Multimodal Search in AI Apps With PostgreSQL pgvector
This article demonstrates how you can add image and text-based search functionality to your AI applications using a multimodal LLM and PostgreSQL pgvector.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have significantly evolved beyond generating text responses to text prompts. These models are now trained to possess advanced capabilities like interpreting images and providing detailed descriptions from visual inputs. This gives users an even greater search capacity.
In this article, I’ll demonstrate how to build an application with multimodal search functionality. Users of this application can upload an image or provide text input that allows them to search a database of Indian recipes. The application is built to work with multiple LLM providers, allowing users to choose between OpenAI, or a model running locally with Ollama. Text embeddings are then stored and queried in PostgreSQL using pgvector.
To check out the full source code, with instructions for building and running this application, visit the sample app on GitHub.
A full walkthrough of the application and its architecture is also available on YouTube:
Building Blocks
Before diving into the code, let’s outline the role that each component plays in building a multimodal search application.
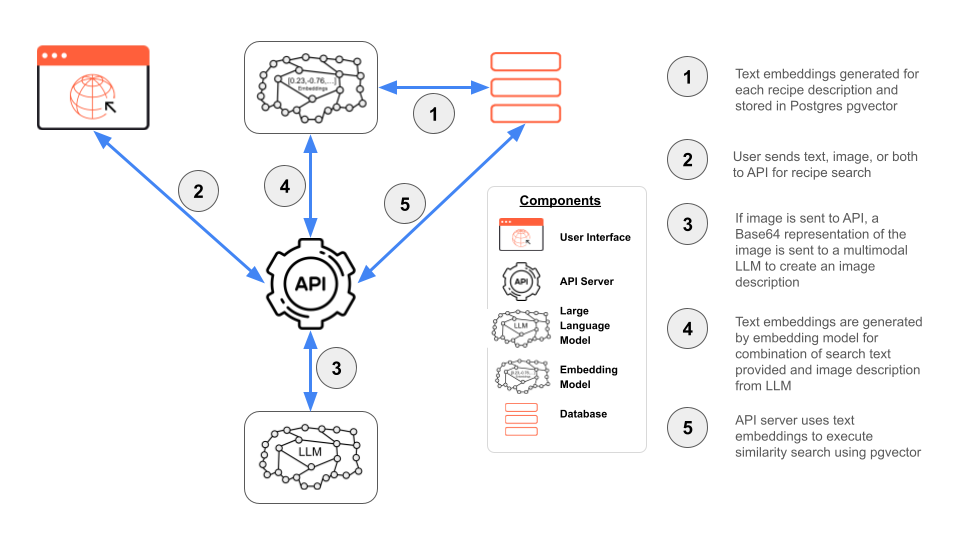
- Multimodal Large Language Model (LLM): A model trained on a large dataset with the ability to process multiple types of data, such as text, images, and speech
- Embedding model: A model that converts inputs into numerical vectors of a fixed number of dimensions for use in similarity searches; for example, OpenAI’s text-embedding-3-small model produces a 1536-dimensional vector
- PostgreSQL: The general-purpose relational open-source database for a wide array of applications, equipped with extensions for storing and querying vector embeddings in AI applications
- pgvector: A PostgreSQL extension for handling vector similarity search
Now that we have an understanding of the application architecture and foundational components, let’s put the pieces together!
Generating and Storing Embeddings
This project provides utility functions to generate embeddings from a provider of your choice. Let’s walk through the steps required to generate and store text embeddings.
The cuisines.csv file holding the original dataset is read and stored in a Pandas DataFrame to allow for manipulation.
The description of each recipe is passed to the generate_embedding function to populate new column embeddings in the DataFrame. This data is then written to a new output.csv file, containing embeddings for similarity search.
Later on, we’ll review how the generate_embedding function works in more detail.
import sys
import os
import pandas as pd
# Add the project root to sys.path
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
from backend.llm_interface import generate_embedding
# Load the CSV file
csv_path = './database/cuisines.csv'
df = pd.read_csv(csv_path)
# Generate embeddings for each description in the CSV
df['embeddings'] = df['description'].apply(generate_embedding, args=(True,))
# Save the DataFrame with embeddings to a new CSV file
output_csv_path = './database/output.csv'
df.to_csv(output_csv_path, index=False)
print(f"Embeddings generated and saved to {output_csv_path}")Using pgvector, these embeddings are easily stored in PostgreSQL in the embeddings column of type vector.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE table recipes (
id SERIAL PRIMARY KEY,
name text,
description text,
...
embeddings vector (768)
);
The generated output.csv file can be copied to the database using the COPY command, or by using the to_sql function made available by the Pandas DataFrame.
# Copy to recipes table running in Docker
docker exec -it postgres bin/psql -U postgres -c "\COPY recipes(name,description,...,embeddings) from '/home/database/output.csv' DELIMITER ',' CSV HEADER;"# Write the DataFrame to the recipes table table
engine = create_engine('postgresql+psycopg2://username:password@hostname/postgres')
df.to_sql('recipes', engine, if_exists='replace', index=False)With a PostgreSQL instance storing vector embeddings for recipe descriptions, we’re ready to run the application and execute queries.
The Multimodal Search Application
Let’s connect the application to the database to begin executing queries on the recipe description embeddings.
The search endpoint accepts both text and an image via a multipart form.
# server.py
from llm_interface import describe_image, generate_embedding
...
@app.route('/api/search', methods=['POST'])
def search():
image_description = None
query = None
# multipart form data payload
if 'image' in request.files:
image_file = request.files['image']
image_description = describe_image(image_file)
data = request.form.get('data')
if data and 'query' in data:
try:
data = json.loads(data)
query = data['query']
except ValueError:
return jsonify({'error': 'Invalid JSON data'}), 400
if not image_description and not query:
return jsonify({'error': 'No search query or image provided'}), 400
embedding_query = (query or '') + " " + (image_description or '')
embedding = generate_embedding(embedding_query)
try:
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute("SELECT id, name, description, instructions, image_url FROM recipes ORDER BY embeddings <=> %s::vector LIMIT 10", (embedding,))
results = cursor.fetchall()
cursor.close()
conn.close()
return jsonify({'results': results, 'image_description': image_description or None})
except Exception as e:
return jsonify({'error': str(e)}), 500While this API is pretty straightforward, there are two helper functions of interest: describe_image and generate_embedding. Let’s look at how these work in more detail.
# llm_interface.py
# Function to generate a description from an image file
def describe_image(file_path):
image_b64 = b64_encode_image(file_path)
custom_prompt = """You are an expert in identifying Indian cuisines.
Describe the most likely ingredients in the food pictured, taking into account the colors identified.
Only provide ingredients and adjectives to describe the food, including a guess as to the name of the dish.
Output this as a single paragraph of 2-3 sentences."""
if(LLM_ECOSYSTEM == 'ollama'):
response = ollama.generate(model=LLM_MULTIMODAL_MODEL, prompt=custom_prompt, images=[image_b64])
return response['response']
elif(LLM_ECOSYSTEM == 'openai'):
response = client.chat.completions.create(messages=[
{"role": "system", "content": custom_prompt},
{"role": "user", "content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"},
}]}
], model=LLM_MULTIMODAL_MODEL)
return response.choices[0].message.content
else:
return "No Model Provided"The describe_image function takes an image file path and sends a base64 encoding to the user’s preferred LLM.
For simplicity, the app currently supports models running locally in Ollama, or those available via OpenAI. This base64 image representation is accompanied by a custom prompt, telling the LLM to act as an expert in Indian cuisine in order to accurately describe the uploaded image. When working with LLMs, clear prompt construction is crucial to yield the desired results.
A short description of the image is returned from the function, which can then be passed to the generate_embedding function to generate a vector representation to store in the database.
# llm_interface.py
# Function to generate embeddings for a given text
def generate_embedding(text):
if LLM_ECOSYSTEM == 'ollama':
embedding = ollama.embeddings(model=LLM_EMBEDDING_MODEL, prompt=text)
return embedding['embedding']
elif LLM_ECOSYSTEM == 'openai':
response = client.embeddings.create(model=LLM_EMBEDDING_MODEL, input=text)
embedding = response.data[0].embedding
return embedding
else:
return "No Model Provided"The generate_embedding function relies on a different class of models in the AI ecosystem, which generate a vector embedding from text. These models are also readily available via Ollama and OpenAI, returning 768 and 1536 dimensions respectively.
By generating an embedding of each image description returned from the LLM (as well as optionally providing additional text via the form input), the API endpoint can query using cosine distance in pgvector to provide accurate results.
cursor.execute("SELECT id, name, description, instructions, image_url FROM recipes ORDER BY embeddings <=> %s::vector LIMIT 10", (embedding,))
results = cursor.fetchall()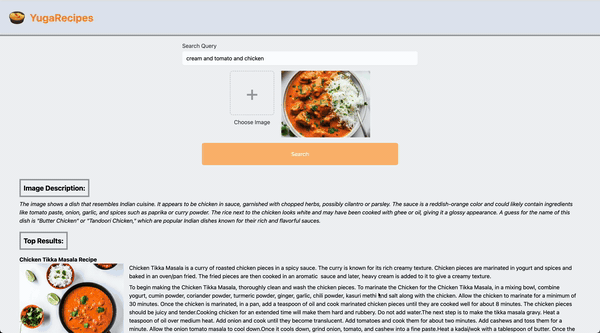
By connecting the UI and searching via an image and short text description, the application can leverage pgvector to execute a similarity search on the dataset.
A Case for Distributed SQL in AI Applications
Let’s explore how we can leverage distributed SQL to make our applications even more scalable and resilient.
Here are some key reasons that AI applications using pgvector benefit from distributed PostgreSQL databases:
- Embeddings consume a lot of storage and memory. An OpenAI model with 1536 dimensions takes up ~57GB of space for 10 million records. Scaling horizontally provides the space required to store vectors.
- A vector similarity search is very compute-intensive. By scaling out to multiple nodes, applications have access to unbound CPU and GPU limits.
- Avoid service interruptions. The database is resilient to node, data center, and regional outages, so AI applications will never experience downtime as a result of the database tier.
YugabyteDB, a distributed SQL database built on PostgreSQL, is feature and runtime-compatible with Postgres. It allows you to reuse the libraries, drivers, tools, and frameworks created for the standard version of Postgres. YugabyteDB has pgvector compatibility and provides all of the functionality found in native PostgreSQL. This makes it ideal for those looking to level up their AI applications.
Conclusion
Using the latest multimodal models in the AI ecosystem makes adding image search to applications a breeze. This simple, but powerful application shows just how easily Postgres-backed applications can support the latest and greatest AI functionality.
Published at DZone with permission of Brett Hoyer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments