MuleSoft Poll Scope and Watermark
Learn how to use a Mule app to retrieve legacy data and sync it to a new destination endpoint with the poll scope method.
Join the DZone community and get the full member experience.
Join For Free1.0 Overview
As integration developers, we are always faced with the need to poll a legacy resource to retrieve new data and to sync it over to another destination endpoint. MuleSoft allows developers to do this via "Poll Scope." The poll scope allows the developer to poll a particular source endpoint based on a timed interval. The poll scope also has this neat caching function known as "Watermark."
Watermark allows the poll scope to poll for new resources instead of getting the same resource over and over again. The following illustration shows how this is done.

Figure 1.0 is an abstraction of the Mule's "Poll Scope;" it is always implemented in the receive scope. The illustration shows that it is polling a database table; the database table must be ordered so that the "Watermark functionality" can move effectively in the ordered list. Watermark stores the current/last picked up record id. If the following Mule application is shut down, it will store the last picked up record id in Java Object store and the data will be persisted into files. This operation is transparent to the users and that is the value of having the Watermark functionality. Developers do not need to create code to handle caching; it is all configurable.
2.0 Creating a Hypothetical Scenario
It is always easier to learn something by doing, so let's make up a hypothetical scenario. In this scenario, the integration developer is required to build a Mule app that is capable of syncing newly created employees from a legacy database to a new source system.
Let’s say our source system is a SQL Server database. You can do this via any database the example shown in MuleSoft is a MySQL database, and since they already have that example, I figure I would do it differently so that developers have more sample codes to play around with.
2.1 Preparing the Legacy Database
You will need to have preinstalled SQL Server on your local machine. Then you need to create a database with the name "MuleDemoDb," as per the following depiction.

After you create the database, you need to open a query editor and point to the newly created database and execute the following DB Scripts.
CREATE TABLE employees (
no INT NOT NULL,
dob DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender VARCHAR(1) NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (no)
);
CREATE TABLE roles (
id INT NOT NULL IDENTITY(1,1),
emp_no INT,
role varchar(255) default NULL,
PRIMARY KEY (id)
) ;
INSERT INTO employees (no,dob,first_name,last_name,gender,hire_date) VALUES (1011,'1985-09-02','Chava','Puckett','F','2008-10-12');
INSERT INTO employees (no,dob,first_name,last_name,gender,hire_date) VALUES (1012,'1971-12-03','Christopher','Tillman','M','2006-11-01');
INSERT INTO employees (no,dob,first_name,last_name,gender,hire_date) VALUES (1013,'1975-07-31','Judith','David','F','10-11-20');
INSERT INTO employees (no,dob,first_name,last_name,gender,hire_date) VALUES (1014,'1957-08-03','Neil','Ford','F','08-09-04');
INSERT INTO employees (no,dob,first_name,last_name,gender,hire_date) VALUES (1015,'1977-01-09','Daryl','Wolfe','M','07-09-14');
...
INSERT INTO roles (emp_no,role) VALUES (1011,'Sr. Developer');
INSERT INTO roles (emp_no,role) VALUES (1012,'Office Manager');
INSERT INTO roles (emp_no,role) VALUES (1013,'Secretary');
INSERT INTO roles (emp_no,role) VALUES (1014,'Engineer');
INSERT INTO roles (emp_no,role) VALUES (1015,'CEO');
...2.2 The Hypothetical Requirement
You are to build a Mule application that will pool this employee database for newly created employees and send it across to be handled by different message processors, and in the event of an execution failure/message processor exception, the app must be capable of resuming database polling from an employee ID that is larger than the previous successful watermark value. The following flow chart illustrates this requirement.

3.0 Developing the Mule Application
Figure 3.0 depicts how the end solution looks. The main flow that depicts the solution is "muledbpollingflow;" the second flow "resetObjectStore" is for us, the developers, to reset the watermark value so that we do not need to keep creating new records.

I will start to talk about the internal configuration of the main flow ("muledbpollingflow") from left to right so that you can understand what is happening under the hood.
3.1 Poll Scope Settings
First, in the receive scope, we have the poll scope. The following screenshot shows the settings we have employed into the poll scope (Figure 3.1).

I have set the frequency for polling to happen every five seconds by entering 5000 milliseconds to the text box. There will be a zero start delay, and I have put in the time measurement as milliseconds. If you look at Figure 3.0, you will see an alternate option to set up a Cron Scheduler.
Next up you have the Watermark pane; here is where you key in all the configurations for the Watermark functionality. The first field would be the flow variable name that you want Watermark operation to serialize. The second field is the default value that you want your flow variable to store on its first run. Here I have used the Update Expression instead of the Selector Expression, because that is the only thing that will work for the mentioned requirement in section 2.2 (and besides, the Selector Expression is already demonstrated in the MuleSoft documentation; I chose the Update Expression because its usage is not demonstrated).
Next, we have the selector expression. This is important as it tells the watermark function on which field on the database to focus on. Here you can see that it is implied where one record from the database is equivalent to one payload. In other words, when a record's data is retrieved from the database onto a Mule flow, it is then represented as a payload; the field name of the records are the same whether it be from the table (in the database) or from the message payload in Mule (during runtime).
The next field is the "Object Store." Developers have an option to write their own Java Object Store (for more convoluted use cases) or to use the default object store implemented in Mule. I have made a reference to the default/implied object store in mule "_defaultUserObjectStore."
3.2 The Database Connector
Inside the poll scope, we have the database connector. You can obtain the details of the database connector configuration from the sourcecode that I have checked into GIT Hub.

We will be executing a select operation, in the select operation you have to key in the SQL statement that will be executed by the poll, here you see that I am using the watermark flow variable called "lastRecordID," and notice the order by section of the query; that is really important because we want an ordered result to be able to apply the watermark function. Now if you look at the advanced tab, depicted by Figure 3.2.2 below, you will see that I have configured the database connector to retrieve five records at a time.

3.3 The "For Each" Scope
Before we delve into "For Each" scope notice that we have set a message processor to initialize a flow variable name "previousRecordID."
<set-variable variableName="previousRecordID" value="#[flowVars['lastRecordID']]" doc:name="Initialize previousRecordID" />This is so that we can use this flow variable later in the For Each Scope.
Next, we move on to the "For Each Scope" (at Figure 3.3), here you notice that we need not configure anything and the scope intuitively knows how to split the five records payload.

This would mean that the steps we employ inside "For Each Scope" are to process one record at a time, because the "For Each scope" splits the records implicitly for us. The first operation of the for each scope is to set a flow variable called "currentRecord" with the value of "#[payload['no']]".
<set-variable variableName="currentRecord" value="#[payload['no']]" doc:name="currentRecord" />This is so that we could keep track of the current record being processed, and at the end of the "For Each Scope" we will set the value of "currentRecord" into a new flow variable called "previousRecordID."
<set-variable variableName="previousRecordID" value="#[flowVars['currentRecord']]" doc:name="previousRecordID" />"previousRecordID" is the same flow variable that is used in section 3.1 for the "Watermark's" update expression.
Now let’s look at the Groovy expression in between the flow variable setting message processors.
flowVars.dividend = Math.abs(new Random().nextInt() % 3 - 1);
flowVars.divisor = Math.abs(new Random().nextInt() % 3 - 1);
System.out.println("Curent Record ID:" + flowVars['currentRecord']);
System.out.println("Payload: " + payload );
System.out.println("Executing " + flowVars.dividend + " / " + flowVars.divisor );
def ans = flowVars.dividend / flowVars.divisor ;What I am trying to do here is to intermittently create a division by zero exception/error. The reason I am doing this is to simulate a real-world example where an exception/error can happen anytime while the records are being processed.
When an exception happens, we want the Watermark function to be able to revert back to the previous successful record and start from there. So, in other words, the sole purpose of the Groovy message processor is to simulate unexpected and intermittent errors while we are processing the records in runtime.
4.0 Testing the Mule App
It's time to put the rubber on the road and see what really happens during runtime.
4.1 Resetting the Watermark during runtime
You could reset watermark value by using Postman or any web browser, just pass in the Employee ID as the URL parameter, and the Mule app will pick up the next biggest employee ID from the table (refer to the following depiction).
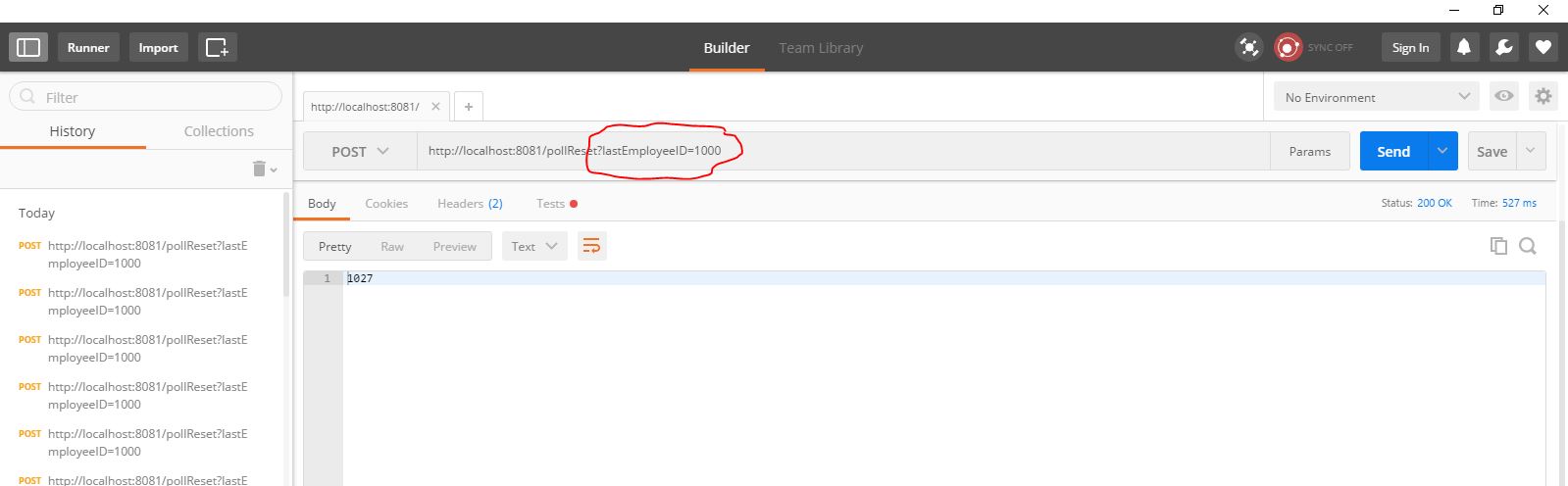
If you click send on Postman, you will see the following log being printed in your console.
org.mule.api.processor.LoggerMessageProcessor: Reset WaterMark to : 1000When you set the watermark value to 1000, the first record in the employee table actually begins with the ID 1011; the poll scope can then start from the first record and work its way through to the last record.
When the poll scope has finished picking up all records you will see the following being logged into the console window.
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression
Foreach$CollectionMapSplitter: Splitter returned no results. If this is not expected, please check your split expression4.2 Polling Starts
When polling starts, you will see the following logs being printed in the console window.
Curent Record ID:1011
Payload: [gender:F, no:1011, dob:1985-09-02, last_name:Puckett, hire_date:2008-10-12, first_name:Chava]
Executing 2 / 1
Curent Record ID:1012
Payload: [gender:M, no:1012, dob:1971-12-03, last_name:Tillman, hire_date:2006-11-01, first_name:Christopher]
Executing 1 / 3
Curent Record ID:1013
Payload: [gender:F, no:1013, dob:1975-07-31, last_name:David, hire_date:2020-10-11, first_name:Judith]
Executing 1 / 1
Curent Record ID:1014
Payload: [gender:F, no:1014, dob:1957-08-03, last_name:Ford, hire_date:2004-08-09, first_name:Neil]
Executing 3 / 2
Curent Record ID:1015
Payload: [gender:M, no:1015, dob:1977-01-09, last_name:Wolfe, hire_date:2014-07-09, first_name:Daryl]
Executing 0 / 3
...When you look at the logs you notice that there are intermittent errors caused by division by zero. When this happens, the poll scope will resume polling back to the failed record ID, and yes, we have achieved our objective of creating a Mule app that will fulfill the requirements specified in section 2.2.
5.0 Full Source code
The full working source code can be found at this link.
6.0 Conclusion
There are so many other ways you can test the watermark functionality. One of the ways my son has helped me test is that, while I was away on a coffee break, he took hold of my laptop and pressed the shutdown button while the polling was half way running (my son is about 3 years old at the time of this writing).
I thought I would need to reset the watermark to have it run from scratch all over again, but when I turned back up my laptop, started Anypoint Studio and started this Mule app just where it left off- amazing, isn't it? This watermark functionality will really come in handy with its implied serialization to disk when we shut down the app or the server. My son has discovered this feature for me! You could download the app and do more testing yourself, the only way to learn something is to experience it and play around with it, so happy exploring!
Published at DZone with permission of Kian Ting. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments