Prometheus at Scale – Part 1
As Prometheus rises in popularity, we discuss approaches for implementing high availability, scalability, and long-term storage using a real consumer scenario.
Join the DZone community and get the full member experience.
Join For Free
Prometheus has gained a lot of popularity because of its cloud-native approach for monitoring systems, and people are now giving native support to it while developing software and applications such as Kubernetes, Envoy, etc. For other applications, there are already exporters (agents) available to monitor it.
In this blog, I am going to discuss a scenario that was a very good learning experience for me. One thing I love about working with a service-based organization is that it keeps you on your toes, so you have to learn constantly. The same is the case with the current organization I am associated with.
Recently I got an opportunity to work on a project in which the client requested for a Prometheus HA solution to be implemented. Here is a brief overview of the request:
- They had a 100+ node Kubernetes cluster and they wanted to keep the data for a longer period. Moreover, the storage on the node was a blocker for them.
- In the case of Prometheus failure, they didn’t have a backup plan ready.
- They needed the scaling solution for Prometheus, as well.
Our Solution
We started with our research for the best possible scenarios. For the HA part, we thought we could implement the federated Prometheus concept, and for long-term storage, we thought of implementing the Thanos project. But while doing the research, we came across another interesting project called Cortex.
So, we did our comparison between Thanos and Cortex. Here are some interesting highlights:
| Cortex | Thanos |
| Recent data stored in injectors | Recent data stored in Prometheus |
| Use Prometheus write API to write data at a remote location | Use sidecar approach to write data at a remote location |
| Supports long-term storage | Supports long-term storage |
| HA is supported | HA is not supported |
| Single setup can be integrated with multiple Prometheus | Single setup can be associated with single Prometheus |
After this metrics comparison, we decided to go with the Cortex solution as it was able to fulfill the above-mentioned requirements of the client.
But the Cortex solutions are not free of complications. There are some complications of the Cortex project as well:
- As the architecture is a bit complex, it requires an in-depth understanding of Prometheus as TSDB..
- These projects require a decent amount of computing power in terms of memory and CPU
- It can increase your remote storage costs like S3, GCS, Azure storage, etc.
Since all these complications were not blockers for us, we moved ahead with the Cortex approach and implemented it in the project. It worked fine right from day one.
But in terms of scaling, we have to scale Prometheus vertically because it is not designed to scale horizontally.
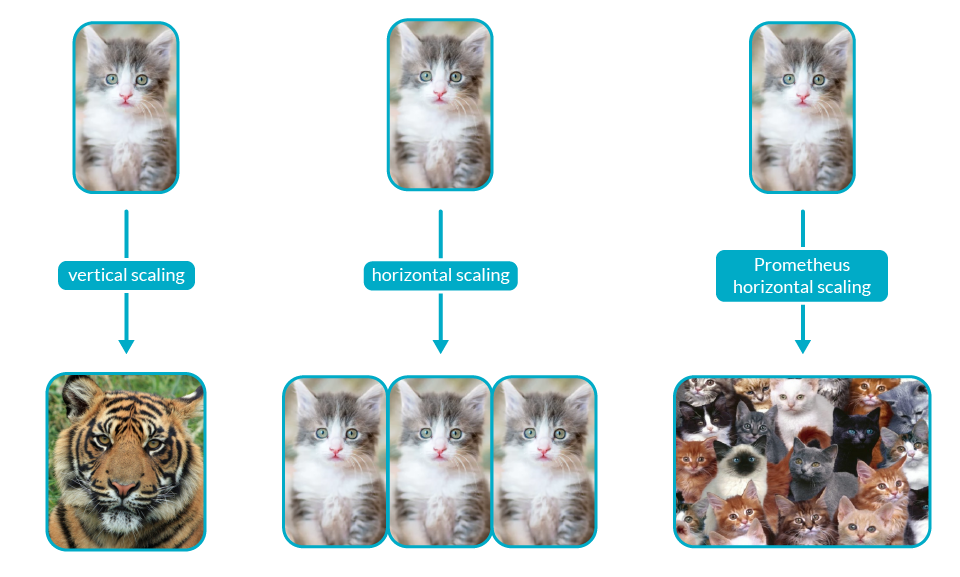
If we try to scale Prometheus horizontally, we will end up with scattered data that cannot be consolidated easily. Thus in terms of the scaling part, we would suggest you go with a vertical approach.
To automate the vertical scaling of Prometheus in Kubernetes, we have used VPA (Vertical Pod Autoscaler). It can both down-scale pods that are over-requesting resources and also up-scale pods that are under-requesting resources based on their usage over time.
Conclusion
In this blog, we discussed approaches for implementing the high availability, scalability, and long-term storage in Prometheus. In the next part of the blog, we will see how we actually set up these things in our environment.
If you guys have any other ideas or suggestions around the approach, please comment in the comment section. Thanks for reading, I’d really appreciate your suggestions and feedback.
Published at DZone with permission of Abhishek Dubey. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments