Modern Enterprise Data Architecture
Learn modern enterprise data architecture perspectives, including solution approaches and architectural models to develop new-age solutions.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Data plays a vital role in conceptualizing the preliminary design for an architecture. You may want to decide the requirements for security, performance, and infrastructure to handle workload, scalability, and agility in design. In this case, you need to understand data models and how to handle architectural decisions, including data privacy and security, compliance requirements, data size to handle, and user handling requirements.
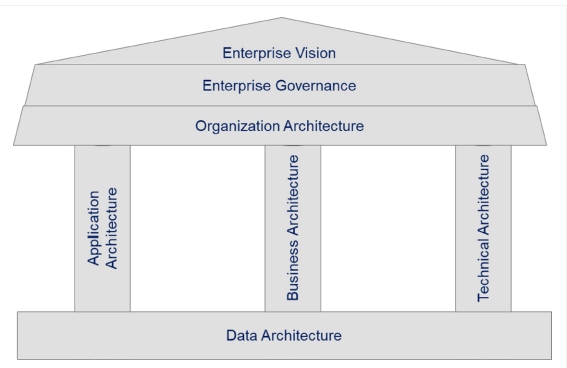
Figure 1: Data architecture as the foundational pillar for enterprise architecture
This is the reason that data-driven architecture is the driving factor for an enterprise design development. The modern enterprise architectures that are referred to in this article include microservices, cloud-native applications, event-driven solutions, and data-intensive solutions. The article intends to share modern enterprise data architecture perspectives, including solution approaches and architectural models to develop new-age solutions catering to velocity, veracity, volume, and variety of data handling services.
Polyglot Persistence and Database as a Service
A recent data architecture trend based on various case studies recommends the move toward polyglot persistence, which is a group of multiple types of data storage technologies for integrated architecture. Integrated architecture is needed to provide high performance for any type of data processing across different services. Typically used in cloud adoption, this kind of implementation is supported by Database as a Service (DBaaS). DBaaS is implemented for the following benefits:
- Cloud-based database management system (e.g., Amazon Aurora, Azure Cosmos DB, Google Spanner)
- High scalability
- Rapid provisioning
- Enhanced security in cloud architecture
- Suitable for large enterprise design
- Shared infrastructure
- Availability of monitoring and performance tuning tools
This type of polyglot-persistence-based microservices architecture helps to develop resilient, robust, and high-performing architecture to support variant types of data services for different microservices (see Figure 2).
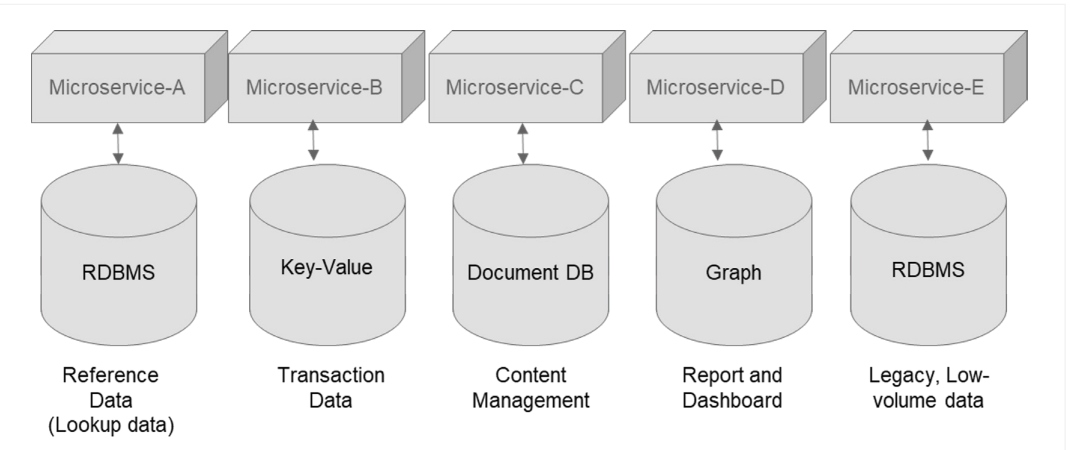
Figure 2: Example architecture using polyglot persistence
In the example above, each microservice handles data at different capacities and performance requirements. Hence, based on these data access requirements, the choice of database can be picked to cater to performance, scalability, and the optimal data model to be stored in the system. This leverages microservices to make cost-effective and agile architectures in a polyglot persistence model.
Data Modeling in Modern Data Architecture
In traditional architecture development, data modeling is the simple task of deriving data elements from requirements, depicting the relation between the entities through entity relationship (ER) diagrams, and defining the parameters (data types, constraints, validations) around the data elements. This means that data modeling is done as a single-step activity in a traditional architecture by defining the data definition language (DDL) scripts from requirements.
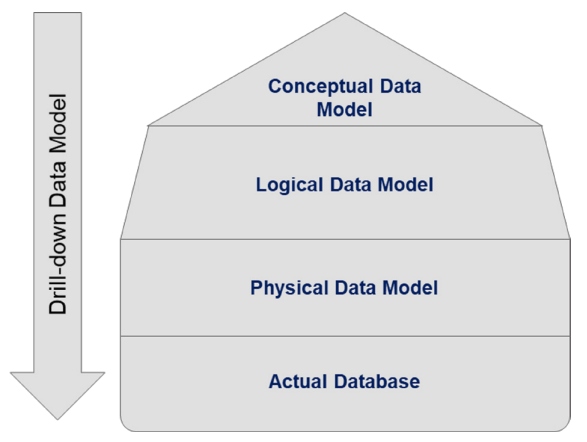
Figure 3: Modern enterprise data modeling stages
In modern enterprise data architecture, this is split into a multi-stage activity as conceptual, logical, and physical data modeling, as illustrated below in Figure 3. In a data-driven architecture where data intensity is high, data modeling is a fundamental and crucial step (and, of course, time-consuming). In such an architecture development, data modeling is innovatively divided into three different types:
- Conceptual data model (CDM) – Derived from business requirements to define "what" is handled in the data flow. Usually, CDM is defined by business stakeholders (e.g., consultants, business owners, application analysts) and data architects.
- Logical data model (LDM) – Derived from the CDM to drill down the logical relation between the entities and detail the data types of the entities. Deals with "how" data is handled in the data flow and is defined by business consultants and data architects/engineers.
- Physical data model (PDM) – Defines the actual blueprint based on th LDM, which gets translated to data scripts for execution in the live environment. This is the crucial stage where the performance of data structure, the transaction handling mechanism, and the tuning and optimization of the data model are being carried out and typically handled by database administrators or data engineers.
Data Intelligence
Data intelligence and data analytics are modern techniques used in modern enterprise data architectures for NoSQL databases to handle big data as well as data-intensive application architectures. It involves one or more of the popular technology solutions, like cloud platforms for agility and scalability of solutions, AI/ML for advanced algorithms to build intelligence in data processing, and big data platforms to handle the storage and analysis of the data.
Data intelligence handles data for visualization and analytics by using predictive intelligence to focus the data so that it's visualized for the future (forecasting). How a stock for an enterprise has trended so far is an example of data intelligence, and data analytics is using history to predict how it will change in the next year. Both use AI/ML and deep learning techniques, and both read data from various sources, including data feeds, images, video streaming, and audio extracts to interpret and prepare the results of data processing. The use of data intelligence helps to visually interpret data to different stakeholders including business and technical personas.
When you develop a data intelligence solution, you need to have a self-management facility in the database system so that the database is self-sufficient and able to automatically handle crisis situations. This is known as an autonomous database and is part of the future of new-age data persistence systems.
Autonomous Database
A database acts as the brain for an IT application because it serves as the central store for data being transacted and referenced in the application. Database administrators (DBAs) handle database tuning, security activities, backup, DR activities, server/platform updates, health checks, and all other management and monitoring activities of databases.
When you use a cloud platform for application and database development, the aforementioned activities are critical for better security, performance, and cost efficiency. The important aspect here is to operationalize these by reducing effort and making them more proactive in nature. Oracle has coined this an "autonomous database," and it automates many of the DBA's activities in managing the database platform and reducing human interventions.
Data Mesh
Traditionally, data used to be monolithic in nature by having all domains in a single data store, and effective data portioning and data solutioning would be done through data warehouse and data lake solutions. Data lakes used to be more efficient in data management and modern data analytics, which cater to agile data architectures, but the way data is accessed is missing a federated or autonomous approach in a data lake.
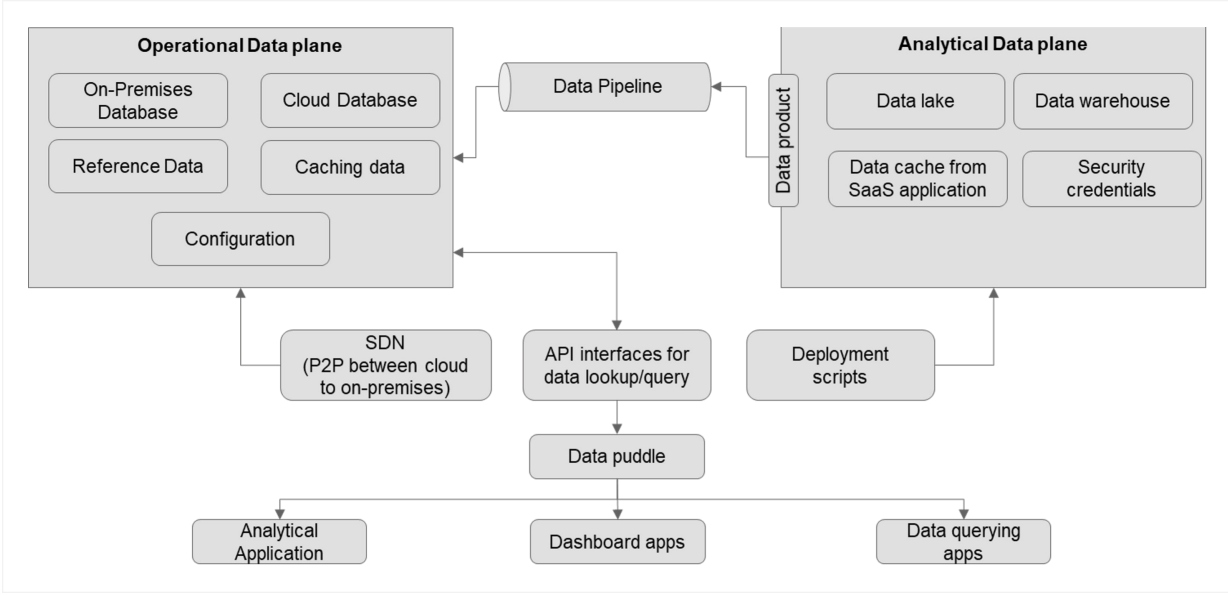
Figure 4: Data mesh architecture
As shown in Figure 4, unified data solutions are addressed by modern enterprise data architectures with a data mesh, which is a microservices pattern of a data store. A data mesh replicates a service mesh in terms of features. Where a service mesh creates a proxy to interface between services, a data mesh creates a proxy for data abstraction and interfacing for consuming applications like data analytics, dashboards, and data querying applications.
Data mesh architectures help to develop multi-dimensional data solutions to handle an operational data plane and an analytical data plane together in a unified architecture without the need for developing two distinct data solutions.
Heterogeneous Data Management Using Lakehouse Architecture
For data analytics and intelligent data management, we prefer to use a data lake solution or a data warehouse solution, but these solutions both have their own way of organizing and managing data. A data warehouse handles relational data (raw data feed) and processed data (after data ingestion), which is organized in a schema structure before it gets stored in a data storage service (data enrichment). Therefore, data analytics work on cleansed data.
A data warehouse is a costly form of storage, but it's faster at query processing since it handles schema-based structured data and is suitable for data intelligence, batch processing, and data visualization in real time.
A data lakehouse architecture is a hybrid approach that handles heterogeneous data management using the following:
- Data lake
- Data warehouse
- Purpose-built store for intermediate data handling
- Data governance mechanism for better data handling policies
- Data integrity services
A data lakehouse architecture overcomes the shortcomings of both data lake and data warehouse solutions and, hence, is increasingly popular in modern enterprise data solutions like lead generation and market analysis using data feeds from various sources.
A lakehouse architecture can handle inside-out data movement, from data stored in a data lake to a set of extracted data to a purpose-built store for analytics or querying activities. Outside-in data movement, from data warehouse to a data lake, can help run analytics on complete a dataset. With a lakehouse architecture, we can also handle data for both massively parallel processing (MPP), as in data warehouse applications, high-velocity data querying, and data lake applications.
Conclusion
Modern enterprise data practices elevate the approach toward building a resilient, agile, and scalable architecture. These approaches will address performance efficiency, operational excellence, high availability, and security/compliance requirements for building integrated data solutions by adopting technology and frameworks such as a polyglot persistence, modern data modeling stages, data lakes, and data meshes.
This is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments