NoSQL Database Types
In this article, excerpted from Introducing Data Science, we will introduce you to the four big NoSQL database types. Read on for more info.
Join the DZone community and get the full member experience.
Join For Free
By Davy Cielen, Arno D. B. Meysman, and Mohamed Ali
In this article, excerpted from Introducing Data Science, we will introduce you to the four big NoSQL database types.
There are four big NoSQL types: key-value store, document store, column-oriented database, and graph database. Each type solves a problem that can’t be solved with relational databases. Actual implementations are often combinations of these. OrientDB, for example, is a multi-model database, combining NoSQL types. OrientDB is graph database where each node is a document.
Before going into the different NoSQL databases, let’s look at relational databases so you have something to compare them to. In data modelling, many approaches are possible. Relational databases generally strive toward normalization: making sure every piece of data is stored only once. Normalization marks their structural setup. If, for instance, you want to store data about a person and their hobbies, you can do so with two tables: one about the person and one about their hobbies. As you can see in figure 1, an additional table is necessary to link hobbies to persons because of their many-to-many relationship: a person can have multiple hobbies and a hobby can have many persons practicing it.
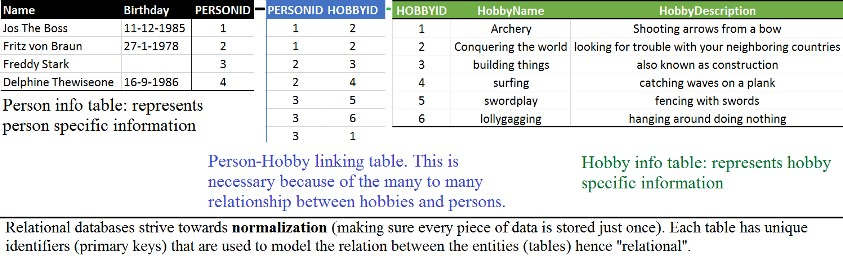
Figure 1 Relational databases strive toward normalization (making sure every piece of data is stored only once). Each table has unique identifiers (primary keys) that are used to model the relation between the entities (tables), hence the term relational.
A full-scale relational database can be made up of many entity and linking tables. Now that you have something to compare NoSQL to, let’s look at the different types.
COLUMN-ORIENTED DATABASE
Traditional relational databases are row-oriented, with each row having a row-id and each field within the row stored together in a table. Let’s say, for example’s sake, that no extra data about hobbies is stored and you have only a single table to describe people, as shown in figure 6.8. Notice how in this scenario you have slight denormalization because hobbies could be repeated. If the hobby information is a nice extra but not essential to your use case, adding it as a list within the Hobbies column is an acceptable approach. But if the information isn’t important enough for a separate table, should it be stored at all?

Figure 2 Row-oriented database layout. Every entity (person) is represented by a single row, spread over multiple columns.
Every time you look something up in a row-oriented database, every row is scanned, regardless of which columns you require. Let’s say you only want a list of birthdays in September. The database will scan the table from top to bottom and left to right, as shown in figure 3, eventually returning the list of birthdays.

Figure 3 Row-oriented lookup: from top to bottom and for every entry, all columns are taken into memory.
Indexing the data on certain columns can significantly improve lookup speed, but indexing every column brings extra overhead and the database is still scanning all the columns.
Column databases store each column separately, allowing for quicker scans when only a small number of columns are involved; see figure 4.
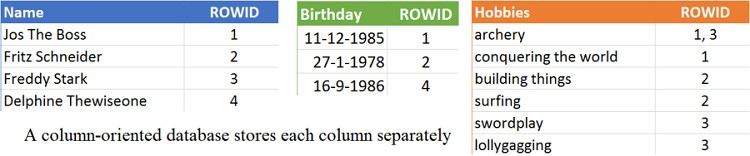
Figure 4 Column-oriented databases store each column separately with the related row numbers. Every entity (person) is divided over multiple tables.
This layout looks an awful lot like a row-oriented database with an index on every column. A database index is a data structure that allows for quick lookups on data at the cost of storage space and additional writes (index update). An index maps the row number to the data, whereas a column database maps the data to the row numbers; in that way counting becomes quicker, so it’s easy to see how many people like archery, for instance. Storing the columns separately also allows for optimized compression because there’s only one data type per table.
When should you use a row-oriented database and when should you use a column-oriented database? In a column-oriented database it’s easy to add another column because none of the existing columns are affected by it. But adding an entire record requires adapting all tables. This makes the row-oriented database preferable over the column-oriented database for online transaction processing (OLTP) because this implies adding or changing records constantly.
The column-oriented database shines when performing analytics and reporting: summating values and counting entries. A row-oriented database is often the operational database of choice for actual transactions (such as sales). Overnight batch jobs bring the column-oriented database up to date, supporting lightning-speed lookups and aggregations using MapReduce algorithms for reports. Examples of column-family stores are Apache HBase, Facebook’s Cassandra, Hypertable, and the grandfather of wide-column stores, Google BigTable.
KEY-VALUE STORES
Key-value stores are the least complex of the NoSQL databases. They are, as the name suggests, a collection of key-value pairs, as shown in figure 5, and this simplicity makes them the most scalable of the NoSQL database types, capable of storing huge amounts of data.
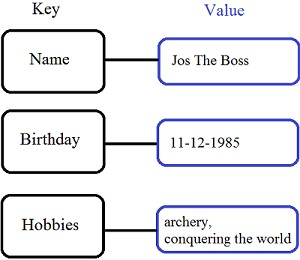
Figure 5 Key-value stores store everything as a key and a value.
The value in a key-value store can be anything: a string, a number, but also an entire new set of key-value pairs encapsulated in an object. Figure 6 shows a slightly more complex keyvalue structure. Examples of key-value stores are Redis, Voldemort, Riak, and Amazon’s Dynamo.

Figure 6 Key-value nested structure.
DOCUMENT STORES
Document stores are one step up in complexity from key-value stores: a document store does assume a certain document structure that can be specified with a schema. Document stores appear the most natural among the NoSQL database types because they’re designed to store everyday documents as is, and they allow for complex querying and calculations on this often already aggregated form of data. The way things are stored in a relational database makes sense from a normalization point of view: everything should be stored only once and connected via foreign keys. Document stores care little about normalization as long as the data is in a structure that makes sense. A relational data model doesn’t always fit well with certain business cases.
Newspapers or magazines, for example, contain articles. To store these in a relational database, you need to chop them up first: the article text goes in one table, the author and all the information about the author in another, and comments on the article when published on a website go in yet another. As shown in figure 7, a newspaper article can also be stored as a single entity; this lowers the cognitive burden of working with the data for those used to seeing articles all the time. Examples of document stores are MongoDB and CouchDB.

Figure 7 Document stores save documents as a whole, whereas RDMS cuts up the article and saves it in several tables. The example was taken from the Guardian website.
GRAPH DATABASES
The last big NoSQL database type is the most complex one, geared toward storing relations between entities in an efficient manner. When the data is highly interconnected, such as for social networks, scientific paper citations, or capital asset clusters, graph databases are the answer. Graph or network data has two main components:
Node—: The entities themselves. In a social network this could be people.
Edge: The relationship between two entities. This relationship is represented by a line and has its own properties. An edge can have a direction, for example, if the arrow indicates who is whose boss.
Graphs can become incredibly complex given enough relation and entity types. Figure 8 already shows that complexity with only a limited number of entities. Graph databases like Neo4j also claim to uphold ACID, whereas document stores and key-value stores adhere to BASE.
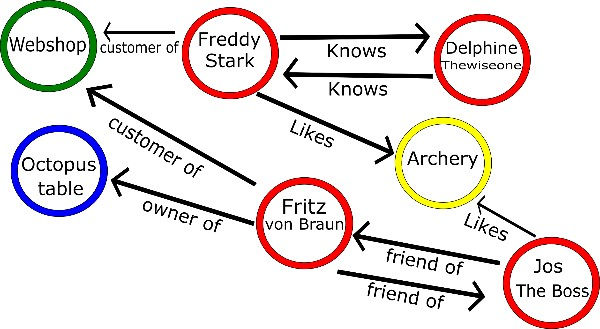
Figure 8 Graph data example with four entity types (person, hobby, company, and furniture) and their relations without extra edge or node information.
The possibilities are endless, and because the world is becoming increasingly interconnected, graph databases are likely to win terrain over the other types, including the still-dominant relational database. A ranking of the most popular databases and how they’re progressing can be found at http://db-engines.com/en/ranking.
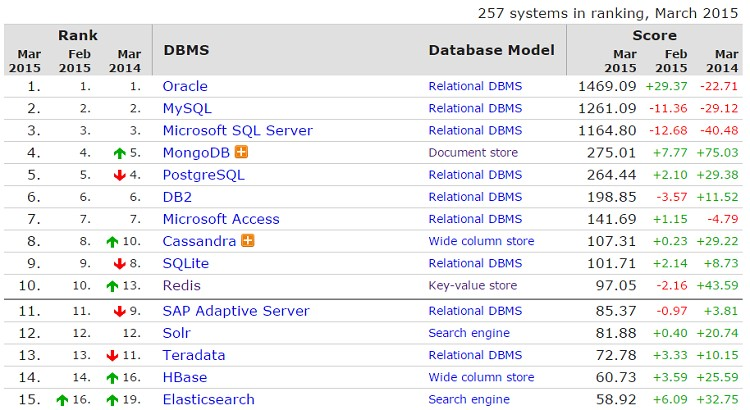
Figure 9 Top 15 databases ranked by popularity according to DB-Engines.com in March 2015.
Figure 9 shows that with nine entries, relational databases still dominate the top 15 at the time this book was written, and with the coming of NewSQL we can’t count them out yet. Neo4j, the most popular graph database, can be found at position 23 at the time of writing, with Titan at position 53.
Opinions expressed by DZone contributors are their own.
Comments