From Monolith to Containers: Real-World Migration Blueprint
This guide shows how to move from a monolith to containers: containerize the app, split services gradually, adopt Kubernetes, automate with CI/CD, and modernize.
Join the DZone community and get the full member experience.
Join For FreeOver the years, I’ve worked on several enterprise applications that started out as monoliths. Initially, these systems worked beautifully. Everything was packaged in a single codebase, deployment was straightforward, and communication between components was simple and efficient. But as user demand grew and development teams expanded, these same applications began to show signs of strain. Release cycles slowed, onboarding became painful, and scaling even a small feature required far too much coordination. That’s when the containerization journey began.
This article is a real-world blueprint drawn from experience. It’s not just a checklist, but a practical migration story that walks through the exact stages I follow while moving from a monolith to containers. I’ll also reflect on the challenges and insights I’ve picked up along the way.
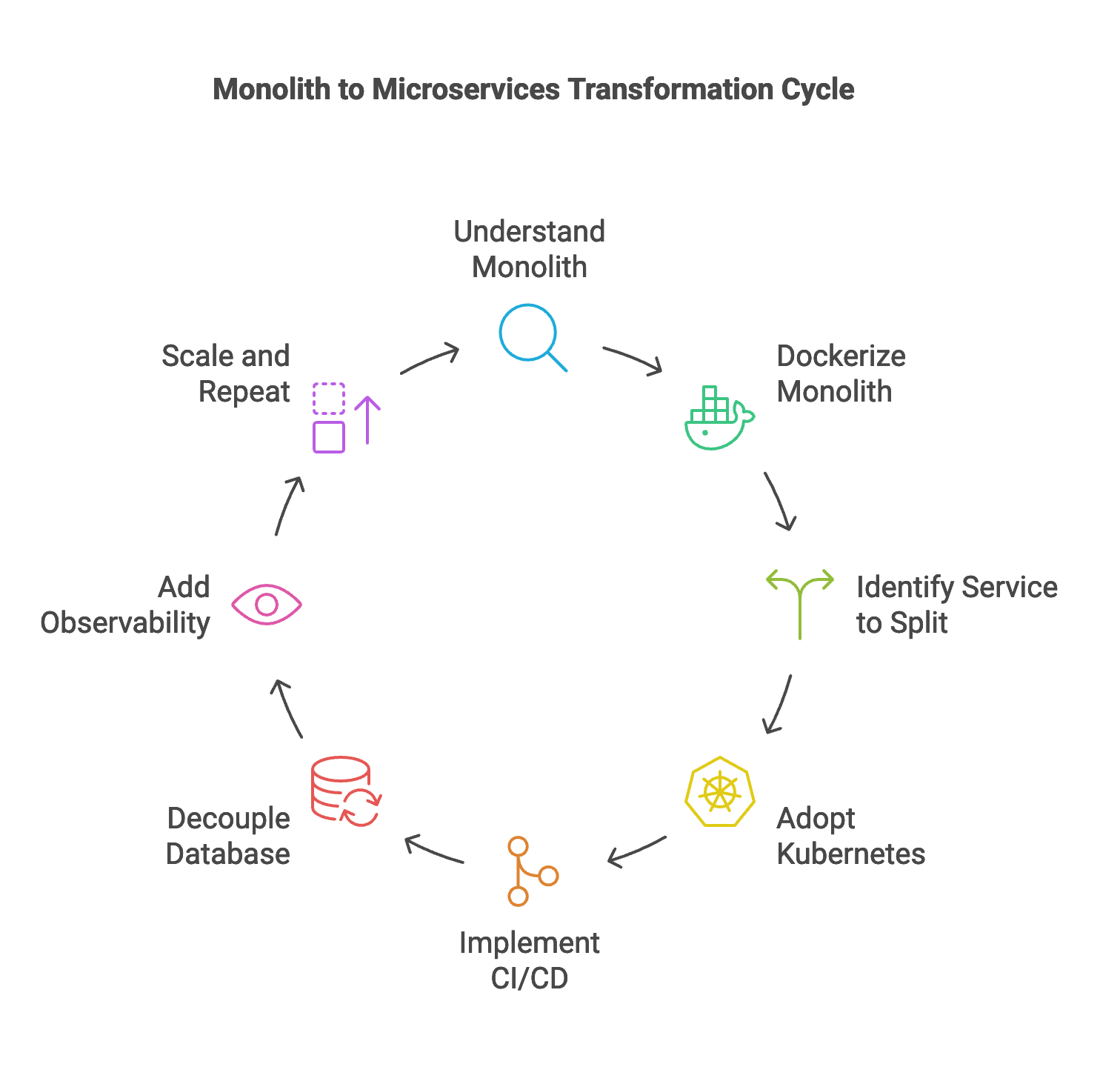
Step 1: Understand the Monolith Before Changing It
Migration without understanding leads to chaos. So the very first thing I do is get a deep understanding of the current monolith. This isn’t just about reading documentation, but actually digging into the codebase.
I identify logical modules, service boundaries, and tightly coupled components. I look for patterns like shared sessions, centralized databases, or common utility libraries that are used everywhere. Often, I find that even though the application is a monolith, its features are already grouped in a way that makes separation feasible. Think authentication, billing, inventory, or user management—they’re usually hiding in plain sight.
Once I can draw boundaries on a whiteboard and talk through dependencies, I know I’m ready for the next phase.
Step 2: Dockerize the Entire Monolith
It may sound counterintuitive, but before splitting anything, I first containerize the entire monolithic application. The idea here is to bring in environmental consistency and set the foundation for a DevOps pipeline.
Once the app runs reliably inside a container, I can eliminate a huge category of environment-specific bugs. It also allows developers, QA, and staging environments to be aligned right from the start. This becomes especially important later when I start spinning up individual services—having them all work inside containers reduces friction.
The goal here isn’t microservices yet. It’s about packaging the monolith in a predictable, repeatable way.
Step 3: Identify the First Service to Split
I never try to decouple the whole application at once. It’s too risky and too complex. Instead, I choose a small but self-contained module to split out—something like an authentication service or a notification handler.
When picking the first candidate, I consider a few things. First, it should have minimal dependencies on the rest of the system. Second, it should be critical enough to matter but not so central that it paralyzes development if things go wrong. And finally, it should have a well-defined interface, ideally one that can be exposed over HTTP or gRPC.
Once this service is identified, I carve it out into a new codebase, set up its own container, and make sure the rest of the monolith can talk to it reliably. This first service sets the tone for the entire migration. If it goes well, the team gains confidence and momentum.
Step 4: Adopt Kubernetes for Orchestration
As the number of containers grows, managing them manually becomes a nightmare. That’s where Kubernetes enters the picture.
I prefer to start with a lightweight distribution like K3s when experimenting or testing. It gives me all the capabilities of Kubernetes without the operational overhead. As we move toward production, I scale up the deployment to a full-featured managed cluster, often hosted in a cloud environment like Azure.
Kubernetes allows me to define clear deployment rules, health checks, rollbacks, scaling policies, and service discovery—all of which are essential once the architecture starts growing. It’s not just an orchestrator—it’s a safety net.
Step 5: Implement CI/CD Early
A lot of migrations fail not because of architecture but because of friction in deployment. That’s why I integrate continuous integration and continuous delivery early in the process.
Once each service is containerized, I set up pipelines to test, build, and deploy every change. I usually automate the tagging, push images to a container registry, and trigger deployments into test or staging environments on every commit. It sounds simple, but this practice alone saves countless hours and prevents the “it worked on my machine” dilemma.
This is also the point where the DevOps culture really begins to take shape. Developers become more independent and confident in pushing code because the system tells them immediately if something breaks.
Step 6: Decouple the Database and Shared State
Breaking apart a monolith isn’t just about code. The most delicate part is decoupling the shared database. In a typical monolith, all services talk to the same database schema. But in a containerized world, that becomes a bottleneck.
So I move slowly. First, I define schema ownership—each service should own its own tables and not reach into someone else’s domain. Then, I start to physically split the database where necessary. It’s not always required to have one DB per service, but the logical separation must be enforced through code.
Shared state is another trap. If services rely on in-memory sessions or shared global variables, I replace them with external storage mechanisms like Redis. This ensures statelessness, which is crucial for scaling containers across multiple nodes.
This part takes the most time but yields the highest payoff. Once done, services become truly independent, and scaling becomes a reality rather than a theory.
Step 7: Add Observability from the Start
One lesson I’ve learned the hard way is that microservices without observability is a nightmare. When something fails, you don’t know where, and you’re left guessing.
So I treat logging, monitoring, and tracing as first-class citizens. I instrument services with structured logs, expose health and metrics endpoints, and set up dashboards using tools like Prometheus and Grafana. Distributed tracing is especially useful once you’ve got three or more services talking to each other.
The visibility this provides is invaluable. You know when a service is slow, when an API is throwing errors, or when a deployment introduced a spike in latency. It helps debug faster and iterate confidently.
Step 8: Scale and Repeat
Once the initial service is stable, I move on to the next. Each migration becomes easier because the tooling, processes, and confidence are already in place.
I repeat this pattern, always focusing on isolating a domain, defining clear interfaces, and building independently deployable services. The monolith gradually shrinks, and the containerized system grows.
At this point, the architecture starts looking like a network of small, self-contained services—all running in containers, talking to each other via APIs, and deployed automatically.
Final Thoughts
Migrating from a monolith to containers is not a weekend project. It’s a journey that combines architecture, DevOps, infrastructure, and culture. But it’s one of the most valuable investments you can make if your system is growing in complexity and scale.
The key is to move gradually, celebrate small wins, and continuously improve your tooling. With containers, you not only modernize the architecture but also empower your teams to ship faster, scale better, and recover quicker.
Every monolith has a future in containers—it just needs the right blueprint.
Opinions expressed by DZone contributors are their own.
Comments