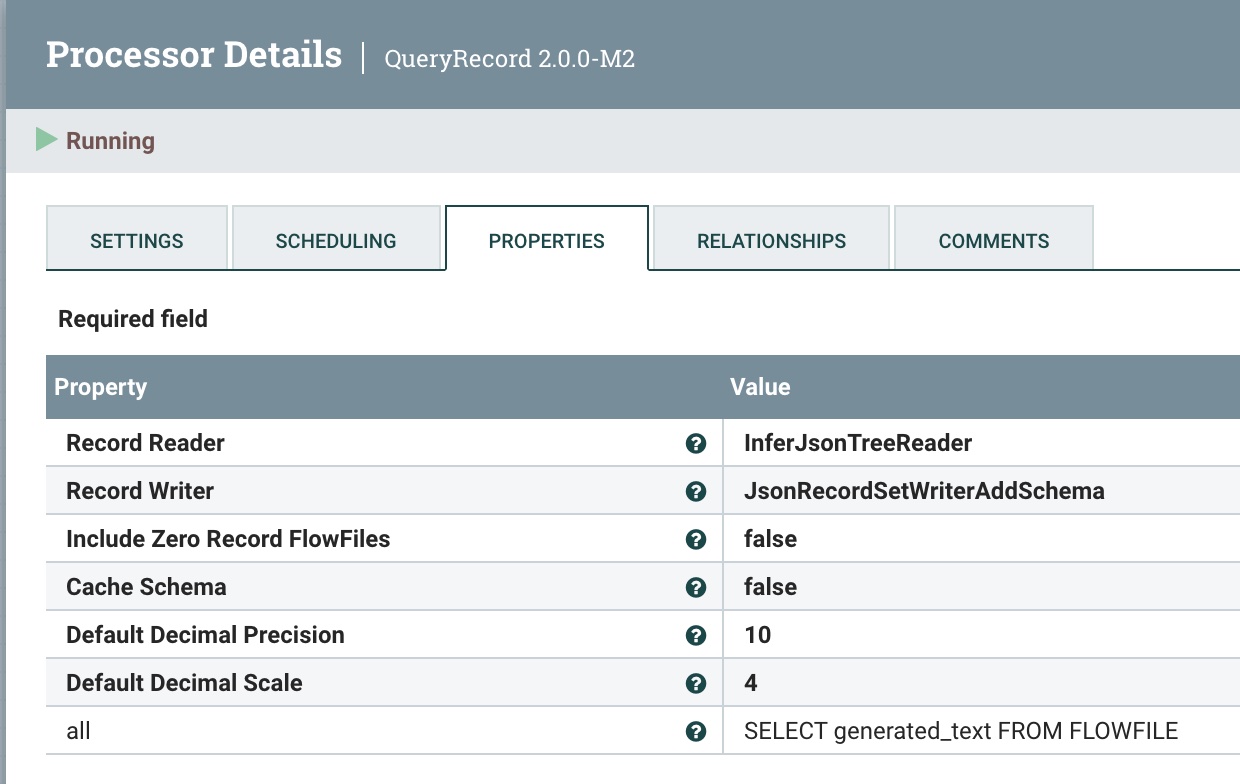
 Step 3: Query To Convert and Clean Your Results
Step 3: Query To Convert and Clean Your ResultsWe use the QueryRecord processor to clean and convert HuggingFace results grabbing the generated_text field.
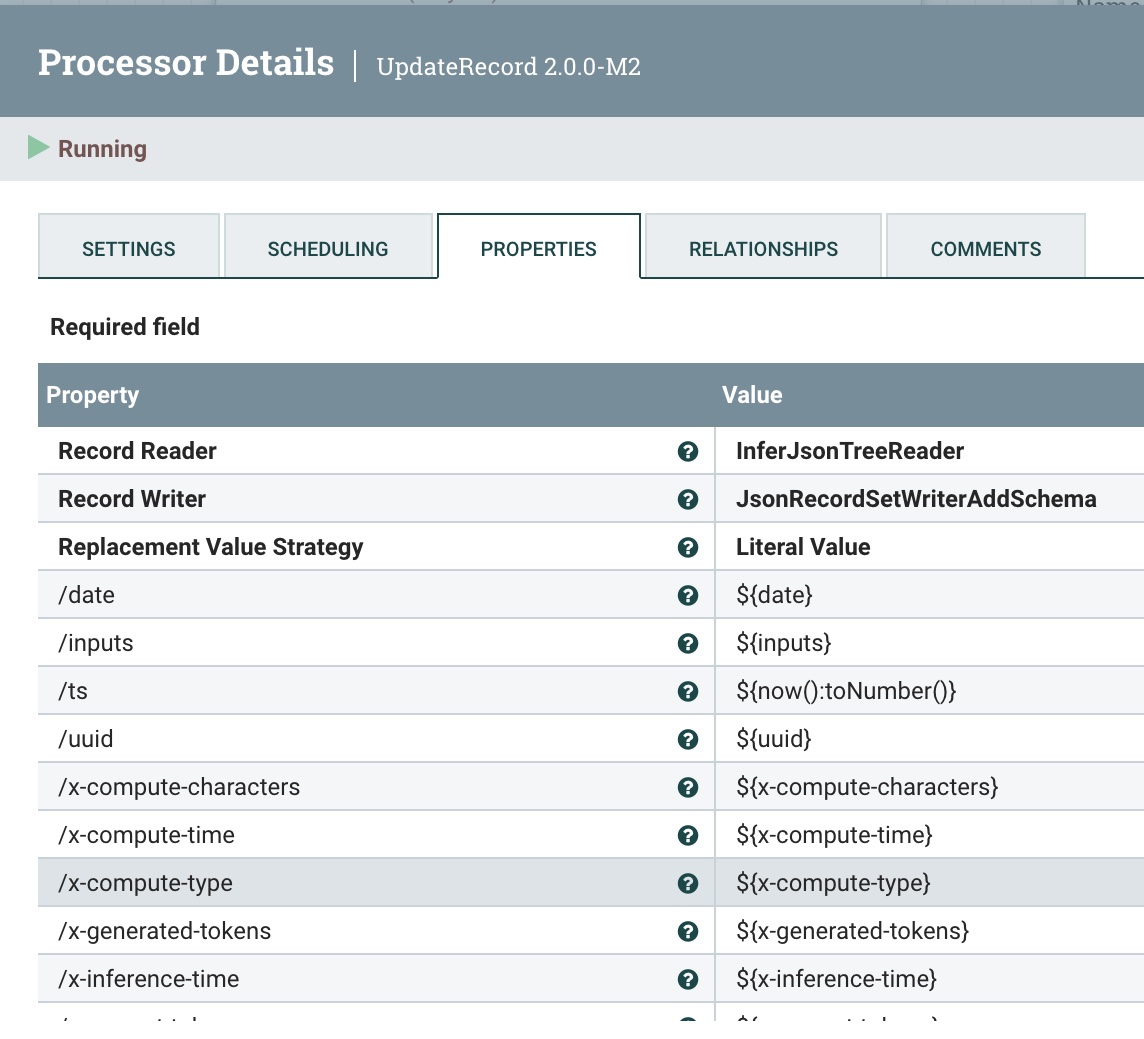
Step 4: Add Metadata Fields
We use the UpdateRecord processor to add metadata fields, the JSON readers and writers, and the Literal Value Replacement Value Strategy. The fields we are adding are adding attributes.
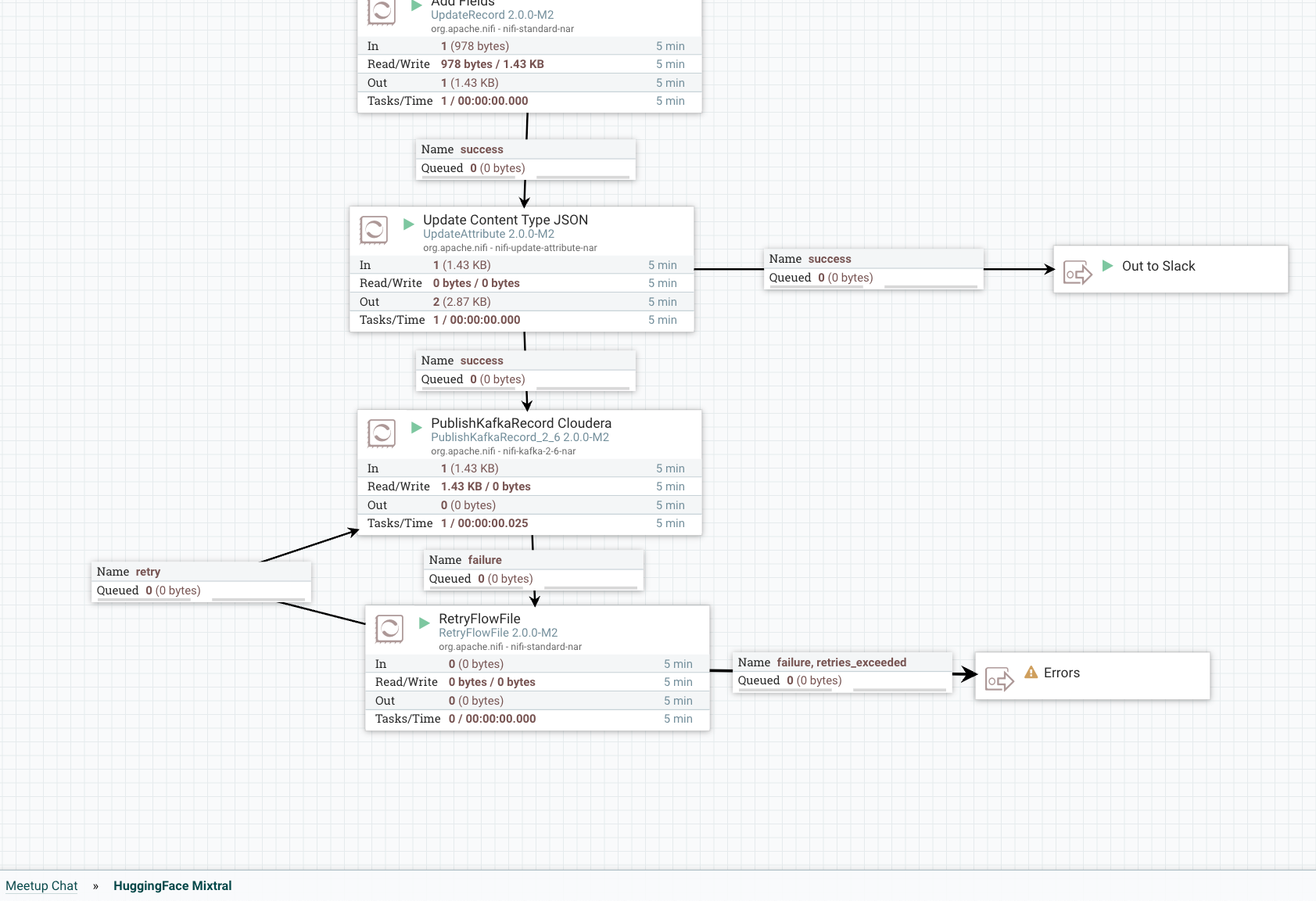
Overview of Send to Kafka and Slack:
![Overview of Send to Kafka and Slack]()
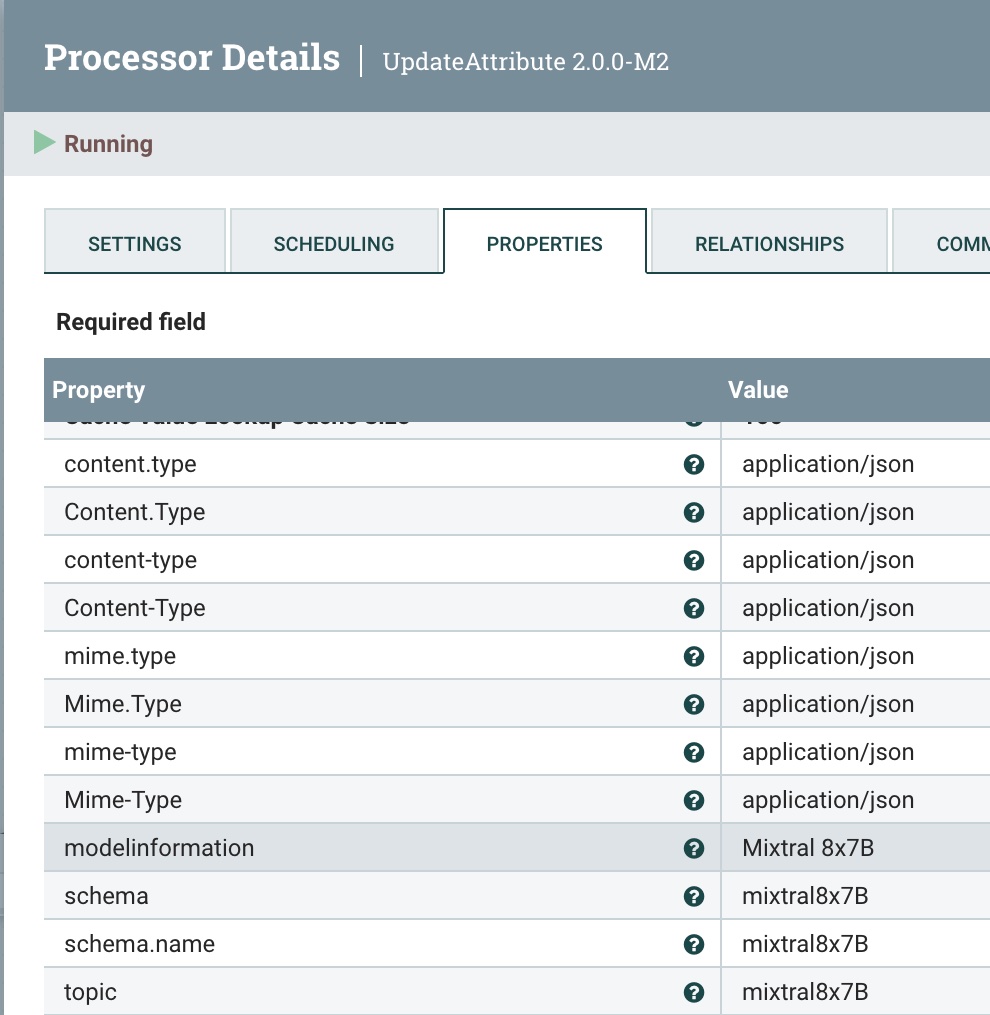
Step 5: Add Metadata to Stream
We use the UpdateAttribute processor to add the correct "application/json Content Type", and set the model type to Mixtral.
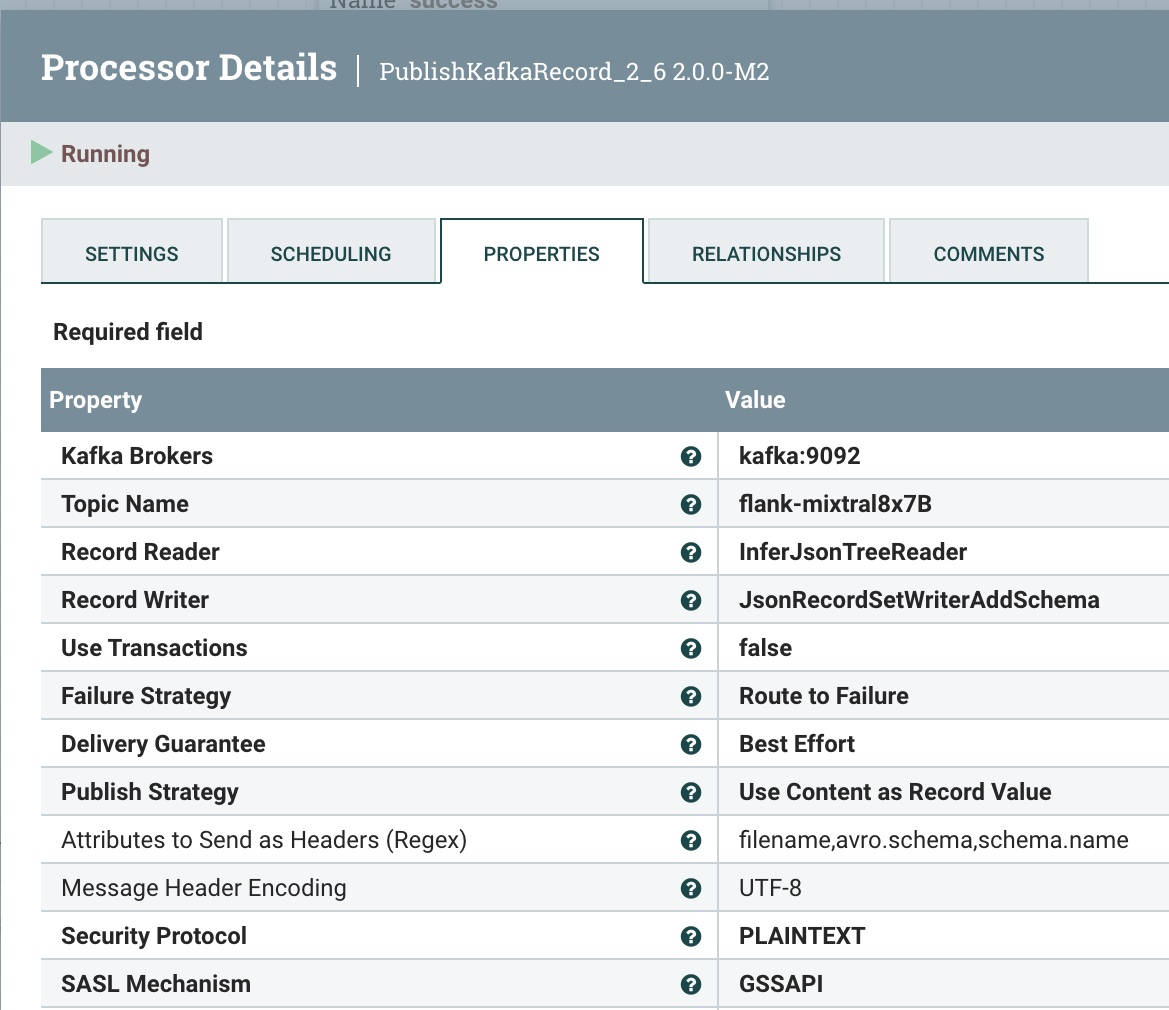
Step 6: Publish This Cleaned Record to a Kafka Topic
We send it to our local Kafka broker (could be Docker or another) and to our flank-mixtral8x7B topic. If this doesn't exist, NiFi and Kafka will automagically create one for you.
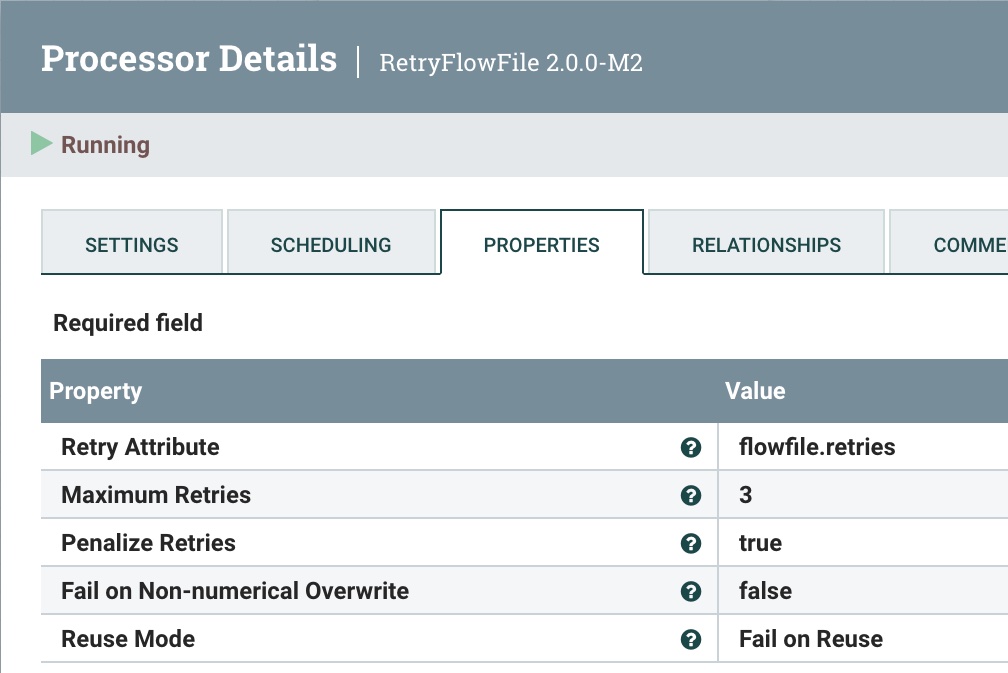
Step 7: Retry the Send
If something goes wrong, we will try to resend three times, then fail.
Overview of Pushing Data to Slack:
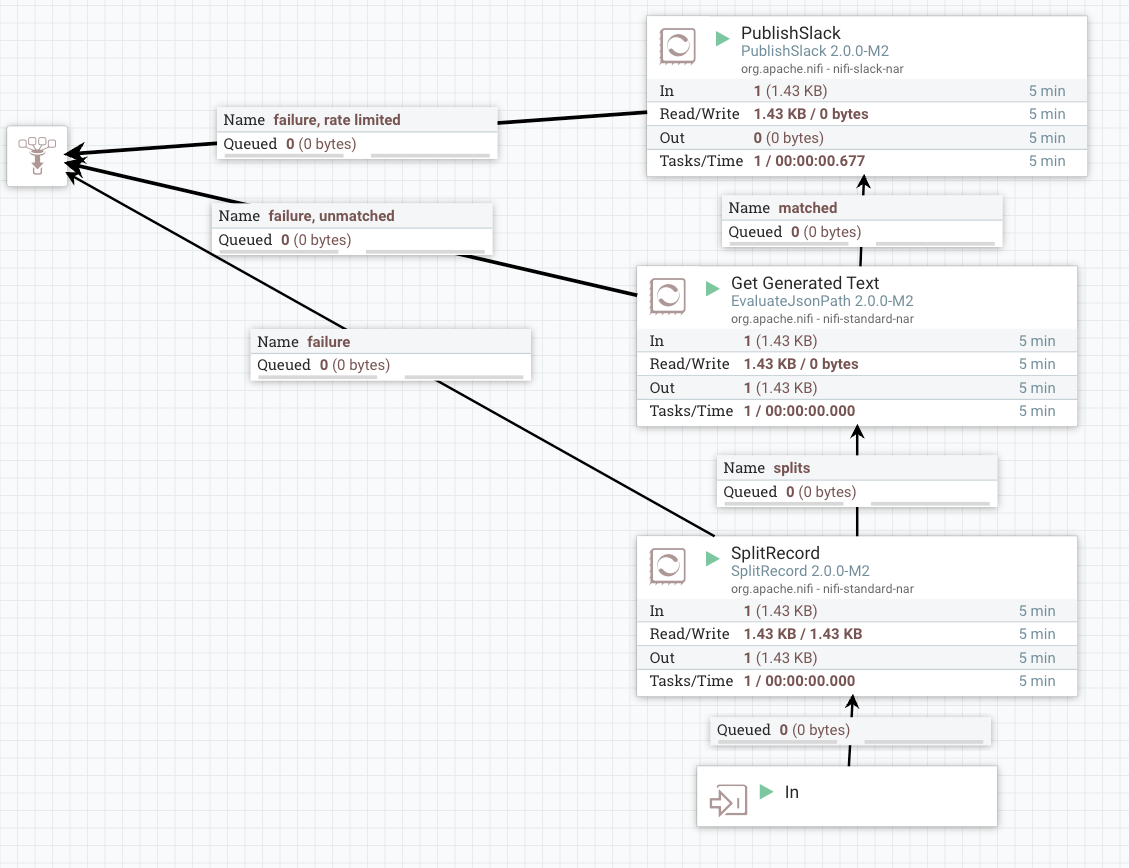
Step 8: Send the Same Data to Slack for User Reply
The first step is to split into a single record to send one at a time. We use the SplitRecord processor for this.
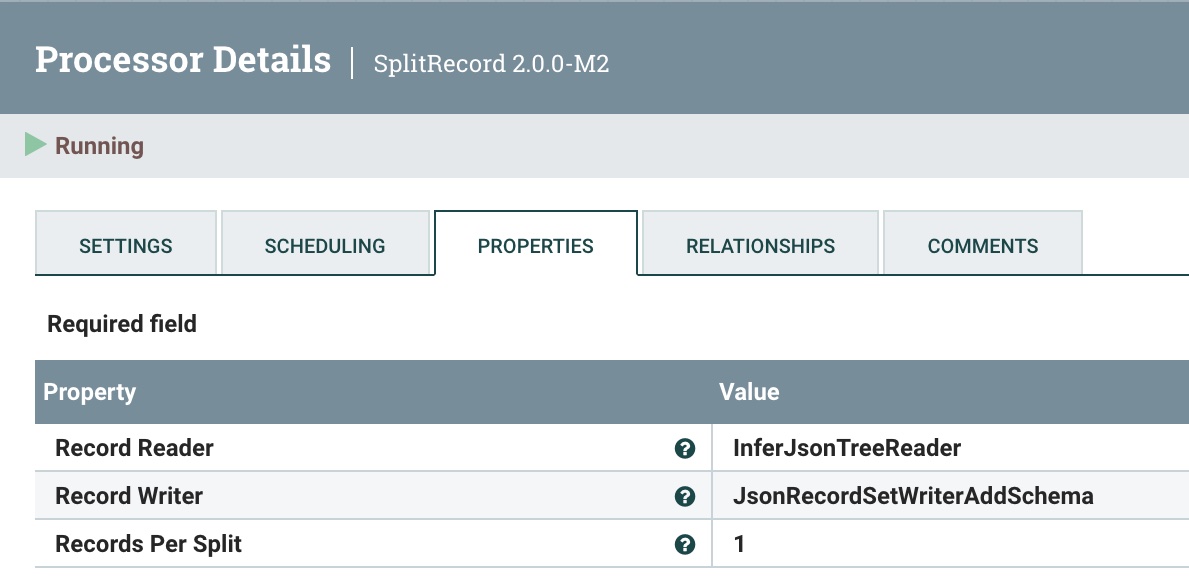
As before, reuse the JSON Tree Reader and JSON Record Set Writer. As usual, choose "1" as the Records Per Split.
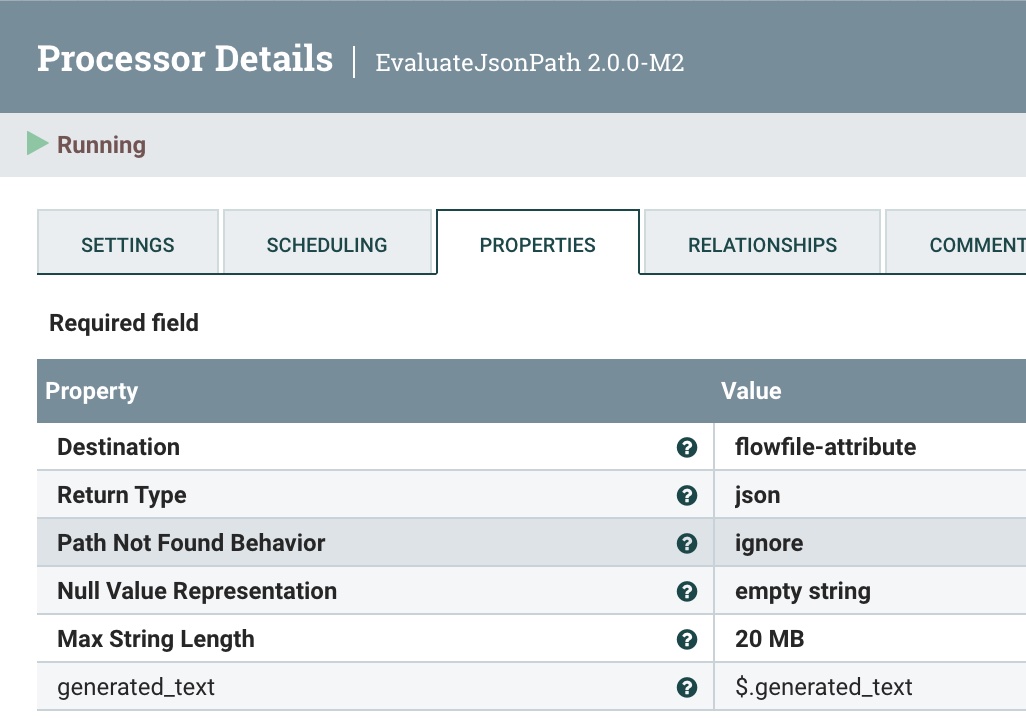
Step 9: Make the Generated Text Available for Messaging
We utilize EvaluateJsonPath to extract the Generated Text from Mixtral (on HuggingFace).
Step 10: Send the Reply to Slack
We use the PublishSlack processor, which is new in Apache NiFi 2.0. This one requires your Channel name or channel ID. We choose the Publish Strategy of Use 'Message Text' Property. For Message Text, use the Slack Response Template below.
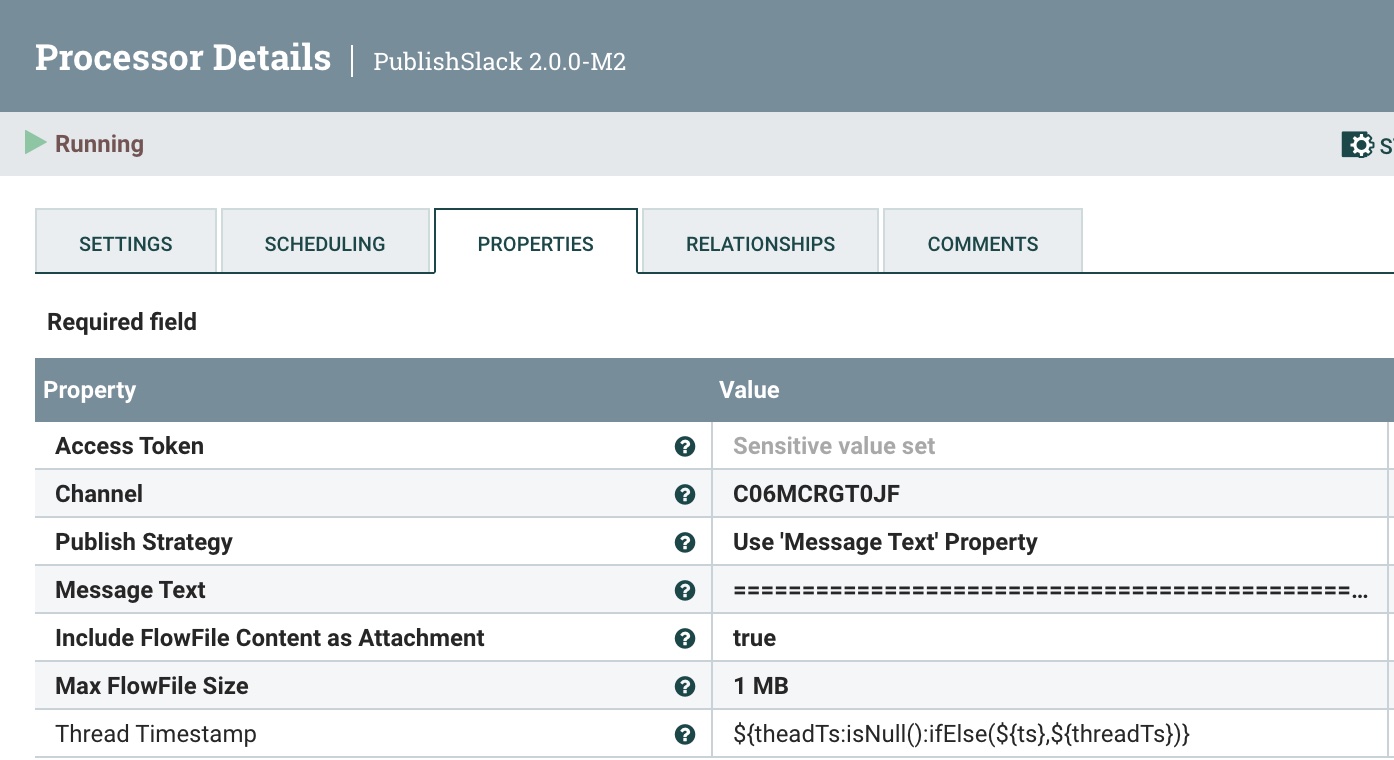
For the final reply to the user, we will need a Slack Response template formatted for how we wish to communicate. Below is an example that has the basics.
Slack Response Template
===============================================================================================================
HuggingFace ${modelinformation} Results on ${date}:
Question: ${inputs}
Answer:
${generated_text}
=========================================== Data for nerds ====
HF URL: ${invokehttp.request.url}
TXID: ${invokehttp.tx.id}
== Slack Message Meta Data ==
ID: ${messageid} Name: ${messagerealname} [${messageusername}]
Time Zone: ${messageusertz}
== HF ${modelinformation} Meta Data ==
Compute Characters/Time/Type: ${x-compute-characters} / ${x-compute-time}/${x-compute-type}
Generated/Prompt Tokens/Time per Token: ${x-generated-tokens} / ${x-prompt-tokens} : ${x-time-per-token}
Inference Time: ${x-inference-time} // Queue Time: ${x-queue-time}
Request ID/SHA: ${x-request-id} / ${x-sha}
Validation/Total Time: ${x-validation-time} / ${x-total-time}
===============================================================================================================
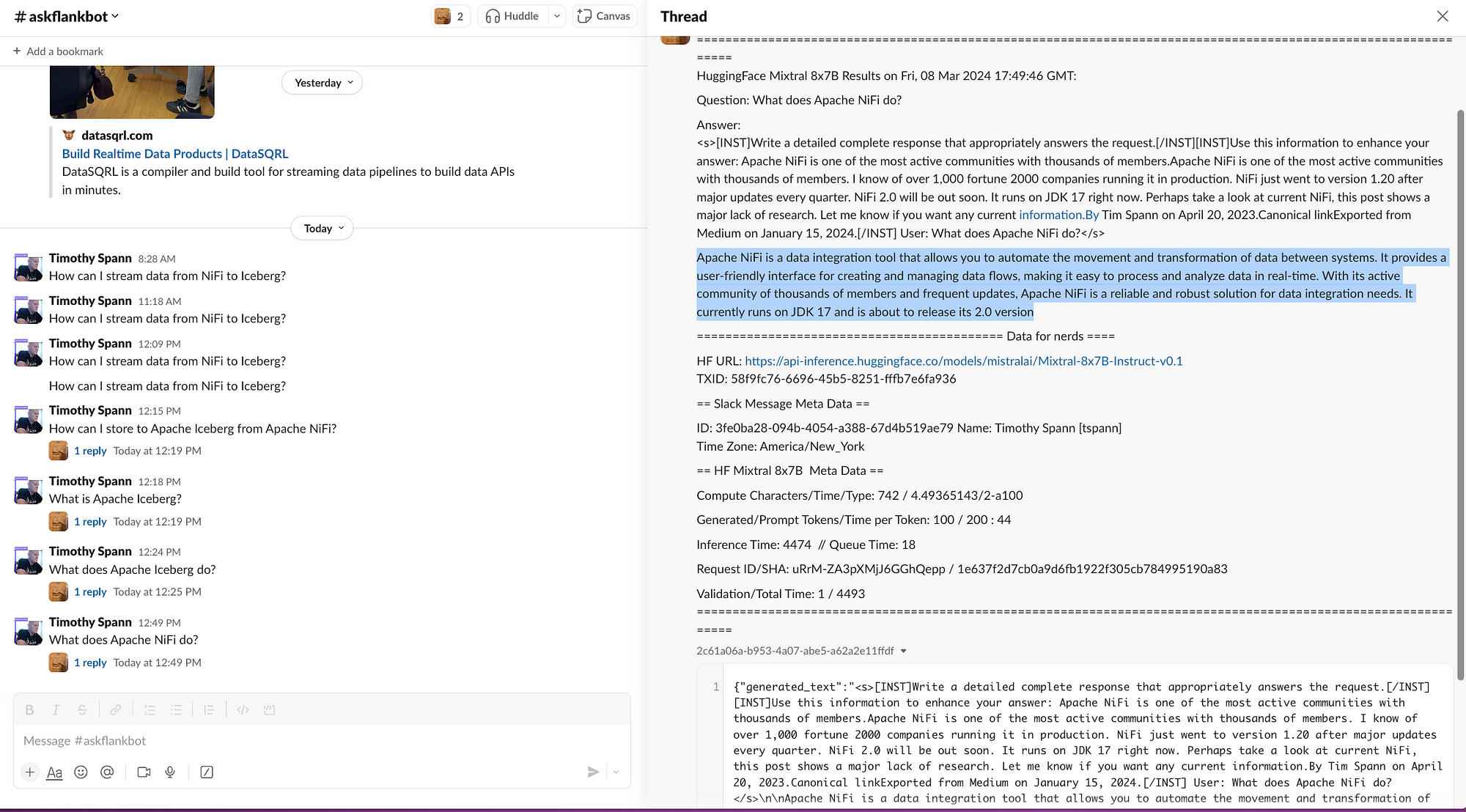
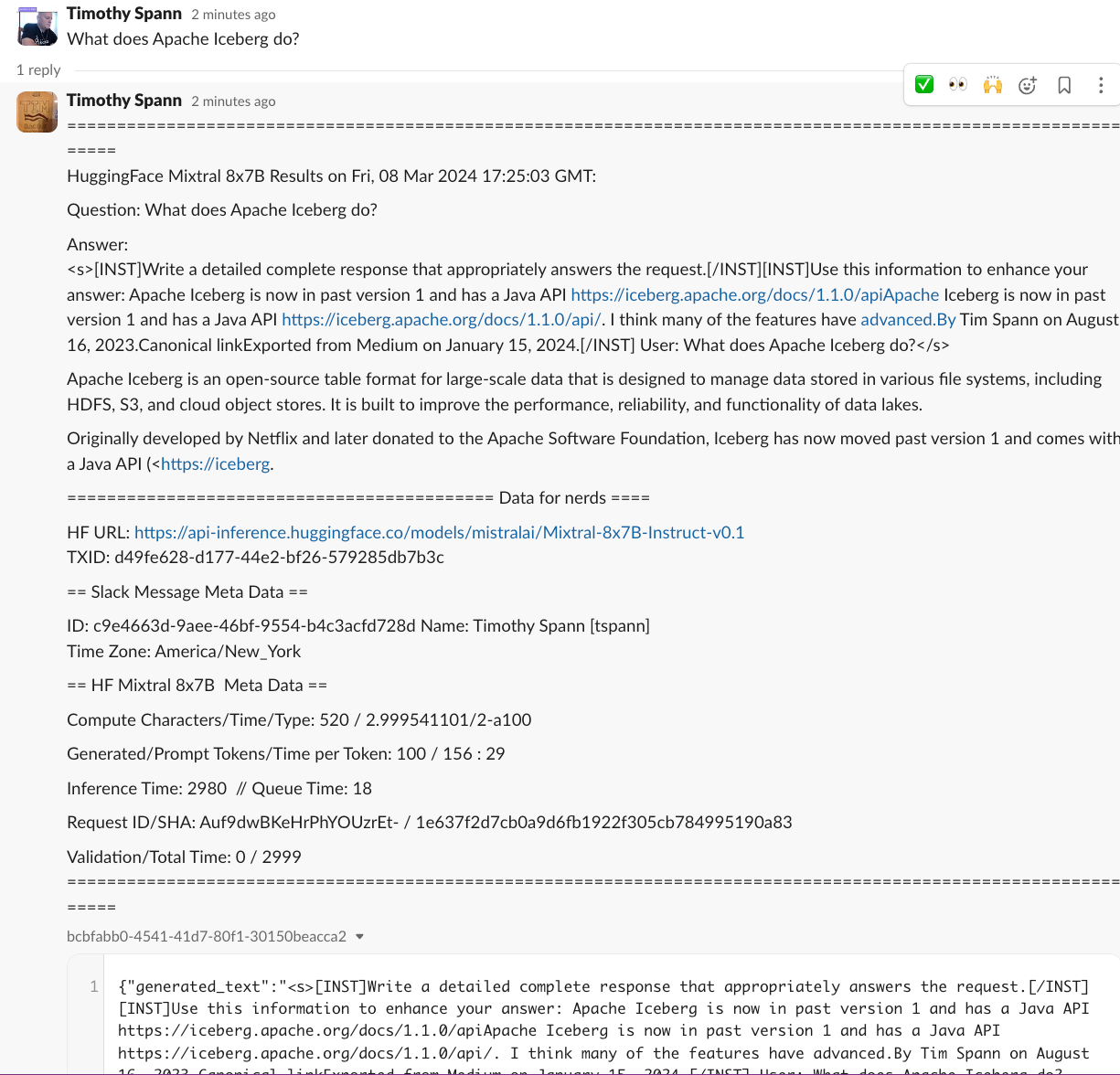
You have now sent a prompt to Hugging Face, had it run against Mixtral, sent the results to Kafka, and responded to the user via Slack.
We have now completed a full Mixtral application with zero code.
Conclusion
You have now built a full round trip utilizing Apache NiFi, HuggingFace, and Slack to build a chatbot utilizing the new Mixtral model.
Summary of Learnings
- Learned how to build a decent prompt for HuggingFace Mixtral
- Learned how to clean up streaming data
- Built a HuggingFace REST call that can be reused
- Processed HuggingFace model call results
- Send your first Kafka message
- Formatted and built Slack calls
- Built a full DataFlow for GenAI
If you need additional tutorials on utilizing the new Apache NiFi 2.0, check out:
For additional information on building Slack bots:
- Building a Real-Time Slackbot With Generative AI
- Building an LLM Bot for Meetups and Conference Interactivity
Also, thanks for following my tutorial. I am working on additional Apache NiFi 2 and Generative AI tutorials that will be coming to DZone.
Resources
- Mixtral of Experts
- Mixture of Experts Explained
- mistralai/Mixtral-8x7B-v0.1
- Mixtral Overview
- Invoke the Mixtral 8x7B model on Amazon Bedrock for text generation
- Running Mixtral 8x7b on M1 16GB
- Mixtral-8x7B: Understanding and Running the Sparse Mixture of Experts by Mistral AI
- Retro-Engineering a Database Schema: Mistral Models vs. GPT4, LLama2, and Bard (Episode 3)
- Comparison of Models: Quality, Performance & Price Analysis
- A Beginner’s Guide to Fine-Tuning Mixtral Instruct Model
Published at DZone with permission of Tim Spann. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments