Optimizing Vector Search Performance With Elasticsearch
Optimize vector search in Elasticsearch through dimensionality reduction, efficient indexing, and automated parameter tuning for faster, more accurate results.
Join the DZone community and get the full member experience.
Join For FreeIn an era characterized by an exponential increase in data generation, organizations must effectively leverage this wealth of information to maintain their competitive edge. Efficiently searching and analyzing customer data — such as identifying user preferences for movie recommendations or sentiment analysis — plays a crucial role in driving informed decision-making and enhancing user experiences. For instance, a streaming service can employ vector search to recommend films tailored to individual viewing histories and ratings, while a retail brand can analyze customer sentiments to fine-tune marketing strategies.
As data engineers, we are tasked with implementing these sophisticated solutions, ensuring organizations can derive actionable insights from vast datasets. This article explores the intricacies of vector search using Elasticsearch, focusing on effective techniques and best practices to optimize performance. By examining case studies on image retrieval for personalized marketing and text analysis for customer sentiment clustering, we demonstrate how optimizing vector search can lead to improved customer interactions and significant business growth.
What Is Vector Search?
Vector search is a powerful method for identifying similarities between data points by representing them as vectors in a high-dimensional space. This approach is particularly useful for applications that require rapid retrieval of similar items based on their attributes.
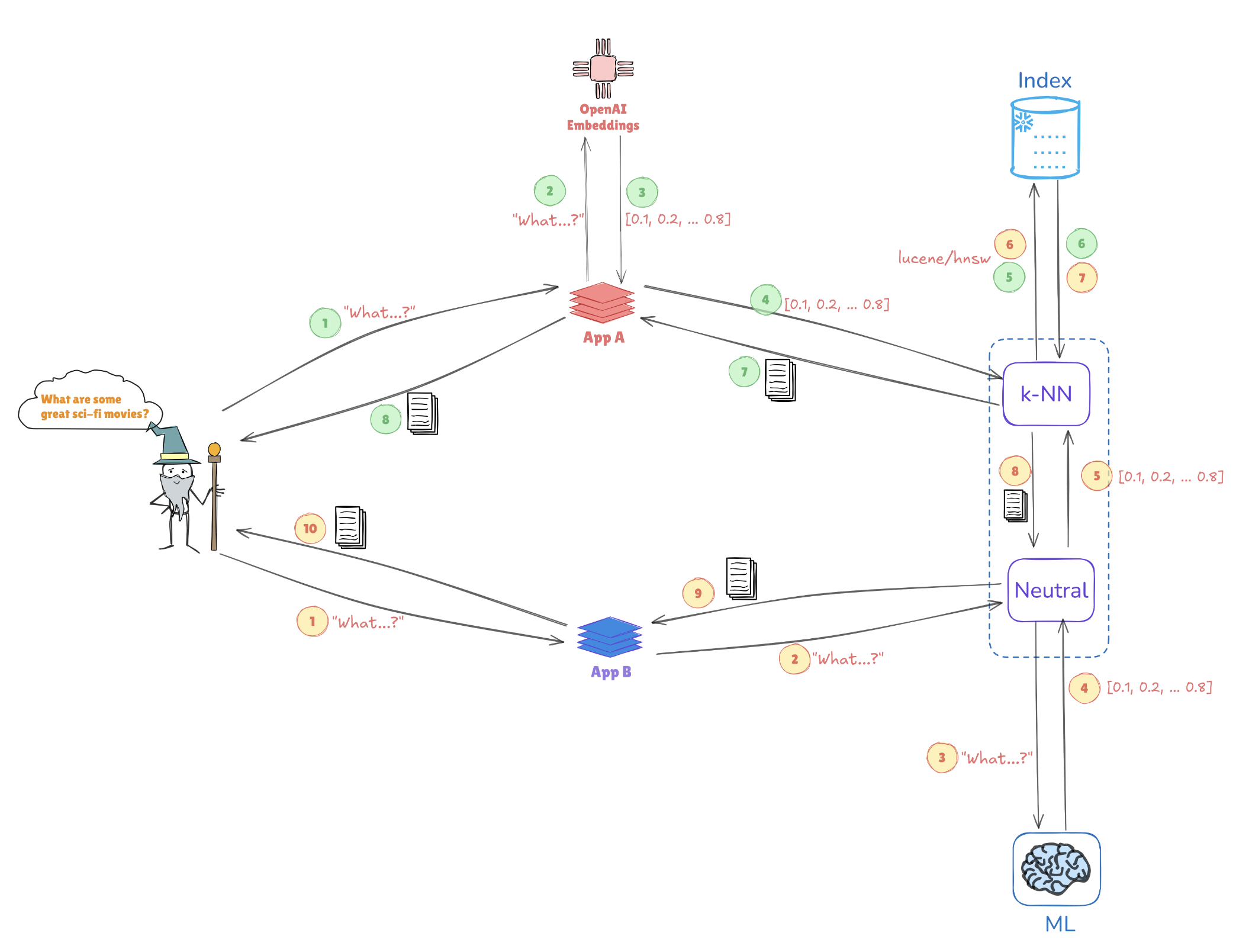
Illustration of Vector Search
Consider the illustration below, which depicts how vector representations enable similarity searches:
- Query embeddings: The query "What are some great sci-fi movies?" is converted into a vector representation, such as [0.1, 0.2, ..., 0.4].
- Indexing: This vector is compared against pre-indexed vectors stored in Elasticsearch (e.g., from applications like AppA and AppB) to find similar queries or data points.
- k-NN Search: Using algorithms like k-Nearest Neighbors (k-NN), Elasticsearch efficiently retrieves the top matches from the indexed vectors, helping to identify the most relevant information quickly.
This mechanism allows Elasticsearch to excel in use cases such as recommendation systems, image searches, and natural language processing, where understanding context and similarity is key.
Key Benefits of Vector Search With Elasticsearch
High Dimensionality Support
Elasticsearch excels in managing complex data structures, essential for AI and machine learning applications. This capability is crucial when dealing with multi-faceted data types, such as images or textual data.
Scalability
Its architecture supports horizontal scaling, enabling organizations to handle ever-expanding datasets without sacrificing performance. This is vital as data volumes continue to grow.
Integration
Elasticsearch works seamlessly with the Elastic stack, providing a comprehensive solution for data ingestion, analysis, and visualization. This integration ensures that data engineers can leverage a unified platform for various data processing tasks.
Best Practices for Optimizing Vector Search Performance
1. Reduce Vector Dimensions
Reducing the dimensionality of your vectors can significantly enhance search performance. Techniques like PCA (Principal Component Analysis) or UMAP (Uniform Manifold Approximation and Projection) help maintain essential features while simplifying the data structure.
Example: Dimensionality Reduction with PCA
Here’s how to implement PCA in Python using Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Index Efficiently
Leveraging Approximate Nearest Neighbor (ANN) algorithms can significantly speed up search times. Consider using:
- HNSW (Hierarchical Navigable Small World): Known for its balance of performance and accuracy.
- FAISS (Facebook AI Similarity Search): Optimized for large datasets and capable of utilizing GPU acceleration.
Example: Implementing HNSW in Elasticsearch
You can define your index settings in Elasticsearch to utilize HNSW as follows:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Batch Queries
To enhance efficiency, batch processing of multiple queries in a single request minimizes overhead. This is particularly useful for applications with high user traffic.
Example: Batch Processing in Elasticsearch
You can use the _msearch endpoint for batch queries:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Use Caching
Implement caching strategies for frequently accessed queries to decrease computational load and improve response times.
5. Monitor Performance
Regularly analyzing performance metrics is crucial for identifying bottlenecks. Tools like Kibana can help visualize this data, enabling informed adjustments to your Elasticsearch configuration.
Tuning Parameters in HNSW for Enhanced Performance
Optimizing HNSW involves adjusting certain parameters to achieve better performance on large datasets:
M(maximum number of connections): Increasing this value enhances recall but may require more memory.EfConstruction(dynamic list size during construction): A higher value leads to a more accurate graph but can increase indexing time.EfSearch(dynamic list size during search): Adjusting this affects the speed-accuracy trade-off; a larger value yields better recall but takes longer to compute.
Example: Adjusting HNSW Parameters
You can adjust HNSW parameters in your index creation like this:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Case Study: Impact of Dimensionality Reduction on HNSW Performance in Customer Data Applications
Image Retrieval for Personalized Marketing
Dimensionality reduction techniques play a pivotal role in optimizing image retrieval systems within customer data applications. In one study, researchers applied Principal Component Analysis (PCA) to reduce dimensionality before indexing images with Hierarchical Navigable Small World (HNSW) networks. PCA provided a notable boost in retrieval speed — vital for applications handling high volumes of customer data — though this came at the cost of minor precision loss due to information reduction. To address this, researchers also examined Uniform Manifold Approximation and Projection (UMAP) as an alternative. UMAP preserved local data structures more effectively, maintaining the intricate details needed for personalized marketing recommendations. While UMAP required greater computational power than PCA, it balanced search speed with high precision, making it a viable choice for accuracy-critical tasks.
Text Analysis for Customer Sentiment Clustering
In the realm of customer sentiment analysis, a different study found UMAP to outperform PCA in clustering similar text data. UMAP allowed the HNSW model to cluster customer sentiments with higher accuracy — an advantage in understanding customer feedback and delivering more personalized responses. The use of UMAP facilitated smaller EfSearch values in HNSW, enhancing search speed and precision. This improved clustering efficiency enabled faster identification of relevant customer sentiments, enhancing targeted marketing efforts and sentiment-based customer segmentation.
Integrating Automated Optimization Techniques
Optimizing dimensionality reduction and HNSW parameters is essential for maximizing the performance of customer data systems. Automated optimization techniques streamline this tuning process, ensuring that selected configurations are effective across diverse applications:
- Grid and random search: These methods offer a broad and systematic parameter exploration, identifying suitable configurations efficiently.
- Bayesian optimization: This technique narrows in on optimal parameters with fewer evaluations, conserving computational resources.
- Cross-validation: Cross-validation helps validate parameters across various datasets, ensuring their generalization to different customer data contexts.
Addressing Challenges in Automation
Integrating automation within dimensionality reduction and HNSW workflows can introduce challenges, particularly in managing computational demands and avoiding overfitting. Strategies to overcome these challenges include:
- Reducing computational overhead: Using parallel processing to distribute workload reduces optimization time, enhancing workflow efficiency.
- Modular integration: A modular approach facilitates the seamless integration of automated systems into existing workflows, reducing complexity.
- Preventing overfitting: Robust validation through cross-validation ensures that optimized parameters consistently perform across datasets, minimizing overfitting and enhancing scalability in customer data applications.
Conclusion
To fully harness vector search performance in Elasticsearch, adopting a strategy that combines dimensionality reduction, efficient indexing, and thoughtful parameter tuning is essential. By integrating these techniques, data engineers can create a highly responsive and precise data retrieval system. Automated optimization methods further elevate this process, allowing for continuous refinement of search parameters and indexing strategies. As organizations increasingly rely on real-time insights from vast datasets, these optimizations can significantly enhance decision-making capabilities, offering faster, more relevant search results. Embracing this approach sets the stage for future scalability and improved responsiveness, aligning search capabilities with evolving business demands and data growth.
Opinions expressed by DZone contributors are their own.
Comments