How We Predict Dataflow Job Duration Using ML and Observability Data
How Real-Time Observability Signals and Cloud-Native ML Models Improve Runtime Forecasting, Capacity Planning, and Operational Efficiency in Dataflow Pipelines
Join the DZone community and get the full member experience.
Join For FreeEfficiently managing large-scale data pipelines requires not only monitoring job performance but also anticipating how long jobs will run before they begin. This paper presents a practical, telemetry-driven approach for predicting the execution time of Google Cloud Dataflow jobs using machine learning. By combining Apache Airflow for workflow coordination, OpenTelemetry for collecting traces and resource metrics, and BigQuery ML for scalable model training, we develop an end-to-end system capable of generating reliable runtime estimates.
The solution continuously ingests real-time observability data, performs feature engineering, updates predictive models, and surfaces insights that support capacity planning, scheduling, and early anomaly detection. Experimental results across multiple regression techniques show that observability-rich signals significantly improve prediction accuracy. This work demonstrates how integrating modern observability frameworks with machine learning can help teams reduce costs, avoid operational bottlenecks, and operate cloud-based data processing systems more efficiently.
Introduction
Predicting how long a Dataflow job will run is more than a convenience — it plays a major role in planning resources, controlling costs, and meeting service level agreements (SLAs). In large data platforms where hundreds of jobs run daily, even small miscalculations can affect downstream systems, particularly in environments where latency spikes and tail behavior can have outsized effects on performance. This paper presents a practical, engineering-focused approach to estimating Google Cloud Dataflow job durations using telemetry data collected through OpenTelemetry.
The system integrates Apache Airflow for workflow management, OpenTelemetry for distributed traces and performance metrics, and BigQuery ML for model training and inference. By combining detailed runtime traces, resource usage patterns, and job-specific characteristics, we train models that can estimate the expected duration of a Dataflow job before it starts.
The pipeline continuously ingests new telemetry data, generates features, retrains models as workloads evolve, and produces predictions that can be used for scheduling, capacity planning, proactive optimization, and early anomaly detection. The architecture demonstrates how observability data and machine-learning techniques can be woven together in a real production environment without introducing unnecessary operational overhead.
Through experiments with several regression techniques, we found that the observability-driven models deliver accurate predictions. This provides teams with a practical tool for preventing unexpected delays and improving the efficiency of large-scale data operations implemented on Google Cloud Dataflow.
Methodology
Our approach combines observability data with machine learning to predict Dataflow job durations. The methodology consists of three key steps:
Data Collection and Preprocessing
Telemetry spans from OpenTelemetry traces are captured and flattened using BigQuery’s UNNEST function. This ensures that features like start time, end time, and resource attributes are accessible for modeling.
Feature Engineering
Feature engineering transforms raw telemetry into meaningful predictors:
- Duration: Difference between
end_timeandstart_time. - Job complexity indicators: Number of tasks, pipeline depth, and parallelism level.
- Resource metrics: CPU utilization, memory footprint, and I/O latency.
- Temporal features: Day of week, hour of execution, and historical averages.
Model Training Pipeline
- Data extraction and flattening using BigQuery
- Feature selection and cleaning
- Train–test split (typically 80/20)
- Model training using BigQuery ML regression
- Prediction and evaluation
BigQuery ML: How It Works
BigQuery ML allows users to create and train machine-learning models directly in BigQuery using SQL syntax. It supports regression, classification, clustering, and time-series forecasting. For this use case, a linear regression model predicts job duration based on engineered features. Training and prediction occur within BigQuery, eliminating data movement and leveraging Google’s distributed infrastructure.
Advantages
- No need for external ML infrastructure
- Scales seamlessly with large datasets
- Simple SQL-based interface
Limitations
- Limited algorithm choices compared to dedicated ML frameworks
- Feature engineering must be done in SQL, which can be complex for advanced transformations
- Hyperparameter-tuning options are basic
Airflow and OpenTelemetry
Apache Airflow is an orchestration platform to programmatically author, schedule, and execute workflows. OpenTelemetry is used to generate, collect, and export telemetry data (metrics, logs, and traces) to help analyze software performance and behavior. OpenTelemetry traces provide insight into how the pipeline is executed in real time and how the various modules interact.
Monitoring Airflow Logs and Metrics
Monitoring Apache Airflow involves collecting:
- Logs: Scheduler logs, worker logs, and DAG execution logs.
- Metrics: Task execution times, DAG-run durations, queue latencies, and resource utilization.
To achieve this, Airflow is configured to send logs and metrics to an OpenTelemetry (OTel) collector, which can then be inserted into BigQuery through a Dataflow job.
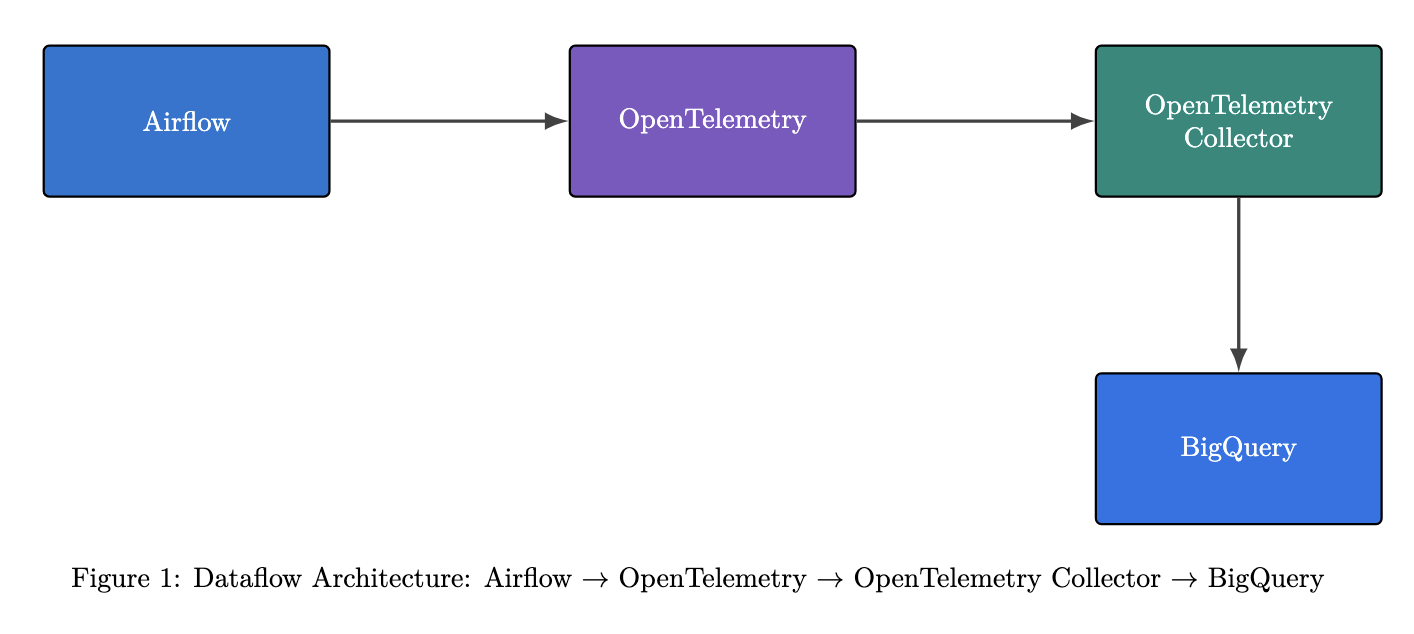
OpenTelemetry (OTel) Collector
The OpenTelemetry Collector offers a vendor-agnostic implementation for receiving, processing, and exporting telemetry data. The collector gathers all Airflow metrics into a central location so the data can be sent to Pub/Sub and then stored in BigQuery using Dataflow.
Configure airflow.cfg for OpenTelemetry (OTel)
Edit the airflow.cfg file to enable OpenTelemetry for Airflow metrics:
[metrics]
otel_on = True
otel_host = localhost
otel_port = 4318Restart Airflow services after making these changes:
airflow db migrate
airflow scheduler -D
airflow webserver -DCreating a Model on BigQuery Dataset
Since OTel spans contain a nested structure, it is important to UNNEST the data to perform operations in BigQuery. For a better model, build on a selective dataset relevant to predictions.
Sample OTel Span for Dataflow Metrics
{
"name": "checkout.process_payment",
"context": {
"trace_id": "5b8aa5a2d2c872e8321cf37308d69df2",
"span_id": "a90b4d2c872e8321"
},
"parent_id": "051581bf3cb55c13",
"kind": "CLIENT",
"start_time": "2025-10-24T15:45:00.123456789Z",
"end_time": "2025-10-24T15:45:00.345678901Z",
"status": {
"code": "STATUS_CODE_OK",
"message": ""
},
"attributes": {
"http.method": "POST",
"http.url": "https://payment-gateway.com/charge",
"payment.method": "Credit Card",
"order.id": "ORDER-12345"
},
"events": [
{
"name": "payment_request_sent",
"timestamp": "2025-10-24T15:45:00.150000000Z",
"attributes": {}
},
{
"name": "payment_gateway_response",
"timestamp": "2025-10-24T15:45:00.300000000Z",
"attributes": {
"http.status_code": 200,
"payment.success": true
}
}
]
}Model Creation: Target as Duration
The target field for the model is the duration, calculated as the difference between end_time and start_time.
BigQuery ML Model Creation
CREATE OR REPLACE MODEL
‘your_project.your_dataset.purchase_predictor_model‘
OPTIONS (...) AS
SELECT
-- feature selection and preprocessing here
FROM
your_project.your_dataset.your_table;Using the Model for Predictions
SELECT *
FROM ML.PREDICT(
MODEL ‘project_id.dataset.model_name‘,
< Select the new data rows you want to predict on. >
);Select and Preprocess Features
Select and preprocess the features used in the model. In this scenario, we are building a prediction model for estimating durations of Dataflow jobs, so we construct the field that contains the total duration of existing Dataflow jobs.
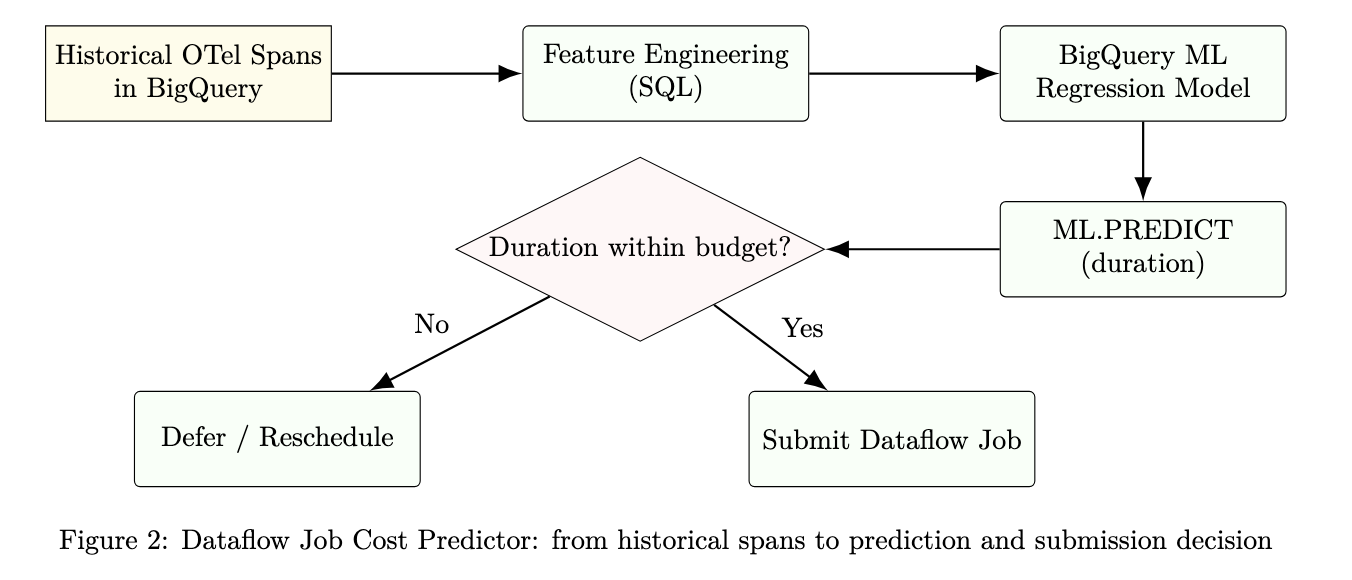
Dataflow Job Cost Predictor Diagram
The figure below visualizes how historical telemetry informs a BigQuery ML model that predicts runtime and guides the decision to submit or defer a Dataflow job.
Opinions expressed by DZone contributors are their own.
Comments