Mule Sub-Flows, Processing Strategy, and One-Way Endpoints
Interested in learning more about Mule? Read on to get an overview of sub-flows, processing strategy, and one-way endpoints.
Join the DZone community and get the full member experience.
Join For FreeBenefits of breaking up flows into separate flows and subflows:
Makes the graphical view more intuitive, you don’t want long flows that go off the screen.
Makes XML code easier to read.
Enables code reuse.
Provides separation between an interface and implementation.
Makes them easier to test.
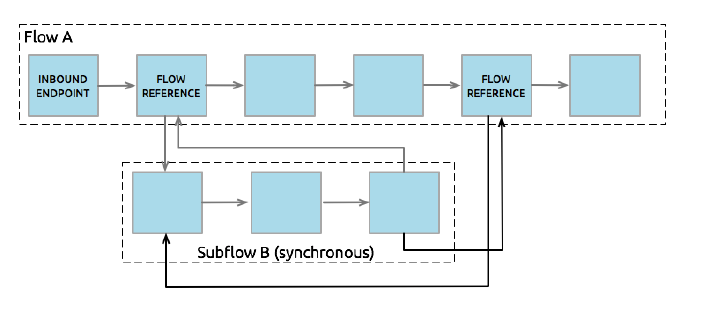
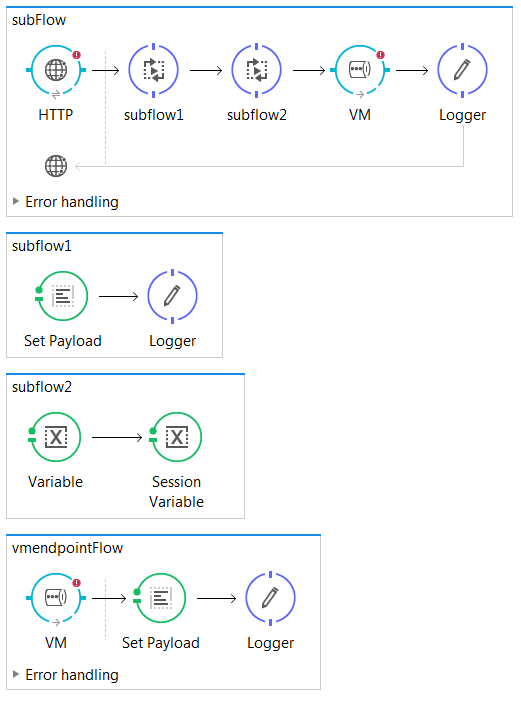
Subflows:
Subflows are executed exactly as if the processors were still in the calling flow.
Always run synchronously in the same thread.
Inherit the processing and exception strategies of the flow that triggered its execution.
Flows:
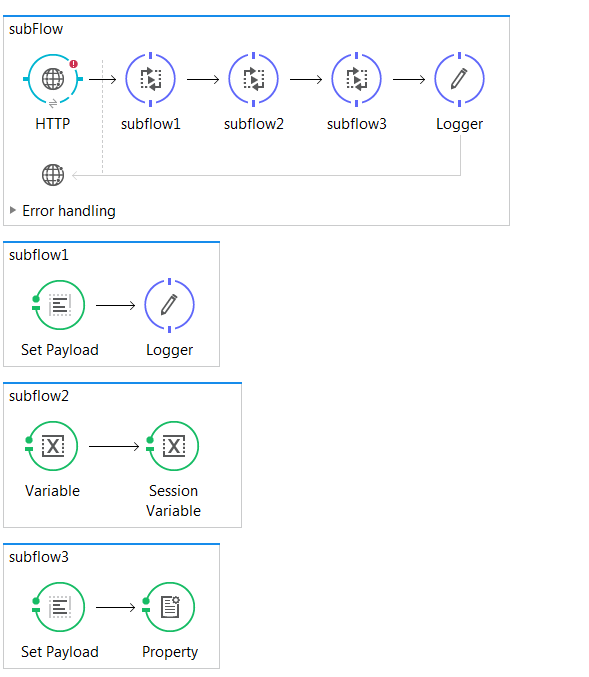
Flows, on the other hand, have much more flexibility in how they are used.
They cn have their own processing and exception strategies.
They can be synchronous or asynchronous.
Flows without message sources are sometimes called private flows.
Processing Strategy:
A flow processing strategy determines how Mule implements message processing for a given flow.
Should the message be processed synchronously (on the same thread) or asynchronously (on a different thread)?
If asynchronously, what are the properties of the pool of threads used to process the messages?
If asynchronously, how will messages wait for their turn to be processed in the second thread?
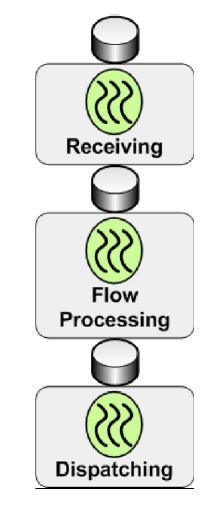
Flows contain 3 thread pools:
Receiving - Message source's threads.
Flow processing - Message processor's threads.
Dispatching - Outbound endpoint's threads.
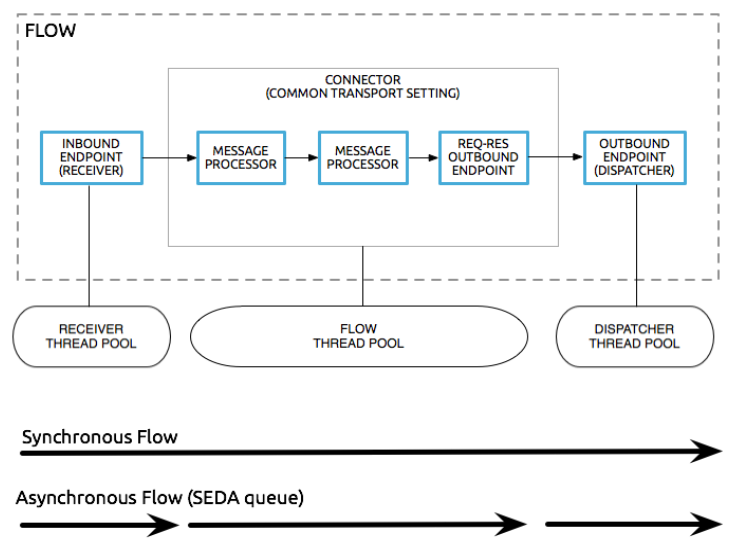
Use of pools depends on a flow's behavior :
Staged Event Driven Architecture (SEDA):
The architecture upon which Mule was built.
Decouples receiving, processing, and dispatching phases.
Supports higher levels of parallelism in specific stages of processing.
Allows for more-specific tuning of areas within a flow's architecture.
What determines a flow’s processing strategy?
Mule automatically sets a flow to be Synchronous or queued-asynchronous.
A flow is set to synchronous if the message source is request-response.
The flow partakes in a transaction.
Otherwise, a flow is set to queued-asynchronous. The message source is not expecting a response.
Synchronous flows:
When a flow receives a message, all processing, including the processing of the response, is done in the same thread.
Uses only the message source's thread pool.
The flow's thread pool is elastic and will have one idle thread that is never used.
Tuning for higher-throughput happens on the connector receiver's level.
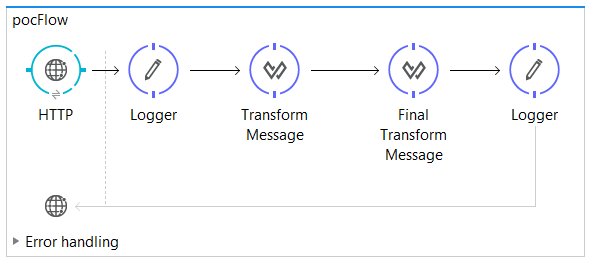
Queued-asynchronous flows:
Decouples and uses all 3 thread pools.
Uses queues, whose threads drop messages off for the subsequent pool's thread to pick up.
Pools, queues, and behaviors of this strategy are configurable.
By default, the flow thread pool has 16 threads.
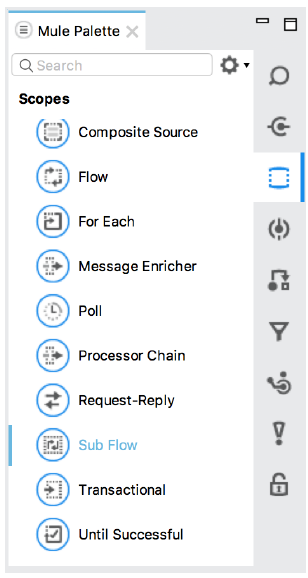
Creating flows and subflows:
Use flow scope to create a new flow or drag any message processor to the canvas.
Use subflow scope to create subflows.
Use Flow Reference component to pass messages to other flows or subflows.
Flow variables persist through all flows unless the message crosses a transport boundary.
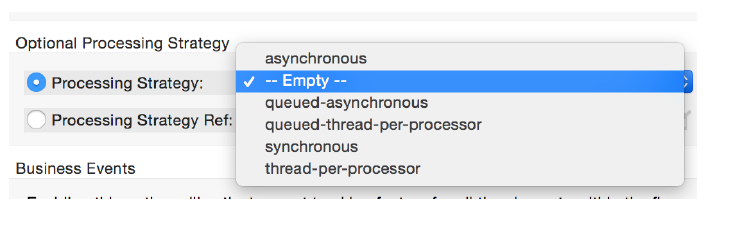
Setting the flow processing strategy:
The flow processing strategy is automatically set.
It can be changed in the flow’s properties view.
This is usually done when a custom queued-asynchronous profile has been created for tuning application performance.
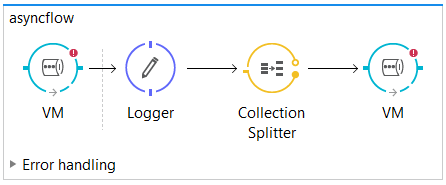
Using VM endpoints in flows - The Java Virtual Machine (VM) transport:
The Java Virtual Machine (VM) transport can be used for intra-JVM communication between Mule flows.
Each app in a Mule instance has its own, unique set of VM endpoints.
The VM transport can only handle communications within an app or between apps in the same domain.
This transport by default uses in-memory queues but can optionally be configured to use persistent queues.
Before Mule 3, the VM transport was needed to pass a message from one flow to another.
In Mule 3, Flow Reference was added to let flows directly reference one another without a transport in the middle.
VM transport is now mostly used to:
- Achieve higher levels of parallelism in specific stages of processing.
- Allow for more-specific tuning of areas within a flow's architecture.
- Call flows in other applications that are in the same domain.
Opinions expressed by DZone contributors are their own.
Comments