Monitoring Docker Swarm
Learn how you can monitor your Docker Swarm environment with Prometheus and Grafana.
Join the DZone community and get the full member experience.
Join For Freein one of my last blog posts, i explained how you can set up a lightweight docker swarm environment . the concept, which is already an open-infrastructure project on github , enables you to run your business applications and microservices in a self-hosted platform.
today, i want to explain how you can monitor your docker swarm environment. although docker swarm greatly simplifies the operation of business applications, monitoring is always a good idea. the following short tutorial shows how you can use prometheus and grafana to simplify monitoring.
prometheus is a monitoring solution to collect metrics from several targets. grafana is an open-analytics and monitoring platform that helps visualize data collected by prometheus.
both services can be easily integrated into docker swarm. there is no need to install extra software on your server nodes. you can simply start with a docker-compose.yml file to define your monitoring stack and a prometeus.yml file to define the scrape configuration. you can find the full concept explained here on github in the imixs-cloud project .
after you have defined your monitoring stack by a docker-compose.yml file, you can start the monitoring with one simple command:
$ docker-compose up
the example files can be downloaded from here . since the docker-compose file is a little longer, i would like to briefly explain the important points now.
the networks
at the beginning of the docker-compose file, the section ‘networks’ defines two networks:
...
networks:
frontend:
external:
name: imixs-proxy-net
backend:
...
the external network ‘imixs-proxy-net’ is part of the core concept of the imixs-cloud project. if it is not yet available in your swarm, create it with docker:
$ docker network create --driver=overlay imixs-proxy-net
this network called ‘frontend’ is to access the prometheus and grafana services form your private network or the internet. the second network ‘backend’ is used only internally by the monitoring stack. in docker, it is always a good idea to hide as many services from external access as possible. so, this is the reason for this second network in the stack definition.
the prometheus service
the first service in the docker-compose.yml file is the prometheus service
...
prometheus:
image: prom/prometheus
volumes:
- $pwd/management/monitoring/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
deploy:
placement:
constraints:
- node.role == manager
networks:
- frontend
- backend
.....
this service imports the prometheus.yml file from the host directory management/monitoring and exposes the api on port 9090, which is publicly accessible from our ‘frontend’ network. the ‘backend’ network is for later services.
the node-exporter
the next service is the ‘node-exporter.’ the node-exporter is a docker image provided by prometheus to expose metrics like disk, memory, and network from a docker host. besides some special volumes and command definitions, this service is always placed on a specific node. in the following example, the service exports hardware metrics from the node ‘manager-001’:
....
manager-001:
image: prom/node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/host'
- '--collector.filesystem.ignored-mount-points="^(/rootfs|/host|)/(sys|proc|dev|host|etc)($$|/)"'
- '--collector.filesystem.ignored-fs-types="^(sys|proc|auto|cgroup|devpts|ns|au|fuse\.lxc|mqueue)(fs|)$$"'
deploy:
placement:
constraints:
# hostname of the manager node!
- node.hostname == manager-001
networks:
- backend
...
you can replace the hostname with the corresponding hostname from your environment. the node-exporter is only connected to the ‘backend’ network. this means it is visible to the prometheus service but not accessible from outside.
you can add a separate node-exporter definition in your docker-compose.yml file for each docker node, which is part of your docker-swarm.
the cadvisor
the cadvisor is the second metrics collector. i provide metrics about docker itself. the service is maintained by google.
...
docker-manager-001:
image: google/cadvisor:latest
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
deploy:
placement:
constraints:
# hostname of the first manager node!
- node.hostname == manager-001
networks:
- backend
..
again, this service can be defined for each docker node within your docker-swarm network. take care of the service names here, because these are needed later in the prometheus.yml file.
grafana
the last service needed for our monitoring is grafana. this service is quite simple in its definition:
...
grafana:
image: grafana/grafana
volumes:
- grafana-data:/var/lib/grafana
deploy:
placement:
constraints:
- node.role == manager
ports:
- 3000:3000
networks:
- frontend
- backend
..
the service collects the data from prometheus and provides the graphical dashboard. the service is accessible via port 3000. in the example, i place the service here on the manager node from my docker swarm. but you can run the service on any other node within your swarm network.
the prometeus.yml file
now, as your docker-compose.yml file defines all services needed to monitor, you can set up your prometheus.yml file. this file tells prometheus where to collect the metric data. as defined by our docker-compose.yml file, we have two targets — the node-exporter and the cadvisor:
# my global config
global:
scrape_interval: 15s # set the scrape interval to every 15 seconds. default is every 1 minute.
evaluation_interval: 15s # evaluate rules every 15 seconds. the default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, alertmanager).
external_labels:
monitor: 'codelab-monitor'
# load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first.rules"
# - "second.rules"
# a scrape configuration containing exactly one endpoint to scrape:
# here it's prometheus itself.
scrape_configs:
- job_name: 'node-exporter'
static_configs:
# the targets listed here must match the service names from the docker-compose file
- targets: ['manager-001:9100','worker-001:9100']
- job_name: 'cadvisor'
static_configs:
# the targets listed here must match the service names from the docker-compose file
- targets: ['docker-manager-001:8080','docker-worker-001:8080']
the important part here is the ‘targets’ section in the job descriptions for the ‘node-exporter’ and the ‘cadvisor.’ you need to add all the corresponding service names, which you have defined in your docker-compose.yml file here. this is because you need a separate node-exporter and cadvisor running on each node. in my example, i define two nodes for each service — the manager-001 node and the worker-001 node, which are part of my docker swarm.
…run your monitoring
and finally, you can now start your monitoring:
$ docker-compose up
that’s it. you can access prometheus via:
http://your-host:9090
first, check if prometheus is running and detecting all your metric providers by selecting the menu “status -> targets”:

if all endpoints are up, you can switch to the grafana ui:
http://your-host:3000
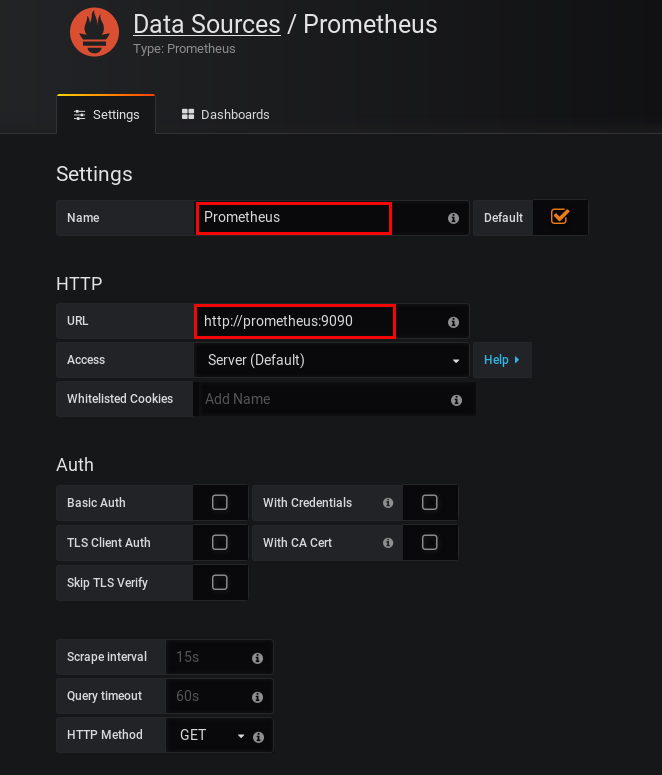
to access the metrics collected by prometheus, you just need to create a prometheus datasource. here, you can enter the internal prometheus url
http://prometheus:9090
which is the connect url from within the docker-swarm backend network:
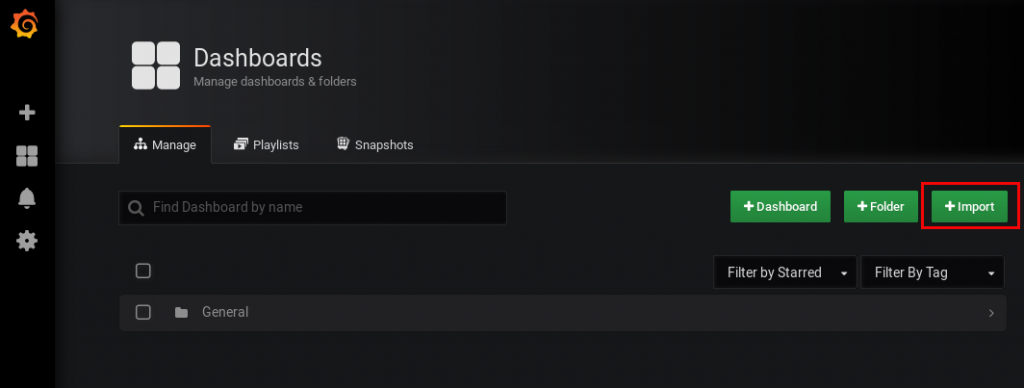
next, you can import the dashboard from the imixs-cloud project:
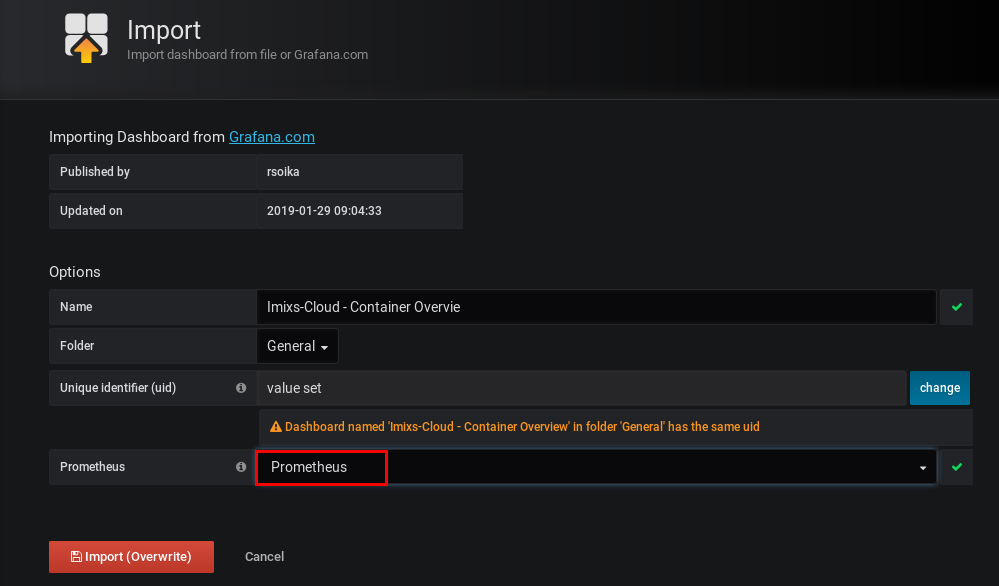
enter the official dashboard id
9722

and select your datasource ‘prometheus,’ which you have created before:
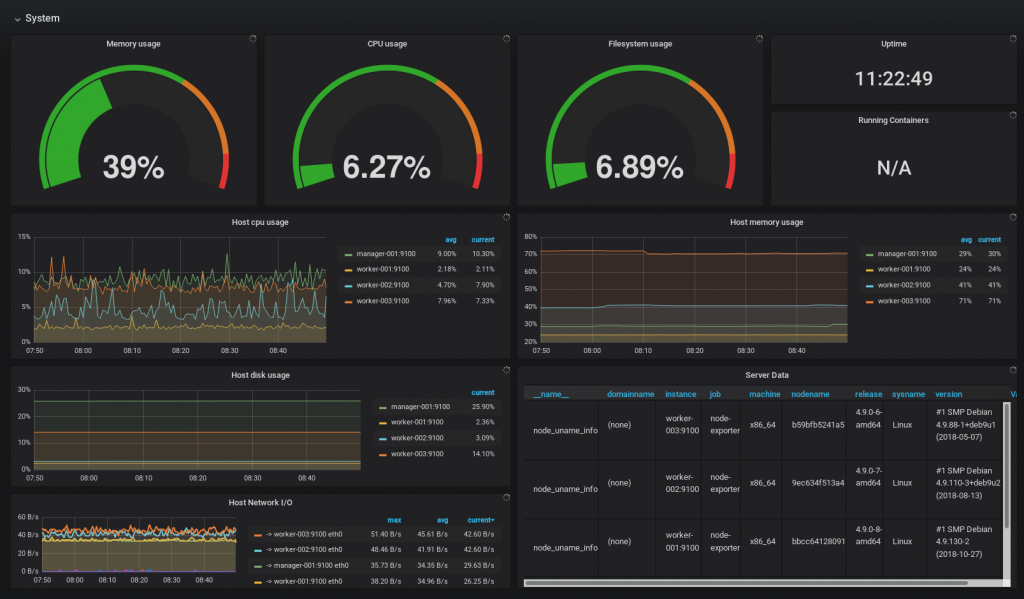
that's it, you can now see how your docker-swarm is working:
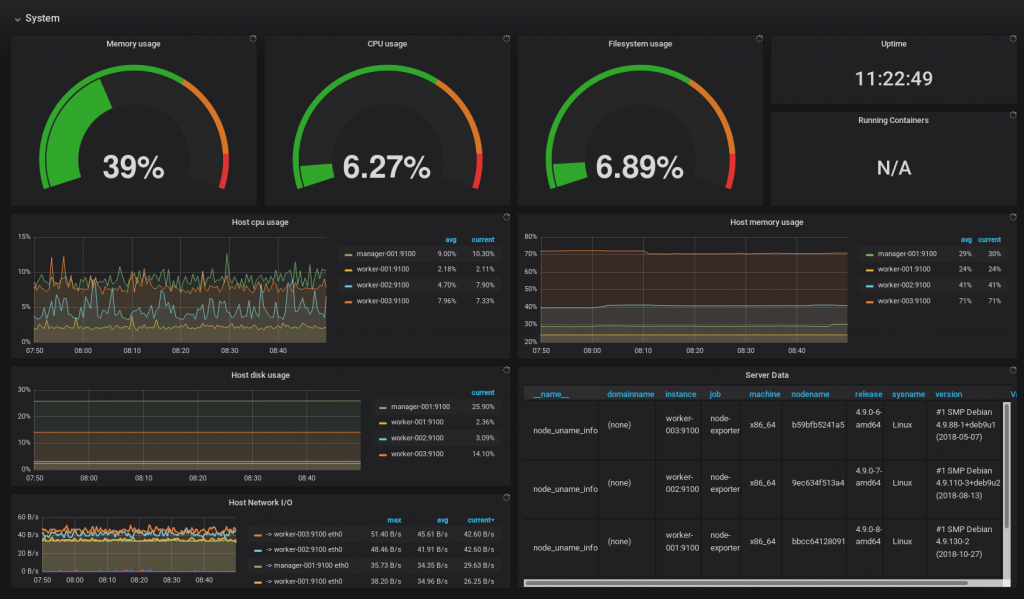
conclusion
monitoring docker swarm is easy with the existing services prometheus and grafana. you can start your own monitoring stack with docker-compose and only one single configuration file. you will find a complete description about a lightweight docker swarm environment on github – join the imixs-cloud project !
Published at DZone with permission of Ralph Soika. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments