Overcoming Challenges in End-To-End Microservices Testing
In this guide, we will address critical challenges in end-to-end microservices testing and how you can solve them by staying in sync.
Join the DZone community and get the full member experience.
Join For FreeWeb and mobile application developers around the world are using microservices architecture to build and deliver amazing tech products that are fast, responsive, and highly integrated within an ecosystem.
Unlocking high potential in the context of a rapidly growing tech startup comes with a set of big rewards, so anything which breaks barriers in the development of better tech is appreciated and adopted by all.

Microservice architecture is one such paradigm that is shaping the technical architecture of many popular and upcoming tech products. It is also shaping the way we build teams and assign responsibilities. But like any other powerful area of exploration, this one also comes with a unique set of challenges.
While improving on many aspects of web services architecture, they are also known to introduce some peculiar problems. In this article, we will look at some important challenges in end-to-end testing of applications that are built on microservices architecture.
What Are Microservices?
Web service or service is a term used to describe a web contract that works over protocols like HTTP and acts as an interface between application UI and database. Breaking down a long and complicated business and user story into very small modules and building separate services for each module is basically the essence of microservices architecture.
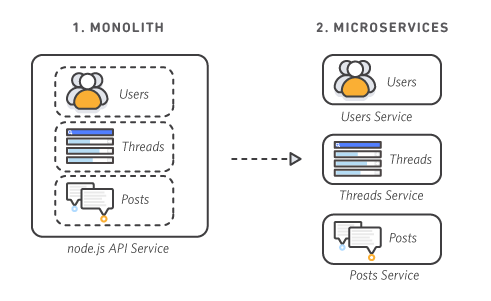
Some key benefits offered by microservices architecture are:
Autonomous development: Instead of having one very large team and project, which is hard to manage, microservice architecture lets you break down your team and code into self-sufficient groups. Teams work and deliver autonomously, leading to a clear delineation of responsibilities and independent work priorities.
Functional specialization: When modules are identified based on business needs and proper team structure is implemented, it leads to each team becoming a specialist in their domain of functionality. This is also helpful during defect analysis.
Dynamic resource allocation: With modern cloud platforms offering on-demand scaling for your application infrastructure, microservices on cloud platforms let you fine-tune for the ultimate resource optimization strategy.
Plug and play: Agile development with microservices enhances the ability to add or remove modules from the application without downtime, which is helpful in scenarios where rapid feature addition is needed in the SDLC.
Application agility: Since the application is not a single monolith, one non-critical failing component generally will not affect all the other working parts, hence rendering the application more agility in failure scenarios.
In a CI/CD environment, a properly implemented microservices architecture helps the technical leadership keep track of the overall progress, as all the steps beyond code committed by developers are automated and trackable through dashboards and other communication tools.
When a contribution is merged in the master repository, a series of chain events are triggered, including testing at all levels.
If tests break, the whole CI/CD pipeline could stop potentially, and fixing the issue could take time. In some cases, microservices architecture tends to increase the complexity of issues. Let us try to understand how.
Unit and Integration Testing of Microservices
Unit tests are the first amongst various layers in application testing. It means testing individual functions of code by writing test code. As you move up the layers of testing, the number of test cases tends to decrease in number but increase in cost and complexity, so testing as much as possible at the level of unit testing is the goal of every honest and dedicated developer.

Integration tests are basically the next layer where unit tests and app functionality are grouped based on broader business functions and tested in batches. Writing unit tests involves a fair deal of back and forth as it requires the developer to not only write the test case once but also to prepare mock input data and external service responses as unit testing is not connected to live DB and services, and also updating all this whenever any change to original function occurs.
Here is how things get tricky:
- A CI/CD flow with a number of microservices integrated into a few streams is a commonly occurring scenario, consider one module with a breaking set of tests has the potential to cause the CI/CD to come to a halt.
- The number of reasons why unit tests fail is so vast that in an environment with dependencies spanning multiple modules and teams, it could take hours or even days in trying to figure out exactly what broke because of the chain reaction effect.
- It is a common scene to find out tests breaking in one module due to recent updates in some other module and because of separation of concerns and internal competition within teams, developers will find it hard to spend time and effort on or co-operate in fixing errors in modules not owned by them.
- While mocking live services from things like payment, booking providers or external data sources, it is important to capture all the nuance of the contract and test for edge scenarios.
- With an accelerated push to develop newer functionality, developers will find it hard to focus on unit test coverage, the application complexity will grow rapidly and consequentially over time it gets more and more difficult to go back and maintain a high-quality test package.
This could very well lead teams to be negligent of unit testing, as with increasing complexity the effort starts sucking in too many resources, and it’s not uncommon for the leadership to say that the juice is not worth the squeeze and cut down heavily on unit and integration tests, which is a short term gain for a potentially big long term cost.
Here are some suggestions that will help you avoid this:
- One simple way could be to layer code modules and test suites based on the priority of flow, i.e., test suites for core business flows are more important than others, and in order to change and modify code for core business flows, you would need more experience and approvals.
- For unit and integration testing, it is advisable that the strategy for writing and executing tests be designed to accommodate the possibility of complexities arising in the future. Also, the test reporting system could be configured to mark test severity appropriately such that only very important flows are set to break a delivery/deployment push.
- It is the job of technical leadership to define solutions to and manage potentially complicated problems like changing external service contracts or highly branched dependencies and make sure all developers are up to date with proper documentation.
Team Management While Developing Microservices
One of the biggest challenges associated with building tech products on microservices architecture is the structure and management of teams working on it and the complexities arising out of that. The main reason for wanting to implement microservices architecture is to supercharge the development process for a rapidly evolving product.
In a fast-growing startup where changes are coming in on a daily basis along with new business and user scenarios, and you are looking to maximize the speed and efficiency of the dev process, that is where microservices are most beneficial. But beneficial only if implemented and executed properly.
If your team is not in sync with your overall technical standards specification, or if there are holes in your specification plan itself, it is easy to find folks struggling to deliver even at average speeds and quality while maintaining an overhead of a bloated delivery line.
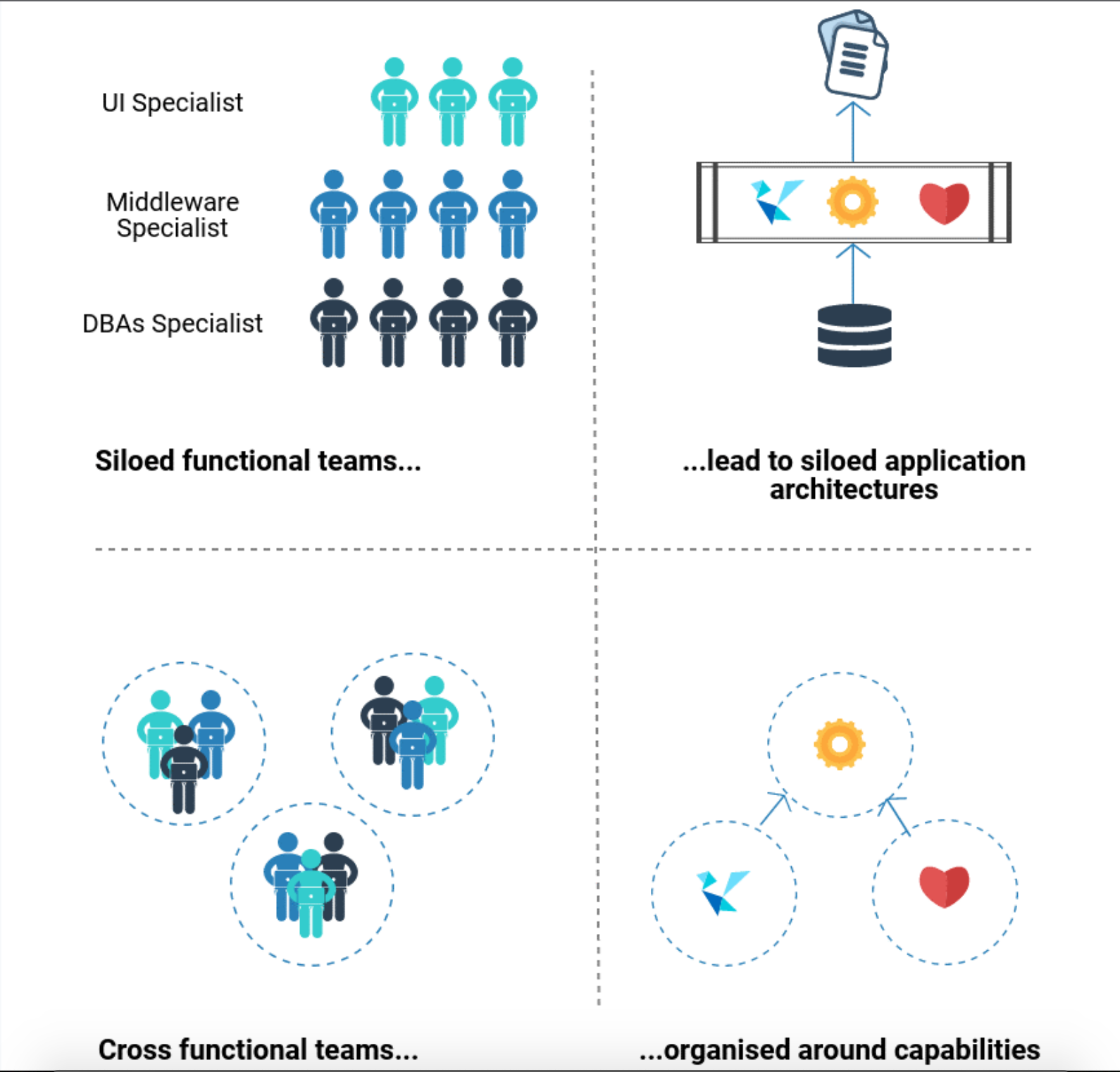
Here is how challenges usually come up:
- When you have a system set up afresh, the complexity is usually manageable, but once you start building modules on top of that, it goes up exponentially.
- As complexity rises, it is the job of technical leadership to observe, understand and control it. Because the tech leadership can get their heads wrapped around what is going on, only then they can guide the developers to do the right thing. But if the leadership fails to do so, turbulent times are more likely to come.
- If leadership fails to contain complexity, it usually leads to a scenario where no one has a 100% picture of what is happening. Resulting in developers having less than ideal command over the application.
- In such cases, things break in unpredictable ways. Imagine ghost service calls and unnecessary batch processes running without proper monitoring or syntax errors and memory leaks causing heavy resource consumption for no reason or some random breakage in non-essential areas causing critical flows to break.
- After something actually breaks and causes trouble, finding the actual point of error and assigning responsibility is also trickier.
How to Avoid
- Although it is desirable to set up the dev sub-teams to work in an asynchronous and independent manner to maximize productivity. You have to ensure that it does not come at the expense of clear responsibility and task allocation within the team. Clear communication regarding critical changes within teams has to be ensured at all times. Plus, a strong culture of writing proper code syntax, with comments and documentation being enforced as a standard within the development team.
- It is recommended that the business and tech leadership work in close synchronicity and ensure minimal confusion regarding the current and future needs of the tech product so that they have a chance to clean up and contain issues. More often than not, we see an over-optimistic business analysis ends up overwhelming a dev team with requirements that don’t even result in any significant improvement or functionality at the user’s end.
- Using automated black-box tests is a strong way to ensure application functionality on the user’s side without having to dive deep into code issues.
Tracking and Fixing Issues
If the leadership fails to fix product and team issues early on time, it is inevitable that they will lead to bugs in customer sessions and cause problems. After an issue is detected by QA and the product team is notified, they are expected to revert back with a report on the cause and fix the issue in the least amount of time.
Here again, we see the complex nature of microservices architecture and distributed team structure creating some more challenges:
- In a scenario where the structure of the application loses proper form and is plagued by bad code when a functionality breaks, QA does its job normally, but for the developer, it gets harder to detect the root cause due to a lack of code comments, documentation and/or proper syntax.
- Due to dependencies, one breakage may lead to a cascade of breakages, which requires an even deeper debug analysis, generally causing more time. This causes the detection of the error part on the dev side to be slightly or significantly delayed.
- In a situation where multiple things break, it’s easy to see finger-pointing among team members, where developers not having a deep understanding of the code package will further delay the detection process.
- When finally the issue is detected and resolved, updating the unit, integration, and other test scripts for that functional portion of code still stands as an added task for the responsible developer.
- After all the accumulated delays due to back and forth between QA and developers, it is easy for the business team to lose consideration for the complicated nature of the tech process and become increasingly hostile, causing tension within the team at large.
This is the worst nightmare for all tech leaders to see their teams descend into dysfunctional modes. And for the business leadership, this could be an even worse disaster when the expensive tech resource pool seems to not be able to command customer confidence and appreciation as per their expectations.
You can try to avoid this by:
- Put in extra effort during the growth phase to keep the business analysis, experience design, quality assurance, and development teams in sync at all times.
- Document, log and monitor communication between all systems and participants because evidence serves better than people’s claims.
- If there is any mistake or miscalculation at the level of system architecture or CI/CD design or implementation, it is better to halt the process and fix the core issue first, even if it is detected after writing a fair bit of code on top of it.
- Try building a culture where human factors are clearly understood, and interpersonal equations running both directions in a hierarchy are managed justly.
- Cooperation and helpfulness within a team should be acknowledged and awarded.
The challenges mentioned here are not simple and will require dedicated analysis and case-specific study to optimally resolve them in real life. And also, the variables of every team and product are different, so what works for one might not even be a viable option for another.
In a case where all attempts to prevent such issues do not bear fruit, and you unwillingly land in the dreadful scene of having to fix a broken system, there are still ways to do it.
Now what I’m going to suggest might seem reasonable to some and controversial to others, but I can assure you that many companies already, in the past, during many moments of downtime where the only priority was to have the working product back online, have ended up doing this, i.e., prioritize Black-box testing on production environment and keep the white-box tests for testing environments and only very critical flows in production.
That way, you get the ability to develop new functionality and components for the production environment without having the added responsibility of making the unit and integration tests work every time you add something. While far from ideal, this could be adopted in an emergency or difficult situation where feedback from a select group of users is more helpful than your QA strategy.
In conclusion, we recommend all participants in the product development/management process be aware of and actively work to avoid these pitfalls in order to gain the maximum benefit from a well-designed microservices ecosystem.
Published at DZone with permission of Vivek Mannotra. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments