PostgreSQL Backup and Recovery Automation
Let's explore how to backup and recover PostgreSQL databases.
Join the DZone community and get the full member experience.
Join For FreeA critical PostgreSQL client contains valuable data, and PostgreSQL databases should be backed up regularly. Its process is quite simple, and it is important to have a clear understanding of the techniques and assumptions.
SQL Dump
The idea behind this dump method is to generate a text file from DataCenter1 with SQL commands that, when fed back to the DataCenter2 server, will recreate the database in the same state as it was at the time of the dump. In this case, if the Client cannot access the primary server, they can have access to the BCP server. PostgreSQL provides the utility program pg_dump for this purpose. The basic usage of this command is: pg_dump dbname >backupoutputfile.db.
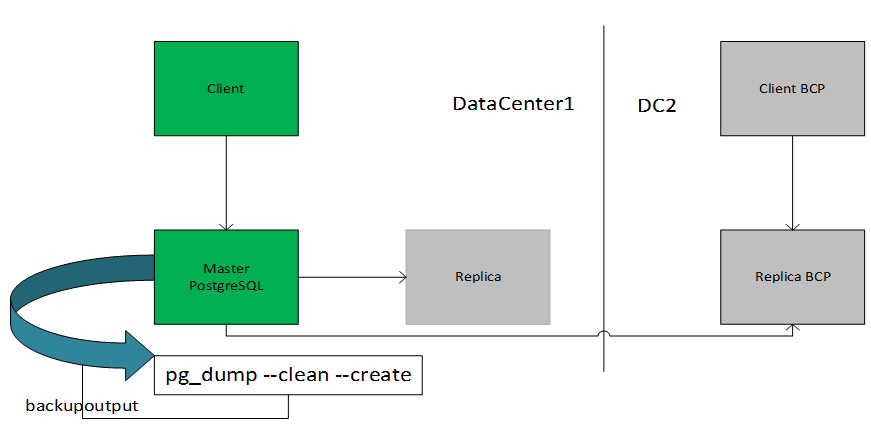
As you can see, pg_dump writes its results to the standard output. Below, we will see how this can be useful.
pg_dump is a regular PostgreSQL client application. This means that you can do this backup procedure from any remote host that has access to the database. pg_dump does not operate with special permissions. In particular, it must have read access to all tables that you want to back up, so in practice, you almost always have to run it as a database superuser.
Dumps created by pg_dump are internally consistent, that is, the dump represents a snapshot of the database as of the time pg_dump begins running. pg_dump does not block other operations on the database while it is working. (Exceptions with an exclusive lock, such as most forms of ALTER TABLE.)
Important: If your database schema relies on OIDs (for instance as foreign keys), you must instruct pg_dump to dump the OIDs as well. To do this, use the -o command-line option.
SQL Dump Automation
- First, create playbook pgbackup.yml
- Create role pgbackup, and it will be called from pgbackup.yml
Pgbackup.yml
---
- hosts: database_prim:database_replica
gather_facts: true
vars_files:
- mysecret_vars/{{ environ }}.yml
# This is to Identify if DB is Primary and replicating data to secondary
tasks:
- name: select pg status
command: psql -c "SELECT pg_is_in_recovery();"
register: IsPromoted
changed_when: False
environment:
PGDATABASE: "{{ pg_database }}"
PGUSER : "{{ pg_username }}"
PGPASSWORD : "{{ pg_password }}"
#Get the DB parameter from run time on Client application, Not required if you have parameters
- block:
- name: Get client database settings
shell: "awx-manage print_settings | grep '^DATABASES'"
register: results
changed_when: False
delegate_to: "{{ groups['client’][0] }}"
- name: Ingest client database settings
set_fact:
client_db_settings: "{{ results.stdout | regex_replace('DATABASES\\s+= ', '') }}"
delegate_to: "{{ groups['client'][0] }}"
- include_role:
name: pgbackup
when: "'f' in IsPromoted.stdout"
tags: pgbackup- pgbackup role
---
- name: Determine the timestamp for the backup.
set_fact:
now: '{{ lookup("pipe", "date +%F-%T") }}'
- name: Create a directory for a backup to live.
file:
path: '{{ backup_dir.rstrip("/") }}/{{ now }}/'
mode: 0775
owner: root
state: directory
- name: Create a directory for non-instance specific backups
file:
path: '{{ backup_dir.rstrip("/") }}/common/'
mode: 0775
owner: root
state: directory
# create dump, Here adding runtime param. You can add param whatever ways
- name: Perform a PostgreSQL dump.
shell: "pg_dump --clean --create --host='{{ client_db_settings.default.HOST }}' --port={{ client_db_settings.default.PORT }} --username='{{ tower_db_settings.default.USER }}' --dbname='{{ tower_db_settings.default.NAME }}' > pgbackup.db"
args:
chdir: '{{ backup_dir.rstrip("/") }}/common/'
environment:
PGPASSWORD: "{{ client_db_settings.default.PASSWORD }}"
- name: Copy file with owner and permissions
copy:
src: '{{ backup_dir.rstrip("/") }}/common/pgbackup.db'
dest: '{{ backup_dir.rstrip("/") }}/{{ now }}/'
remote_src: yes[all:vars]
# database settings
.linux.us.ams1907.com
[client]
linuxclient.us.com
[database_prim]
linuxmas.us.com
[database_replica]
linuxreplica.us.commysecret_vars/{{ environ }}.yml
ansible-vault encrypt mysecretvar.ymlStore this kind of param: pg_password, pg_username & pg_database
Restoring the Dump
The text files created by pg_dump are intended to be read by the psql program. The general command form to restore a dump is psql dbname < infile
Recovering in Data Center2
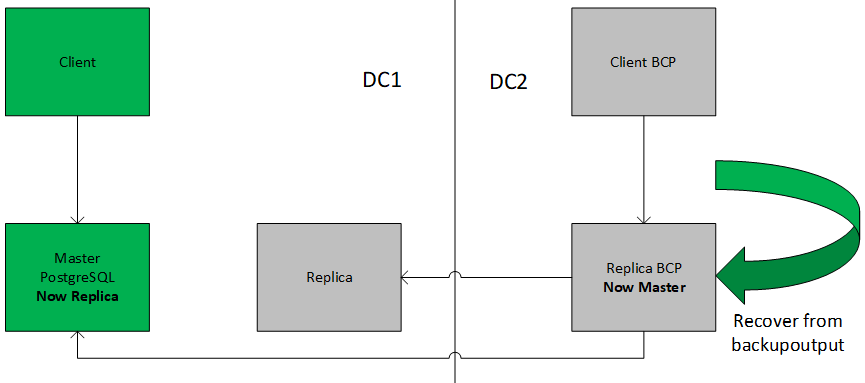
Infile is what you used as backupoutputfile for the pg_dump command. The database dbname will not be created by this command, so you must create it yourself from template0 before executing psql (e.g., with createdb -T template0 dbname). psql supports options similar to pg_dump's for specifying the database server to connect to and the username to use. See the psql reference page for more information.
Before restoring a SQL dump, all the users who own objects or were granted permissions on objects in the dumped database must already exist. If they do not, then the restore will fail to recreate the objects with the original ownership and/or permissions.
Either way, you will have an only partially restored database. Alternatively, you can specify that the whole dump should be restored as a single transaction, so the restore is either fully completed or fully rolled back. This mode can be specified by passing the -1 or --single-transaction command-line options to psql. When using this mode, be aware that even the smallest of errors can rollback a restore that has already run for many hours. However, that might still be preferable to manually cleaning up a complex database after a partially restored dump.
Recovery of DB
- hosts: database_prim[0]
tasks:
- name: Get client database settings
shell: "awx-manage print_settings | grep '^DATABASES'"
register: results
changed_when: False
delegate_to: "{{ groups['client'][0] }}"
- name: Ingest client database settings
set_fact:
tower_db_settings: "{{ results.stdout | regex_replace('DATABASES\\s+= ', '') }}"
delegate_to: "{{ groups['client'][0] }}"
# Create User
- name: PostgreSQL | Create test user if its not there
postgresql_user:
name: "test"
password: "{{ client_db_settings.default.PASSWORD }}"
port: "5432"
state: present
login_user: "postgres"
no_password_changes: no
become: yes
become_user: "postgres"
become_method: su
# Create Database
- name: PostgreSQL | Create test Database if its not there
postgresql_db:
name: "test"
owner: "test"
encoding: "UTF-8"
lc_collate: "en_US.UTF-8"
lc_ctype: "en_US.UTF-8"
port: "5432"
template: "template0"
state: present
login_user: "postgres"
become: yes
become_user: "postgres"
become_method: su
- include_role:
name: pgrecover---
- name: Create a directory for non-instance specific backups
file:
path: '{{ backup_dir.rstrip("/") }}/restore/'
mode: 0775
owner: root
state: directory
- name: Copy file for restore
copy:
src: '{{ backup_dir.rstrip("/") }}/common/client.db'
dest: '{{ backup_dir.rstrip("/") }}/restore/'
remote_src: yes
- name: Perform a PostgreSQL restore
shell: "psql --host='{{ client_db_settings.default.HOST }}' --port={{ client_db_settings.default.PORT }} --username='{{ client_db_settings.default.USER }}' --dbname='test' < ./client.db"
args:
chdir: '{{ backup_dir.rstrip("/") }}/restore/'
environment:
PGPASSWORD: "{{ client_db_settings.default.PASSWORD }}"Using pg_dumpall
pg_dump dumps only a single database at a time, and it does not dump information about roles or tablespaces (because those are cluster-wide rather than per-database). To support convenient dumping of the entire contents of a database cluster, the pg_dumpall program is provided. pg_dumpall backs up each database in a given cluster, and also preserves cluster-wide data such as role and tablespace definitions. The basic usage of this command is:
pg_dumpall > outfile
The resulting dump can be restored with psql: psql -f infile Postgres.
(Actually, you can specify any existing database name to start from, but if you are reloading into an empty cluster, then Postgres should usually be used.) It is always necessary to have database superuser access when restoring a pg_dumpall dump, as that is required to restore the role and tablespace information. If you use tablespaces, be careful that the tablespace paths in the dump are appropriate for the new installation.
pg_dumpall works by emitting commands to re-create roles, tablespaces, and empty databases and then invoking pg_dump for each database. This means that while each database will be internally consistent, the snapshots of different databases might not be exactly in-sync.
By implementing minor changes in the automation script, you can change it to pg_dumpall.
Opinions expressed by DZone contributors are their own.
Comments