MLOps Is Overfitting. Here’s Why
Is ML a unique practice that requires its own DevOps approach and a matching infrastructure? A short history of the MLOps category helps to clarify this.
Join the DZone community and get the full member experience.
Join For FreeVC surveys show there are hundreds of companies active today that define themselves as being part of the MLOps category.
MLOps systems provide the infrastructure that allows ML practitioners to manage the lifecycle of their work from development to production in a robust and reproducible manner. MLOps tools may cover E2E needs or focus on a specific phase (e.g., Research/Development) or artifact (e.g., Features) in the process.
The world of data involves a continuum of data practitioners, from analysts using mainly ad hoc SQL statements to PhDs running proprietary algorithms.
Is there one DevOps approach to rule them all, or is ML a unique practice that requires its own approach for best practices and a matching infrastructure?
To answer this question, we will look into the basis of DevOps and how DataOps is a natural expertise within DevOps that suits data practitioners' needs. Later, we will look into the needs of ML and try to understand if and how it may differ from DataOps.
Last but not least, we will look at the question of how much infra an ML practitioner should handle. Is it different from any other data practitioner? Where does it stand in comparison to software engineers?
This question is relevant to the question at hand, as it drives the need for Ops provided to the practitioner.
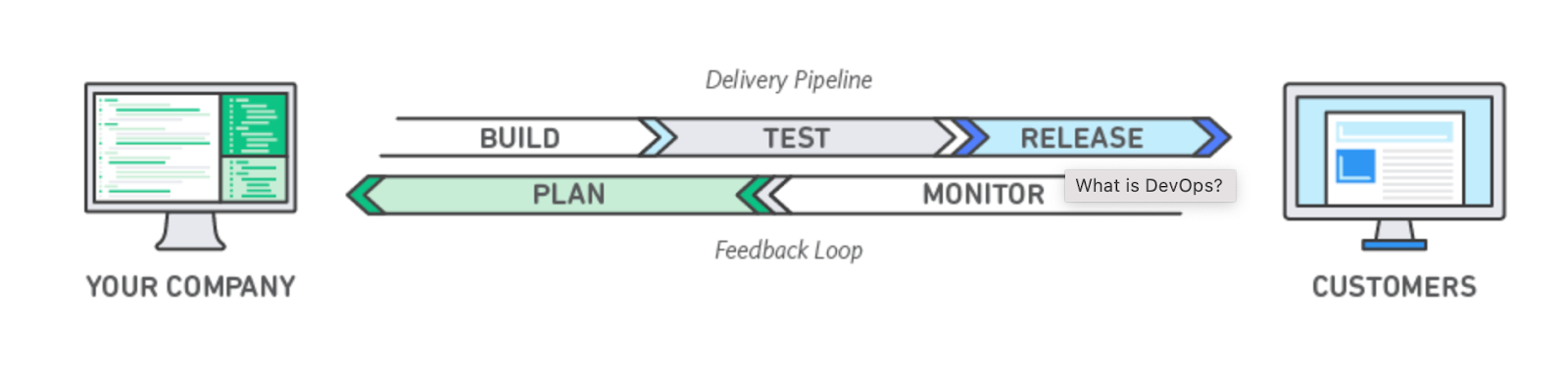
What’s DevOps?
“DevOps is a methodology in the software development and IT industry. Used as a set of practices and tools, DevOps integrates and automates the work of software development (Dev) and IT operations (Ops) as a means for improving and shortening the systems development life cycle.”
DevOps is complementary to agile software development; several DevOps aspects came from the agile way of working.”
Let’s break it down. The agile methodology is part of the DevOps methodology; it relies on the ability to maintain a short feedback loop between the product designers and the users.
To maintain a short feedback loop, one must have an efficient software delivery lifecycle from development to production. The infrastructure and tools required to maintain this process are under the responsibility of the DevOps team.
So, efficiency is the name of the game.
In a nutshell, the main components would be:
- Development environment: A development environment that allows collaboration and the testability of new or changed code.
- Continuous integration: The ability to continuously add new/changed code to the code base while maintaining its quality.
- Staging: to ensure the quality of the system, including new/changed functionality, before deploying it into production by setting up and running quality tests in an environment similar to production.
- Continuous deployment: The ability to deploy new/changed functionality into production environments.
- Monitoring: Observing the health of production and the ability to quickly recover from issues by rolling back.
- Modularity: The ability to easily add components, such as new services, into production while maintaining production stability and health monitoring.
There could be many job titles, depending on the organization structure (DevOps/SRE/Production Engineering), yet their responsibility stays the same.
This function is responsible for providing an infrastructure to move code from development to production. The product engineering teams may participate in choosing some of the tools that are more specific to their expertise, such as aspects of their development environment.
To support this goal and allow those agile processes, software engineers are trained in a variety of tools, including Source Control, such as Git, and automation tools, such as Jenkins, Unit, and Integration testing platforms.
Any software engineer knows that the most critical “on-the-job” training software engineers get is around understanding the life cycle management of the application and working with the tools that support it. Your productivity is much higher once you master that, and once you do, it’s a natural part of your day-to-day work.
What’s DataOps?
DataOps is DevOps for data-intensive applications. Those applications rely on Data Pipelines to produce the derivatives of the data that are the heart of the applications.
Examples of data-intensive applications include:
- Internal BI systems,
- Digital health applications that rely on large data sets of patients to improve the diagnostics and treatment of diseases,
- Autonomous driving capabilities in cars,
- Optimization of manufacturing lines,
- Generative AI engines,
- and many more...
The goal of a DataOps team is similar to that of a DevOps team, but their technology stack includes expertise in the technologies that allow data practitioners to achieve a short feedback loop.
Those technologies include distributed storage, distributed compute engines, distributed ingest systems, orchestration tools to manage data pipelines, and data observability tools to allow quality testing and production monitoring of the data aspects of a data-intensive application.
In a nutshell, this expertise will allow:
- Development Environment: A development environment that allows collaboration and the testability of new or changed data pipelines. The infra will include not only the management of the functional code but also the pipeline code and the data.
- Continuous Integration of Code: The ability to continuously add new/changed code to the code base
- Continuous Integration of Data: The ability to continuously add new/changed Data to the Data set.
- Staging: to ensure the quality of the system with new/changed functionality before deploying it into production. This will include testing both code and data.
- Continuous Deployment: The ability to automatically deploy new/changed functionality or Data into production environments.
- The monitoring of the health of production and the ability to quickly recover from issues. This will include both the application and the data incorporated into it.
- The ability to easily add components, such as new services/data artifacts, into production while maintaining production stability and health monitoring.
MLOps vs. DataOps
In the context of DevOps and DataOps, MLOps is the case of DataOps that is aimed at the ML lifecycle.
Here, we are asked to answer the main question of this article. Is MLOps truly different from DataOps? And if so, how?
Since ML-based applications require code, data, and environment version control, Orchestration, and the provisioning of data technologies, their needs in those domains are similar to other data practitioners and fall well within DataOps as defined here.
The same is true for data quality tools and data monitoring tools. While those tools may be ML-specific in some parts of the testing, that is no different from the difference between the tools of a C++ developer vs. the tools of a JavaScript developer.
We don’t define those as different categories from DevOps, do we?
Note that the need for such tools is not in question, and the data quality and data monitoring categories will be successful, but they don’t change the DevOps paradigm or make MLOps an actual product category.
This brings us to where the difference really lies: in the development environment. This difference is known in DevOps, and it is real.
Every practitioner in software engineering has their own specific requirements for their development environment. Those needs come on top of the basic code and data version control and the well-configured notebook that is required by all.
For example, ML practitioners require a good experimentation management system, a good way to optimize hyperparameters, and a good way to create their training sets.
The training set! Oh, that is indeed a difference! Data scientists require the infrastructure to store and manage the tagging of the data they rely on to train their models.
While some of this infrastructure is data-general, such as the storage or database used to save the metadata of the tagging, some of it is extremely specific to the tagging process itself and to the management of the training sets.
Does this justify a new Ops category? I don’t think so. It would be the same as saying that an application that requires a graph database would need a new Ops category.
Why Did We Overfit MLOps?
In many discussions about the infrastructure needs of Data scientists, the question of their basic software skills is raised. Statements like “Don’t expect a data scientist to understand Git concepts,” “Data scientists can not create code that has proper logging, they’re not software engineers,” etc.
I resent that line of thinking, and I think it has brought us to overfit MLOps.
Data Scientists are highly skilled individuals who can quickly grasp concepts of version control and master the complexities of working with automation servers for CI/CD. As I mentioned above, Junior software engineers learn this on the job, and I believe that so should data scientists who intend to bring value to a commercial company. I feel we are creating a category of tools to solve a training gap for Data Scientists. This survey supports this opinion.
That said, the question of how much Ops software engineers should be exposed to is still open, and different organizations have different views on how DevOps is implemented within the organization.
What is common to all is the understanding that the DevOps team is responsible for providing infrastructure, and the software engineers should understand it, use it, and bring requirements to make sure it continuously improves.
When moving to data engineers, the expectation remains the same. Why should it change for ML engineers/Data Scientists?
Conclusion
Organizations with vast data operations (soon to be all organizations) should make sure their DevOps teams have data expertise to provide high-quality and general data infrastructure and best practices for all data practitioners while also making sure all data practitioners are well-educated on how to use this infrastructure to optimally manage their pipelines. In enterprises, that could definitely be a dedicated department.
Good practices and internal education may remove the need for overfitted tools that eventually limit the data practitioners' access to the much-needed flexibility offered by general Ops tools.
The advantage of an overfitted tool is that, in the short term, for a very simple system, it provides a one-stop shop for all needs.
Why work with our DevOps team if we can just buy this E2E tool? But in the long run, needs evolve from the simplified use cases, and the depth of expert systems is required. For example, for orchestration, instead of using E2E tools that offer simplified orchestration, among other things, companies will move to powerful orchestration systems such as Airflow, Prefect, or Dagster.
Opinions expressed by DZone contributors are their own.
Comments