My Top Picks of Re:Invent 2023
AWS Re:Invent 2023 has wrapped up. In this article, review some of the top announcements from this event.
Join the DZone community and get the full member experience.
Join For FreeRe: Invent 2023 has wrapped up. Before we start preparing for the 2024 edition, let me recap the announcements I was most excited about.
Here is my favorite list, in no particular order.
1. Amazon Elasticache Serverless
As architects and developers, we love to get into database scalability discussions and right-sizing our database clusters. I know I do, especially when it comes to Redis, one of my favorite databases! But, with the recently announced serverless option for ElastiCache, we may not have to do all that. I know - sad, but true, because you can now set up a new cache in under a minute without worrying about choosing a cache node type, number of shards, number of replicas, or node placements across AZs.
By the way, this is applicable for both Redis and memcached engines supported by ElastiCache.
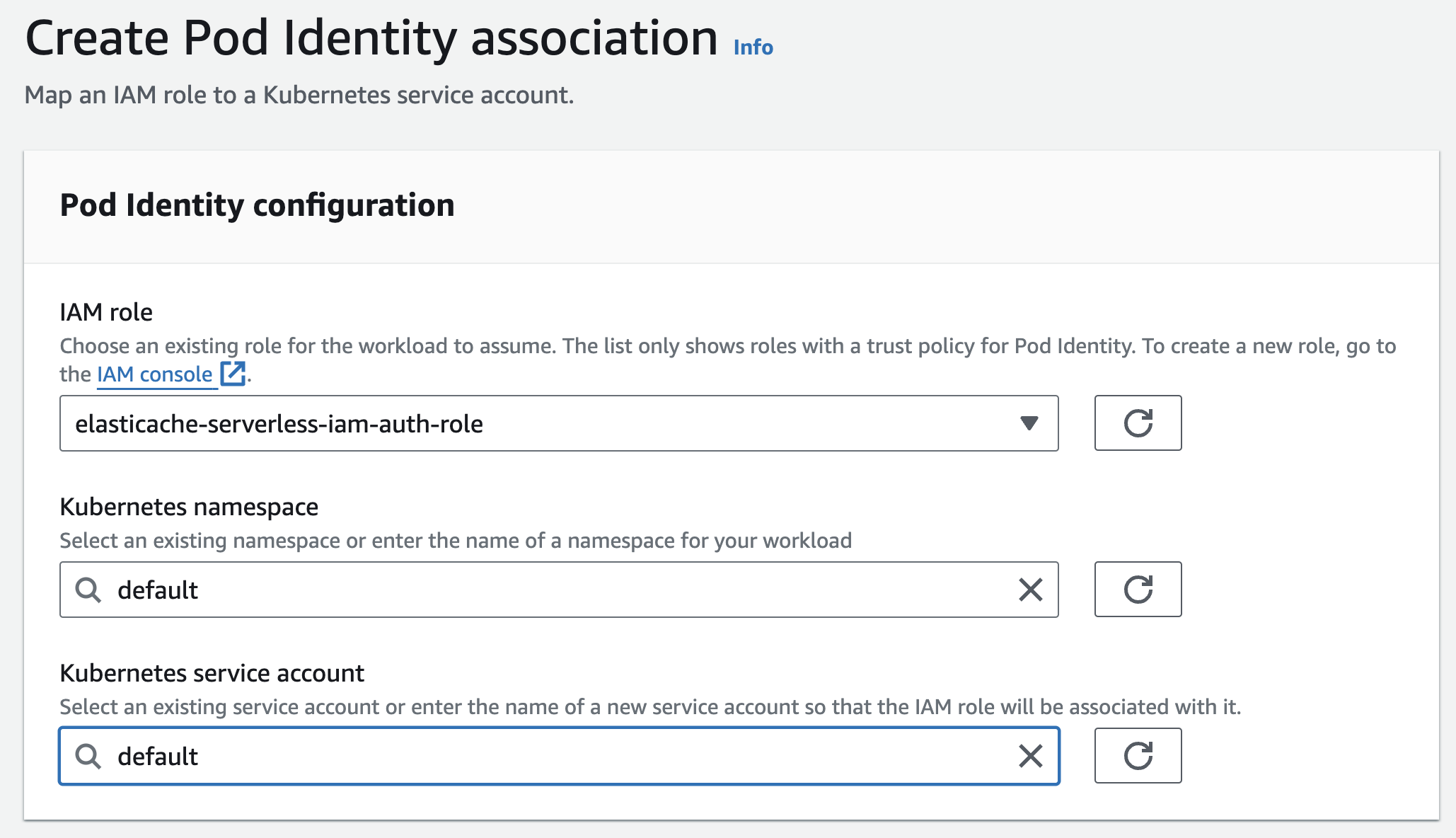
2. Amazon EKS Pod Identity
Who likes configuring IRSA in EKS? I am not a huge fan! Thank god for Amazon EKS Pod Identity that simplifies this experience!
I have already taken this for a spin (detailed blog post coming soon) and you should too! Here is the announcement, AWS News blog, and most importantly, the documentation.
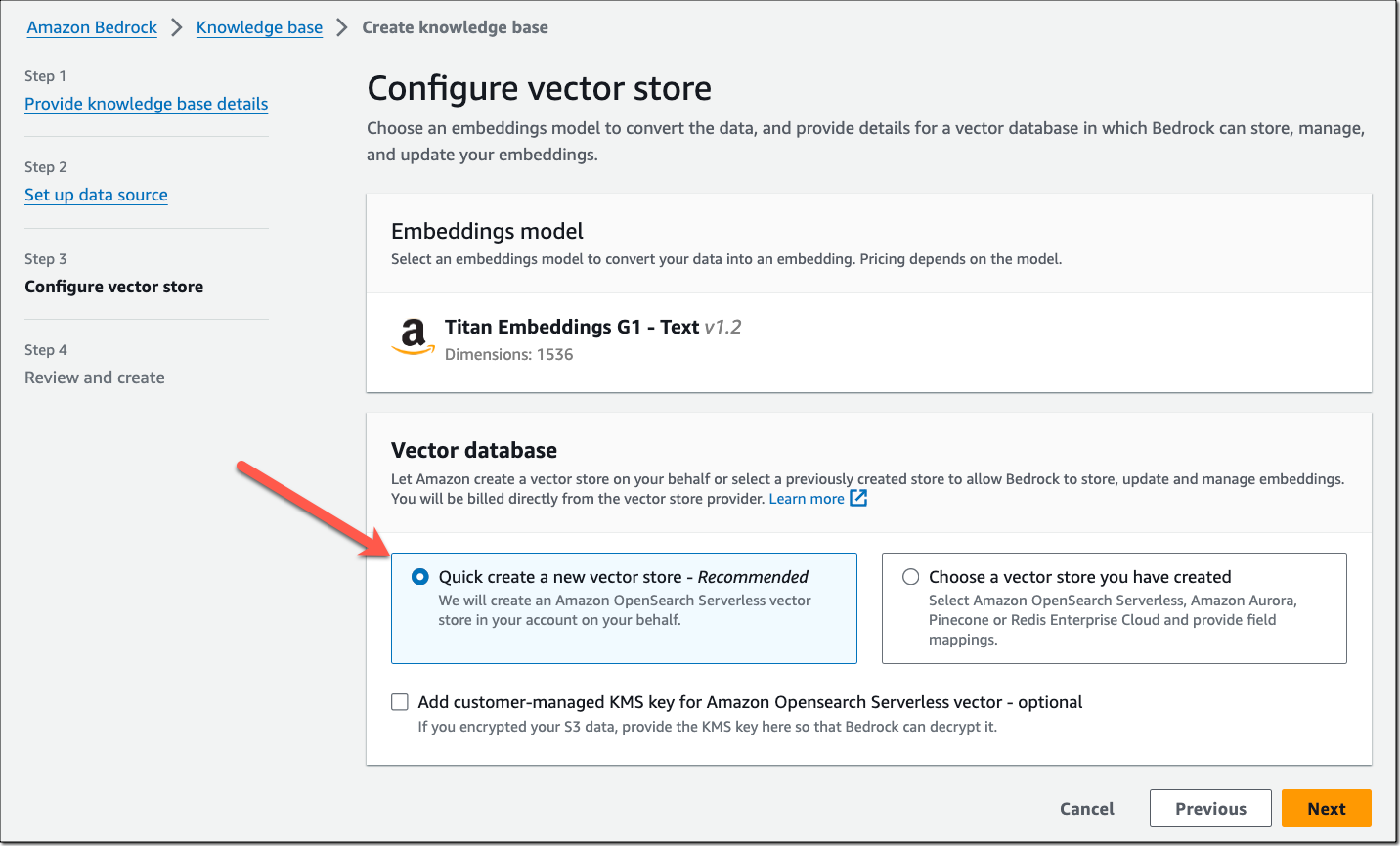
3. Knowledge Bases in Amazon Bedrock
RAG (Retrieval Augmented Generation) is a powerful technique, but it takes significant effort to build data pipelines to support continuous ingestion from data sources to your vector databases. Knowledge Bases in Amazon Bedrock delivers a fully managed RAG experience. You can pick Amazon OpenSearch Serverless as the default vector database or choose from other available options.
I took it for a spin and it was so much easier to have my datasets ready for QnA - configure the Knowledge Base, load data in Amazon S3, sync it, and you're ready to go.
Check out this great blog post and refer to the documentation once you're ready to give it a shot.
P.S.: More content coming soon, especially around how you can use this from your Go applications and some open-source integrations as well. Stay tuned!
There were a bunch of Vector database engines announced during this re: Invent!
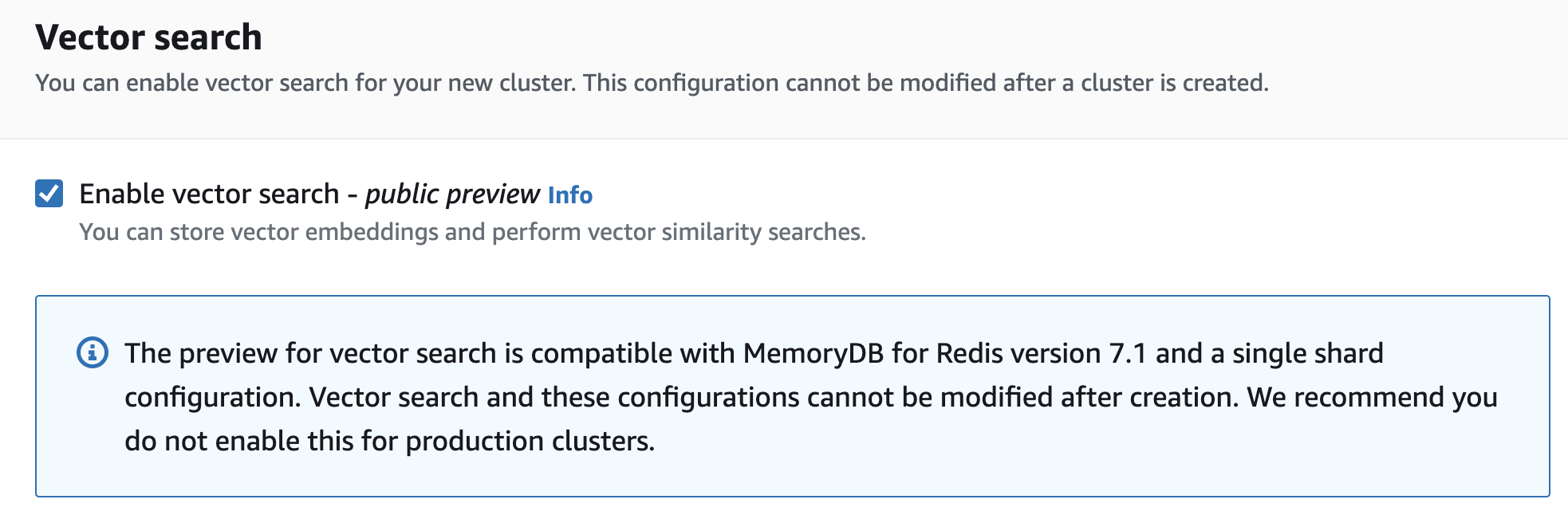
4. Vector Search for Amazon MemoryDB for Redis (Preview)
Now you can use familiar Redis APIs for machine learning and generative AI use cases such as retrieval-augmented generation, anomaly detection, document retrieval, and real-time recommendations. Amazon MemoryDB for Redis now lets you store, index, and search vectors. At the time of writing, it's in preview but I encourage you to try it out. Check out the documentation for details including the supported vector search commands.
Don’t forget to activate Vector search while creating a new MemoryDB Cluster!
5. Vector Engine for Amazon Open Search Serverless Is Now GA
Underneath the hood, vector database capability uses k-NN search in OpenSearch. As I mentioned, OpenSearch Serverless is already one of the vector database options in the Knowledge Base for Amazon Bedrock. Now you can create a specialized vector engine–based collection. The cool thing to note is that Amazon OpenSearch supported about 20 million vector embeddings during preview. Now (post GA), this limit has been raised to support a billion vector scale.
I also recommend checking out this blog post that goes into vector database capabilities in-depth.
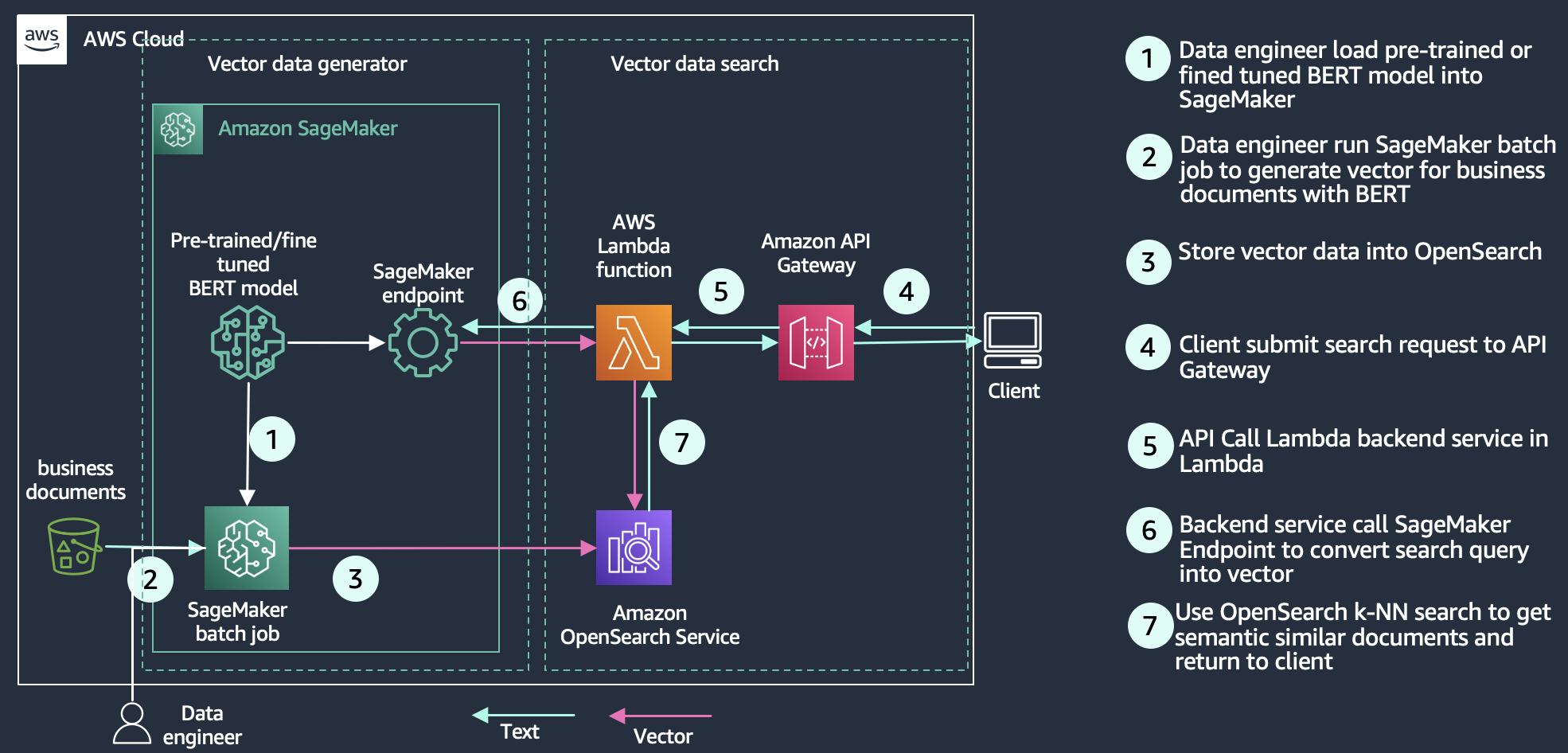
6. Vector Search for Amazon DocumentDB
Vector search is now built into DocumentDB as well. You can set up, operate, and scale databases for ML/AI applications without separate infrastructure. Take a look at the documentation to dive in deeper before creating your first vector collection!
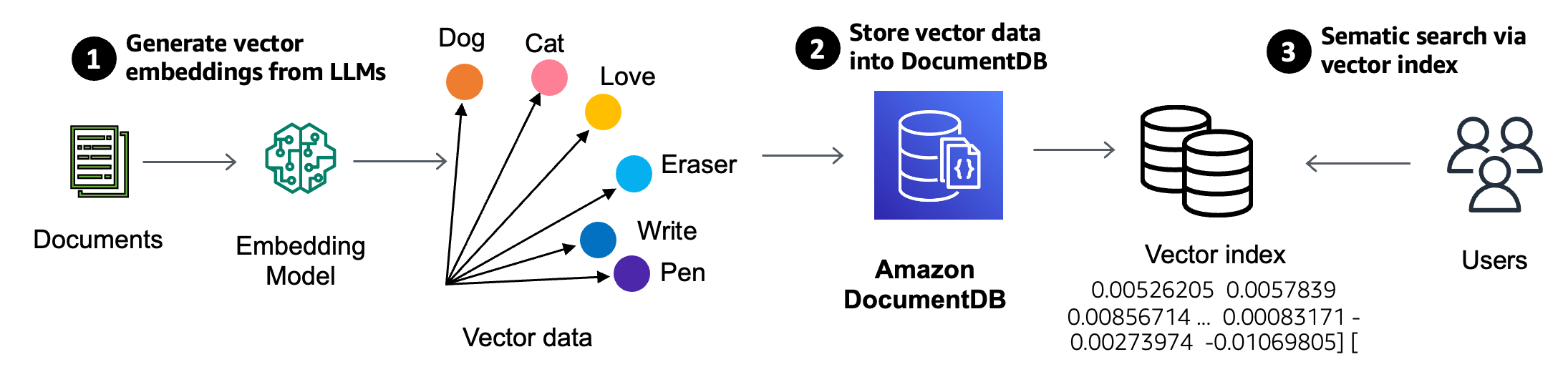
7. Agents for Amazon Bedrock, Now GA Too!
Agents in Amazon Bedrock aid with the development of GenAI apps by providing a platform to orchestrate multi-step tasks. The instructions we provide are used to create an orchestration plan which is then carried out by invoking APIs and accessing knowledge bases (using RAG).
Amazon Bedrock makes it easy to get started with Agents by providing a working draft of an existing agent. Head over to the AWS console to try it out select the Test button and enter a sample user request. To dive in deeper, refer to the documentation, including how to use the Agents API.
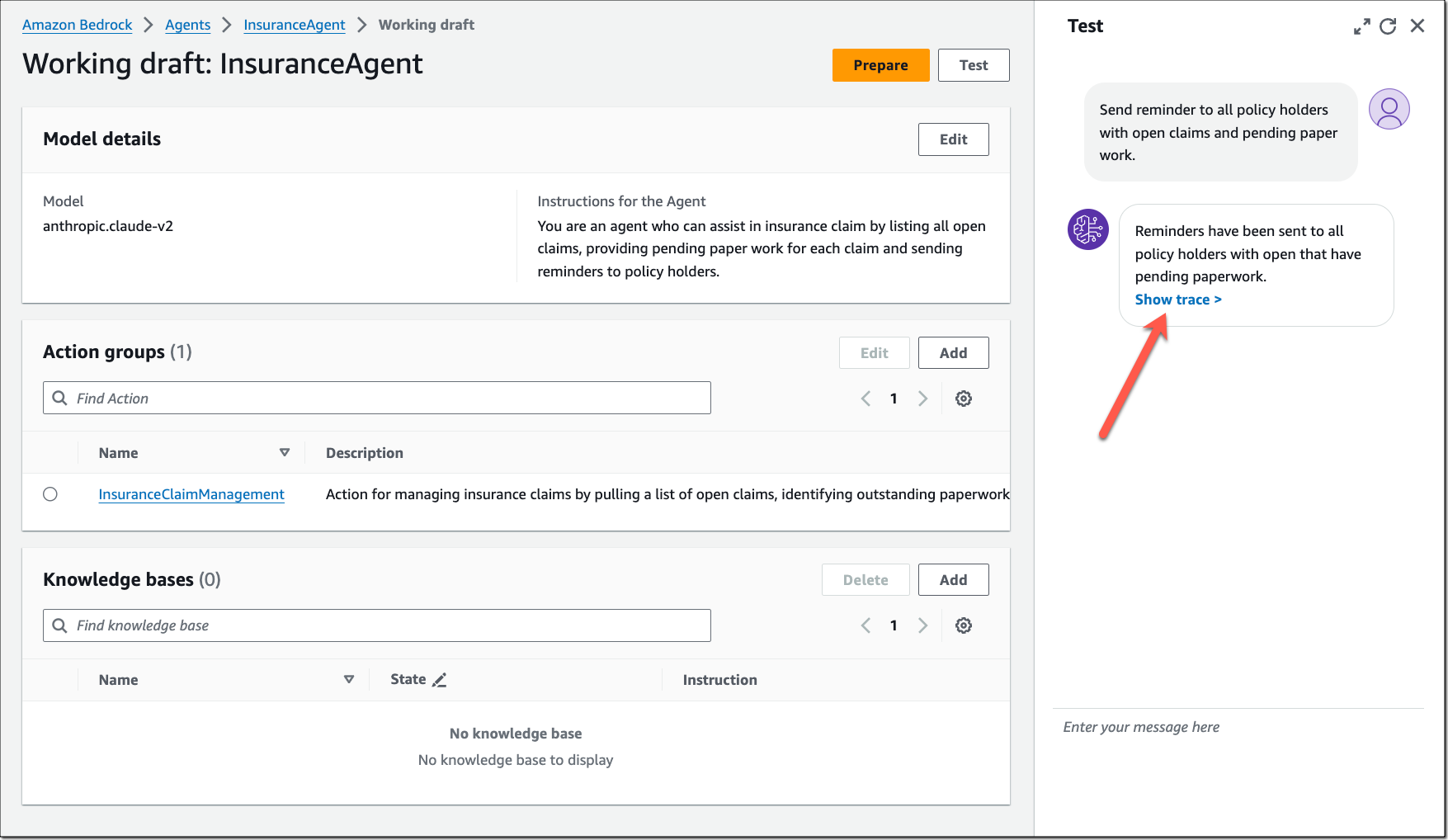
8. Amazon DynamoDB Zero-ETI Integration With Amazon Open Search Service
Ok, you love Amazon DynamoDB and have tons of data in it. How do you make it easily searchable? I'm sure you've found different ways of making that happen. But zero-ETL integration simplifies data synchronization from Amazon DynamoDB to Amazon OpenSearch Service - no need to write custom ETL pipelines!
Read up on the announcement, check out the blog post, and follow along in the documentation when you are ready to take it for a spin.
9. Amazon Q: A Generative AI-Powered Assistant (Preview)
Amazon Q is being integrated into services such as Amazon CodeCatalyst and Amazon QuickSight. It's also available in the AWS console and your IDE. Its set of capabilities is built to support developers and IT professionals alike - be it helping you optimize EC2 instance type selection, build the next serverless app, or upgrade your Java apps!
10. AWS SDK for Rust
(Last but definitely, not least)
Ok, I may not be actively using Rust as I was a while back, but I still have a soft spot for it. And that's why I am happy to see the GA announcement for AWS SDK for Rust which means you can use it for production workloads! I haven't taken it for a (re)spin yet, but when I do, I will be using the getting started guide to refresh my memory.
The AWS SDK for Rust contains one crate for each AWS service - you can check them out here.

That's it for my short (and completely biased) top picks for this year. I couldn't make it to re: Invent this time (last-minute emergency), but I hope to see you all in 2024.
Published at DZone with permission of Abhishek Gupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments