AI RAG Architectures: Comprehensive Definitions and Real-World Examples
Learn the three production-proven Modern RAG architectures Basic, Agentic, and Multi-Agent RAG and how to choose the right one based on cost, complexity, and scale.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) are highly capable, but they are not reliable on their own in the enterprise world. Language models tend to hallucinate, and they are not only deprived of new or proprietary information inputs but are also inefficient in areas such as governance, traceability, and expenditure management. Retrieval-Augmented Generation (RAG) came to the fore as an effective approach to anchor model responses to external knowledge sources. There is a tendency among various teams to consider RAG as a single pattern of implementation.
Something I quickly discovered is that RAG is not one architecture, but several. Indeed, a system that is adequate for a simple “search assistance” scenario is not sufficient for scenarios involving multi-step reasoning, tool execution, or multiple data sources. It is important to treat different RAG architectures differently in order to avoid fragile or overly engineered systems that are difficult to run in production environments.
Several patterns have evolved over time. Some applications require fast and accurate retrieval only. Others require planning, reasoning, and acting software agents. Beyond small-scale applications, these software agents often require parallel processing across specialized roles. These use cases have very different requirements for RAG architectures.
In this article, I will walk you through the three most frequent RAG architectures found in real-world scenarios: Basic RAG, Agentic RAG, and Multi-Agent RAG. I will provide an overview of what each does, its use cases, and the trade-offs involved.
This is not about adding complexity, but about guiding you to use the least complicated architecture that can effectively solve your scenario.
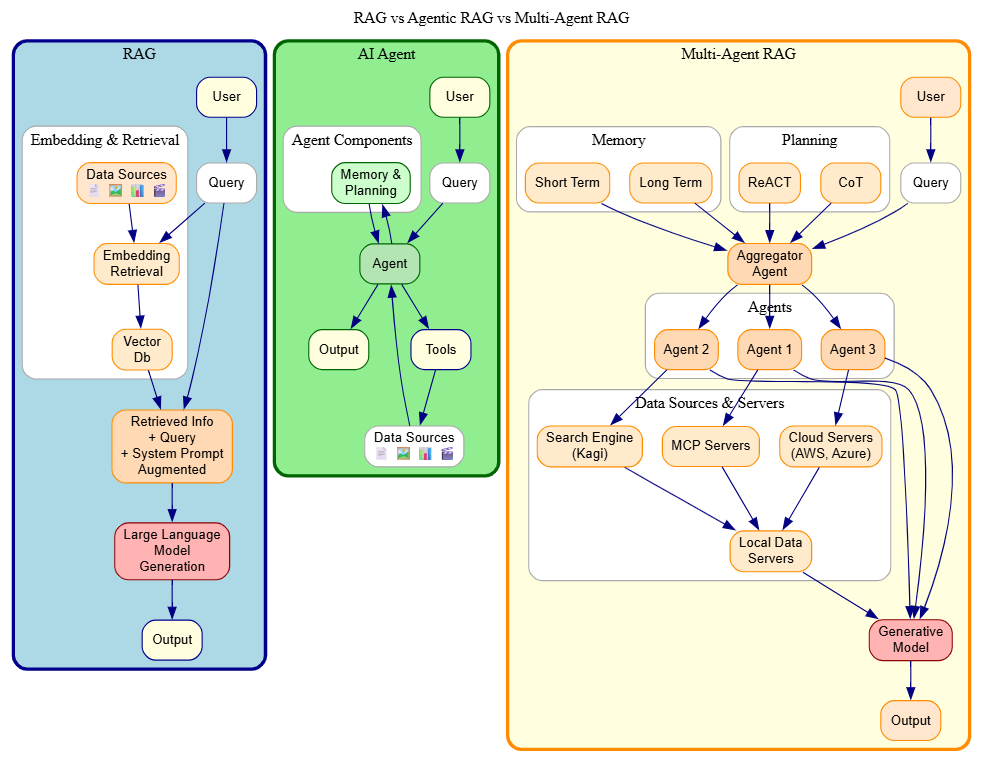
1. Basic RAG (Retrieval-Augmented Generation)
Definition
Basic RAG allows AI responses to be improved using a lookup mechanism via an external knowledge source. This enables the AI model to provide more accurate responses by relying not only on the data it acquired during training.
How It Works
Basic RAG works in two clear steps:
- Retrieval step: Documents are represented as numerical vectors (embeddings) and stored in a vector database. When a question is asked, the system searches for the most relevant documents at a semantic level, not just by keyword matching.
- Generation step: The model uses the retrieved documents and the original question to generate a relevant and understandable response.
Key Characteristics
- Fixed flow: The system always follows the same process — retrieve first, then answer.
- Single knowledge source: Typically relies on one database or document set.
- No deep reasoning: Information is retrieved and directly used to derive an answer.
- Low cost and simple setup: Easy to implement and requires minimal code.
Real-World Example: HR Policy Chatbot
Case study: An employee asks their company’s AI chatbot, “How much annual leave do I have?”
How it works:
- The system converts the question into a vector embedding
- Searches HR policy documents and employee records
- Retrieves the relevant leave policy and the employee’s leave balance
- Enhances the LLM prompt by incorporating retrieved data
- The LLM responds: “Based on our HR records, you have 15 days of annual leave left for the year.”
When to use: Internal knowledge bases, FAQ systems, document Q&A, simple customer support
2. Agentic RAG
Definition
Agentic RAG refers to the use of AI agents to facilitate the retrieval-augmented generation process. These architectures incorporate agents to improve adaptability and accuracy, enabling large language models to actively perform information retrieval and decision-making.
Key Architectural Differences
In a fully agentic system, the model is self-directed in how it approaches problem resolution. Rather than following a fixed script, the system determines which steps to take based on information quality and task requirements.
Core Components
- Memory systems: Short-term and long-term memory for context storage
- Planning capabilities: Multi-step reasoning enabled by frameworks such as ReACT and Chain-of-Thought
- Tool integration: Access to APIs, calculators, web search, and external services such as databases or Confluence
- Iterative refinement: The agent may validate outcomes and re-query when necessary
Real-World Example: Customer Support Agent
Scenario: A customer reports, “My order hasn’t arrived, and I need it by Friday for a party.”
Agentic process:
- Retrieves order details from a shipping API
- Checks current tracking status
- Evaluates whether the delivery deadline is achievable
- If delayed, autonomously decides whether to offer expedited shipping or a refund
- Accesses customer history to determine eligibility
- Takes action without human intervention
What makes it agentic:
The agent does not merely retrieve information. It reasons about the data, makes decisions, and takes autonomous action based on outcomes.
Real-World Example: Legal Document Analysis
In legal advisory services, simple retrieval is insufficient. The agent must evaluate the relevance and implications of retrieved information through iterative reasoning loops.
Scenario: A lawyer needs to review contracts for compliance violations.
Agentic RAG approach:
- Pulls relevant regulations from legal databases
- Extracts key clauses from submitted contracts
- Cross-references precedent cases
- Identifies potential violations autonomously
- Suggests remediation steps
- Queries related cases for justification if needed
3. Multi-Agent RAG
Definition
Multi-Agent RAG employs a network of specialized agents to carry out tasks with greater precision, efficiency, and contextual relevance. Each agent is typically assigned a specific role, such as retrieval, filtering, analysis, or generation.
Architectural Model
Information retrieval by specialized agents is coordinated by a master (or orchestrator) agent. For example, some agents may retrieve proprietary internal data, others may access personal data such as email or chat, while others focus on public web searches.
Key Benefits
Multi-Agent RAG mitigates the limitations of single-agent systems in relevance, scalability, and latency by decomposing RAG into separable subtasks that can be executed concurrently.
Parallel Processing Advantage
Parallel execution across multiple agents significantly accelerates retrieval and generation.
Real-World Example: Research Paper Analysis System
Scenario: “What are the latest AI safety innovations, their patent coverage, and real-world deployments?”
Multi-agent architecture:
- Query Understanding Agent: Breaks complex questions into manageable sub-queries
- Academic Retriever Agent: Searches peer-reviewed journals and academic databases
- Patent Retriever Agent: Scans patent databases
- Web Search Agent: Collects recent news and industry reports
- Analysis Agent: Evaluates findings across sources
- Orchestrator Agent: Manages workflow and data flow
Process:
- The query is decomposed into innovation, patent coverage, and deployment aspects
- Retrieval agents operate in parallel
- The analysis agent compares academic, patent, and commercial data
- The orchestrator synthesizes results into a unified response with source references
Time Comparison
A single-agent system takes about 30 seconds to complete the task, while using multiple agents working in parallel reduces the time to around 8 seconds.
Healthcare Diagnosis Support
An Agentic RAG system can continuously analyze new medical research in real time. When a doctor enters a patient’s symptoms, the system finds the most recent studies, offers possible diagnoses, and suggests treatment options. It may also ask follow-up questions to clarify uncertainties.
Multi-Agent Team:
- Patient Data Agent: Retrieves patient history, lab results, and current medications
- Medical Literature Agent: Searches for the latest clinical studies and treatment guidelines
- Diagnostic Tool Agent: Accesses specialized medical databases and decision-making tools
- Drug Interaction Agent: Checks for conflicts with the patient’s current medications
- Clinical Expert Synthesizer: Combines all information to provide diagnostic recommendations
Advantage: Each agent focuses on its area of expertise, reducing errors and increasing accuracy through distributed knowledge.
E-commerce Product Recommendation
Multi-agent RAG systems help e-commerce platforms offer personalized shopping experiences by pulling product information, customer reviews, and recommendations that match individual preferences.
Agent Specialization:
- User Preference Agent: Analyzes the user’s browsing history and past purchases
- Product Catalog Agent: Retrieves product inventory and technical specifications
- Review Agent: Compiles customer feedback and ratings
- Price Optimization Agent: Compares prices and availability across competitors
- Recommendation Synthesizer: Creates customized product suggestions for each user
Architecture Comparison
| Feature | Basic RAG | Agentic RAG | Multi-Agent RAG |
|---|---|---|---|
| Data Sources | Single | Multiple | Multiple |
| Decision Making | None | Autonomous | Coordinated |
| Iteration | None | Yes (self-correcting) | Yes (across agents) |
| Latency | Low | Medium | Very Low (parallel) |
| Complexity | Simple | Medium | High |
| Scalability | Limited | Good | Excellent |
| Use Case Fit | FAQs, simple Q&A | Complex workflows | Enterprise systems |
Tools and Frameworks by Architecture
Basic RAG Tools & Frameworks
Vector Database Platforms:
- Pinecone: Managed vector database with built-in infrastructure
- Weaviate: Open-source vector database with a GraphQL API
- Milvus: Scalable open-source vector database
- Qdrant: Vector database optimized for similarity search
- Chroma: Lightweight embedding database for development
RAG Orchestration:
- LangChain: Python framework providing RAG pipeline components, document loaders, and embedding integrations
- LlamaIndex: Document indexing framework designed specifically for RAG applications
- Haystack: End-to-end NLP framework with RAG capabilities
Embedding Models:
- OpenAI’s text-embedding-3-small/large
- Sentence-Transformers (open source)
- Cohere Embed API
- Hugging Face embedding models
Use cases: Legal document QA systems, internal knowledge bases, customer FAQ chatbots
Agentic RAG Tools and Frameworks
Agent Frameworks:
- LangChain Agents: ReACT pattern implementation with tool binding
- Letta (formerly MemGPT): Focused on agent memory management and context windows
- AutoGPT: Autonomous task planning and execution
- Hugging Face Agents: Integrates transformers with tool access
Reasoning & Planning:
- DSPy: Framework for optimizing LLM prompts and weights (supports ReACT and Chain-of-Thought)
- Semantic Kernel: Microsoft SDK for integrating LLMs with conventional programming
- Anthropic’s Extended Thinking: Native support for multi-step reasoning
Tool Integration:
- Toolformer approach: LLM learns when and how to use tools
- Function-calling APIs: OpenAI, Anthropic, Google
- IFTTT and Zapier integrations for workflow automation
Memory Management:
- Vector-based semantic memory
- Episodic memory stores (conversation history)
- Procedural memory (learned skills and patterns)
Use cases: Customer support automation, financial analysis workflows, legal contract analysis
Deployment Platforms:
- Modal: Serverless compute for agent execution
- Hugging Face Spaces: Rapid agent deployment
- AWS Lambda with SageMaker
Multi-Agent RAG Tools and Frameworks
Multi-Agent Orchestration:
- CrewAI: Framework for multi-agent collaboration with role-based agent design
- Swarm (OpenAI): Lightweight orchestration framework for multi-agent workflows
- Microsoft AutoGen: Framework for building autonomous agent groups using LLM conversations
- Anthropic’s Models API: Native multi-turn conversation support for coordinated agents
Agent Communication:
- Message queuing: RabbitMQ, Apache Kafka
- Event streaming: Apache Kafka, AWS Kinesis
- Direct API calls using request/response patterns
Specialized Agent Libraries:
- Financial agents: FinGPT, FinQL
- Medical agents: Med-PaLM integration frameworks
- Legal agents: LexisNexis API integrations
- Research agents: Semantic Scholar API, arXiv API
Data Integration and Connectors:
- Apache Airflow: Orchestrates data pipelines feeding multiple agents
- dbt: Data transformation for agent knowledge bases
- Model Context Protocol (MCP): Standardized interface for agent-tool interaction
- Custom REST APIs connecting to enterprise systems
Monitoring and Coordination:
- LangSmith: LLM monitoring and debugging
- Arize: ML observability for agent performance
- Datadog: Infrastructure monitoring for distributed agents
- Custom dashboards tracking agent states and decisions
Deployment Infrastructure:
- Kubernetes: Orchestrates multiple agent containers
- Docker Compose: Local multi-agent development
- AWS ECS: Managed container orchestration
- Google Cloud Run: Serverless multi-agent deployment
Use cases: Healthcare diagnostic systems, financial portfolio analysis, legal document review at scale, research synthesis platforms
Limitations by Architecture
Basic RAG Limitations
- Static knowledge: Cannot adapt to data changes without reindexing
- No contextual reasoning: Cannot infer beyond retrieved documents
- Single retrieval pass: Cannot refine queries based on initial results
- Scalability constraints: Performance degrades with extremely large document collections
- Limited fallback: Cannot suggest alternatives when relevant data is missing
- Quality dependency: Output depends heavily on embedding quality and data organization
- No tool integration: Cannot interact with external APIs or services
- Semantic drift: Struggles with multi-domain or highly specialized queries
Agentic RAG Limitations
- Inference cost and latency: Iterative reasoning increases token usage and response time
- Hallucination risk: Agents may generate false outputs when tool results are ambiguous
- Tool dependency: Performance degrades if tools are unreliable or unavailable
- Control and predictability: Non-deterministic behavior complicates compliance requirements
- Debugging complexity: Difficult to trace multi-step reasoning paths
- Resource intensive: Higher infrastructure and compute costs than basic RAG
- Limited coordination: Single agents cannot efficiently parallelize tasks
- State management: Long contexts can exceed token limits
Multi-Agent RAG Limitations
- Architectural complexity: Requires sophisticated orchestration and distributed systems management
- Operational overhead: Increased monitoring, logging, and maintenance demands
- Eventual consistency: Agents may operate on stale data and consensus mechanisms can be expensive and slow
- Failure cascades: Failure of one agent can compromise the entire system
- Coordination overhead: Inter-agent communication can become a bottleneck
- Cost: Significantly more expensive than basic RAG due to multiple model calls, infrastructure, and operational complexity
- Latency unpredictability: Parallelism adds variability in execution time
- Governance complexity: Auditability and accountability are harder to maintain
- Agent misalignment: Conflicting objectives can reduce overall system quality
- Skill degradation: Over-specialization reduces flexibility for novel tasks
Recommendations
| Scenario | Recommended | Rationale |
|---|---|---|
| Customer FAQ over static KB | Basic RAG | Simple, cost-effective, low latency |
| Insurance claim analysis | Agentic RAG | Requires reasoning over documents + tool access to databases |
| E-commerce product recommendation | Multi-Agent RAG | Parallel data retrieval (catalog, reviews, pricing, inventory) |
| Medical diagnosis support | Multi-Agent RAG | Parallel specialist agents (literature, diagnostics, drug interactions) |
| Legal document compliance check | Agentic RAG | Self-correcting analysis with iterative cross-referencing |
| Internal wiki search | Basic RAG | Static documentation, simple retrieval sufficient |
| Financial portfolio analysis | Multi-Agent RAG | Multiple data sources (market data, news, historical patterns) require parallelization |
| Chatbot with web search | Agentic RAG | Dynamic tool integration with iterative search refinement |
Implementation Frameworks and Tools
Various agent frameworks, including DSPy, LangChain, CrewAI, LlamaIndex, and Letta, have been developed to support the creation of applications using language models. Among these, CrewAI stands out as a prominent framework for building multi-agent systems. Additionally, Swarm is a framework created by OpenAI that focuses on the orchestration of multiple agents.
Production Use Cases
Agentic RAG applications include real-time question-answering through RAG-powered chatbots, automated support for handling simpler customer inquiries with escalation to humans for complex requests, and data management to help employees find information within proprietary data stores.
Takeaways
- Basic RAG answers factual questions using external data
- Agentic RAG adds autonomous reasoning and tool usage
- Multi-Agent RAG coordinates specialized agents for enterprise-scale performance
- Architecture choice depends on complexity, data diversity, and latency needs
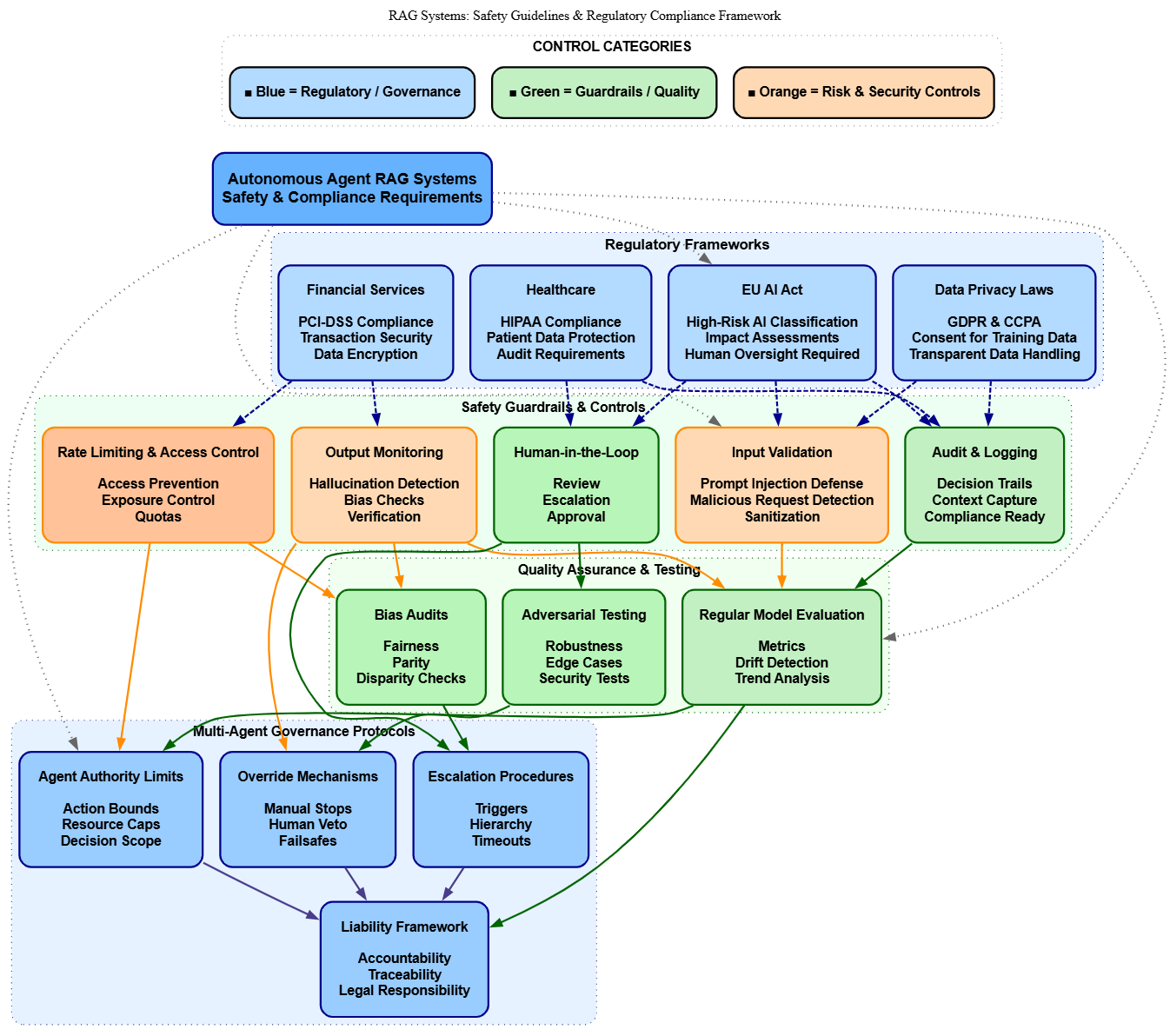
Safety Guidelines and Regulatory Compliance
Conclusion
RAG architectures have transformed enterprise AI. Basic RAG remains optimal for simple, cost-efficient retrieval over single data sources. Agentic RAG bridges the gap between basic systems and enterprise complexity by introducing autonomous reasoning and tool integration. Multi-Agent RAG achieves unprecedented scalability and reduced latency through parallel, specialized agents, enabling mission-critical applications in healthcare, finance, and research.
Rather than adopting a single solution, organizations should deploy the architecture best suited to each specific problem.
Opinions expressed by DZone contributors are their own.
Comments