Designing a “People You May Know” System With Graph Neural Networks
This article explains a practical design for a LinkedIn-style “People You May Know” system, focusing on real-world tradeoffs, graph embeddings, and low-latency serving.
Join the DZone community and get the full member experience.
Join For FreeWhy This Puzzle Might Be Harder Than It Appears
Most people will feel that this aspect is very simple: The "People You May Know" feature is so easy to use! You log into an app, browse a few suggested friends, and either dismiss them or ask to add them. But once I started thinking through how such a feature would operate at scale, it became clear that it's really a far deeper, more involved architectural problem than meets the eye.
At a small scale, a platform can get away with naive heuristics like mutual connections, same company, or same school. These signals are valuable and, surprisingly, can work well in many cases. But problems begin when the network is huge, user behavior is more dynamic, and the platform needs to recommend more relevant people even if the connection between two nodes is not visible from a single rule.
That's where graph-based machine learning gets interesting. How would I build a "People You May Know" feature that's ready for production? In this article, I'm going to make my vision clear and then explain, step by step, why using graph neural networks is not an abstract exercise but a practical design problem.
Framing the Problem as Link Prediction
For link prediction, I think this system is about building a social graph. A user is a node. The connections that already exist are the edges. The goal is to predict which pairs of nodes are most likely to connect next.
That view is useful because it lets the system take advantage of profile similarity, history, and graph structure rather than being dependent on any one rule. It also makes it easy to rank recommendations based on their probabilities rather than on our personal intuition.
Starting With the Data
For a system like this, a list of existing links is not enough. I see the data in three levels: user profile data, the connection map itself, and signals of interaction, such as viewing profiles, searching for something, commenting on someone's wall, or sending a connection request.
What I love about this problem is that none of these data sources will provide all the answers. The real value lies in marrying them together in some way. Profile data shows who the user is. The graph indicates where that user is placed within a network. Interaction data shows intention and new relationships that won't necessarily show up in your visible profiles.
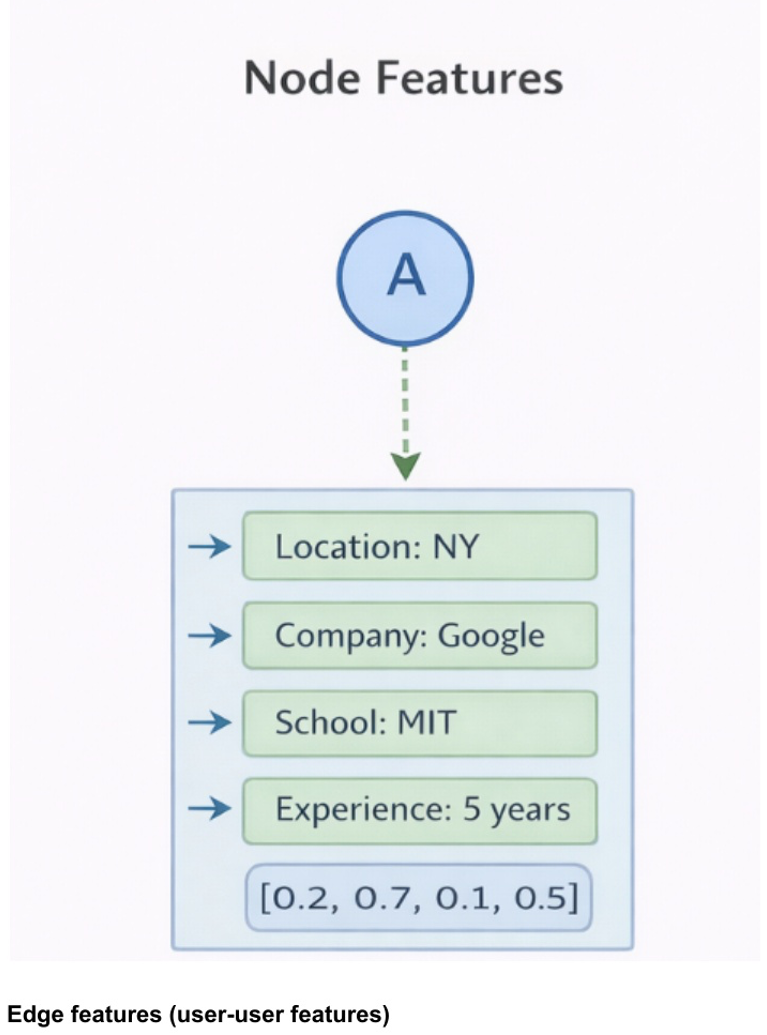
Feature Representation in the Recommendation Graph
The following chart presents a good way to understand how user-level signals and pairwise signals come into this system. It truly depends on both. Strong profile similarity without graph data can ignore the social dimension; meanwhile, only graph data can lose clear professional relevance.
Candidate Generation Comes First
Divide the system into stages and let yourself proceed at a reasonable speed in building things into the system. At an absolutely massive scale. Realistically, you can't score every possible user pair, in any case. Even if the model is strong, the search space simply becomes too great to be reckoned with by either human or machine for very long periods of time.
Therefore, the first stage must be candidate selection. My first candidate for this purpose would be a friends-of-friends strategy; it is instinctive, uses finite computing resources intelligently, and, most of the time, turns out to be a suitable initial filter. In addition to what the product does, we may also take candidates from repeatedly accessed profiles, search co-occurrence, shared professional communities, and other behavioral signals.
Why I Would Use a Graph Neural Network
A simpler ranking method would work well in this case, and a single XGBoost model might well be enough. Indeed, if I were sending out a first version, I could begin by training an XGBoost model with hand-crafted attributes: mutual friends, same company, and the interaction count between different users.
But if the platform is large and the graph structure is deeply meaningful, graph neural networks become quite attractive. A GNN allows each user's representation to benefit from information from neighboring nodes in the graph. Rather than relying solely on hand-engineered features, the model now learns embeddings that take into account both the user’s attributes and the structure of the surrounding network.
How I Would Think About Features
If I were building the feature layer, I would divide it into node and edge features. Node features describe the user: company, school, location, title, experience level, activity level, and account age. Edge features describe two users' relationship: mutual connections, lower company or school, profile access times, interaction frequency, and period.
This separation is helpful because it allows the model to learn who the user is and how the user relates to others. It also keeps the design modular: If the business later decides to add new signals, those features can be included in the existing problem without having to completely rethink the design.
Typical node features: company, school, location, title, experience level, account age, and past activities last year.
Typical edge features: mutual connections, same company or school attended by two users, common friends profile visits repeated over time, and interactions.
score(u, v) = dot(embedding_u, embedding_v)
probability = sigmoid(score(u, v))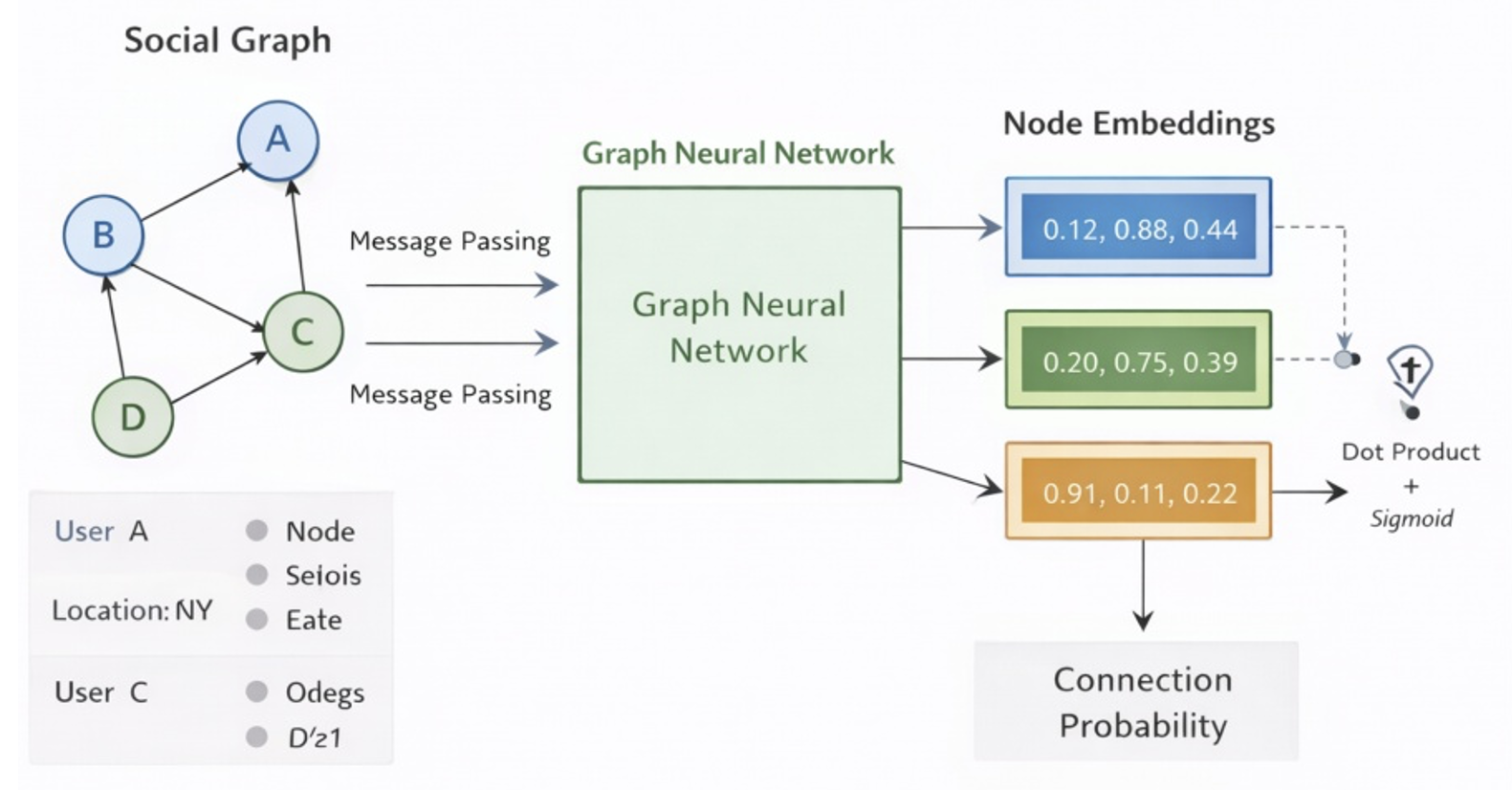
Scoring Connection Likelihood
Can I reach the right answer? You've translated your experiences into immediate, specific problems and questions. Once the GNN produces user embeddings, the next step is to estimate whether two users are likely to connect. A straightforward baseline is to compute a similarity score between the two embeddings and convert it to a probability.
This is optimal only in that it is, first, simple, second, interpretable, and, third but not least, scalable quickly.
Illustrative implementation snippet:
If I wanted to make the article feel more buildable, I would include a small example that shows how embeddings can be generated and then used to score a pair of users. The snippet below is intentionally simple, but it demonstrates the implementation idea without turning the article into a full tutorial.
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GNNLinkPredictor(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, embedding_dim):
super().__init__()
self.conv1 = GCNConv(input_dim, hidden_dim)
self.conv2 = GCNConv(hidden_dim, embedding_dim)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return x
def score_pair(embeddings, user_u, user_v):
score = torch.dot(embeddings[user_u], embeddings[user_v])
return torch.sigmoid(score)
# Example usage:
# embeddings = model(node_features, edge_index)
# probability = score_pair(embeddings, user_u=3, user_v=17)Training View and Evaluation
For example, the training data for such a system would be derived from historical graph snapshots. Imagine two big sets of users: all of those people who have ever formed any kind of connection, and then another, enviable number that are not as close to their friends.
In positive samples, user pairs actually formed connections. In negative samples, user pairs did not. In practice, many user pairs don't link up, and overly easy negatives can make the model look better than it really is.
I would look at offline metrics such as ROC-AUC, Precision@K, Recall@K, and MAP (Mean Average Precision).
For a recommendation system, online behavior could be broken down into several sub-issues: how many requests were sent over the course of time, what proportion were accepted, and finally, whether the suggestions by recommendation systems led to meaningful new connections.
Illustrative Training Pairs
User A
User B
Label
A
D
1
B
E
1
A
F
0
C
G
0
| User A | User B | Label |
|---|---|---|
|
A |
D |
1 |
|
B |
E |
1 |
|
A |
F |
0 |
|
C |
G |
0 |
To ensure romance works, matchmaking is essential. If the AI gets the task done for you faster and better, superb. With no experimental results yet, you should draw on well-studied approaches. If I were putting together enough data for today's large datasets to notice an improvement in quality through personalized recommendation scores, I would use some existing method and only customize it later.
This must establish its purpose quickly so that a pragmatic person can apply pragmatic thinking to help meet that purpose. The quotation about geometric relationships is significant. To make something like Pong, for example, all the player really needs is some interactive experience that provides a frame of reference. An early "invention" was therefore able to succeed because, although there were no rules, it could still achieve an outcome.
At the beginning of this chapter, as in the previous paragraphs, I have noted the importance of maintaining a balance between surveillance and risk reduction.
While our accelerating progress in computing virtually guarantees that the present analytic and decision-making boundaries that separate humans from machines will eventually become obsolete, they are clearly in place now. Directing the eye straight to the mind's eye, this training method sought to teach people at all levels to find their own direction and to prudently over-determine the details of their work. It took every movement, every technique, at least five times to reach this level, even though those doing the training usually only did one movement or just part of it many times. But although we were strict about perfecting the forms and every detail, we tried as much as possible to avoid becoming too rote and to ensure that students always developed good judgment.
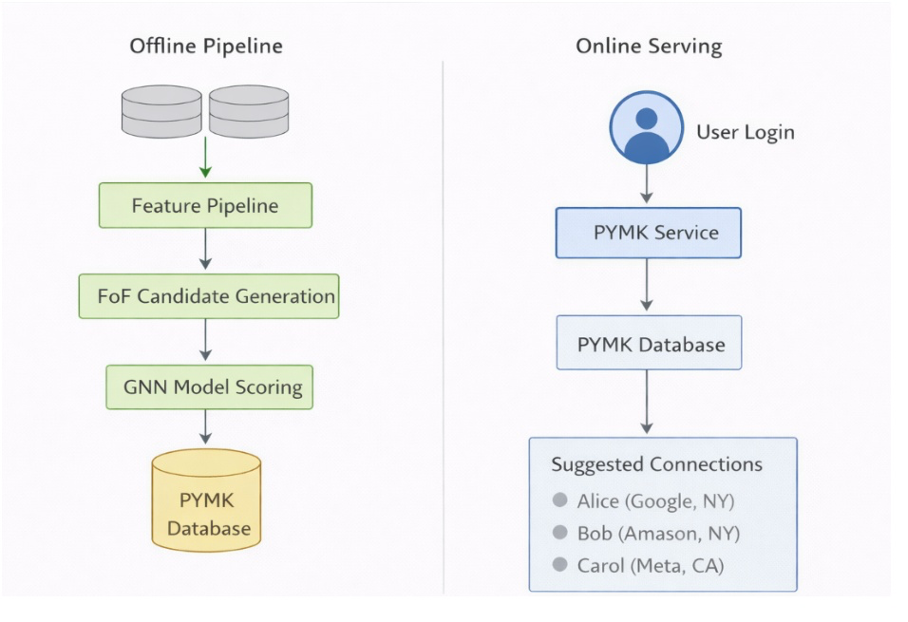
A Practical Technology Stack
layer
likely technologies
Streaming / ingestion
Kafka or Kinesis
Feature pipeline
Spark or Flink
Graph modeling
PyTorch Geometric, DGL, or custom graph training pipeline
Embedding search
FAISS or another ANN index
Storage/serving
Cassandra, Redis, or a recommendation database
API layer
Kubernetes-hosted microservice for retrieval and ranking
| layer | likely technologies |
|---|---|
|
Streaming / ingestion |
Kafka or Kinesis |
|
Feature pipeline |
Spark or Flink |
|
Graph modeling |
PyTorch Geometric, DGL, or custom graph training pipeline |
|
Embedding search |
FAISS or another ANN index |
|
Storage/serving |
Cassandra, Redis, or a recommendation database |
|
API layer |
Kubernetes-hosted microservice for retrieval and ranking |
Production Realities I Would Watch Closely
The hard part is not only training a GNN. The hard part is making the entire system operational. New users create cold-start problems. Recommendations become stale if the refresh cycle is too slow. Embedding search becomes expensive as the graph grows. And there is often a gap between offline metric lift and online user value.
If I were operating this system in production, I would closely monitor freshness, latency, cold-start behavior, and acceptance rate. A model that looks elegant on paper but fails on these dimensions does not really solve the product problem.
Why I Still Would Not Start With a GNN Immediately
If such an approach of failure is to be avoided, an alternative first move lies within the remit of this article to tell us. For the choice of algorithm, I might start by trying two common classification methods: decision trees and nearest-neighbour. We try something like this, the first version, which all depends on candidates, + a simpler ordered model than a graph neural network that uses features hand-engineered. In the future, as the platform expands and manual features no longer suffice, I would then figure out how to make it a graph format and decide whether this additional complexity is worth its cost. In my view, that is the way forward: explore lightly, test deep, then scale complexity where it really counts.
Final Thoughts
The point of interest of "People You May Know" is that it is at the intersection between machine learning and system design. It's not sufficient to construct good models. The system also needs to generate candidates efficiently, refresh signals at the right times, serve suggestions with low latency, and behave in a way that is equitable for both highly connected users and new ones.
In other words, the recommendation system that, at the end of the day, is best is not necessarily one with the most elegant model. It's getting people to encounter the right connections at the wrong time on a regular basis, which is absolute tops.
Opinions expressed by DZone contributors are their own.
Comments