Knowledge Graphs and RAG: A Guide to AI Knowledge Retrieval
Enter knowledge graphs, the secret weapon for superior RAG applications. This guide has everything you need to begin leveraging RAG for intelligent AI knowledge retrieval.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-Augmented Generation (RAG) has emerged as a powerful paradigm, blending the strengths of information retrieval and natural language generation. By leveraging large datasets to retrieve relevant information and generate coherent and contextually appropriate responses, RAG systems have the potential to revolutionize applications ranging from customer support to content creation.
Fundamentals of AI Agents Using RAG and LangChain | Enroll in Free Course*
*Affiliate link. See Terms of Use.
How Does RAG Work?
Let us look at how RAG works. In a traditional setup, you will have a user prompt which is sent to the Large Language Model (LLM), and the LLM provides a completion:
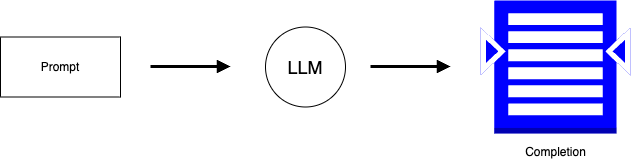
But the problem with this setup is that the LLM’s knowledge has a cutoff date, and it does not have insights into business-specific data.
Importance of RAG for Accurate Information Retrieval
RAG helps alleviate all the drawbacks that are listed above by allowing the LLM to access the knowledge base. Since the LLM now has context, the completions are more accurate and can now include business-specific data. The below diagram illustrates the value add RAG provides to content retrieval:
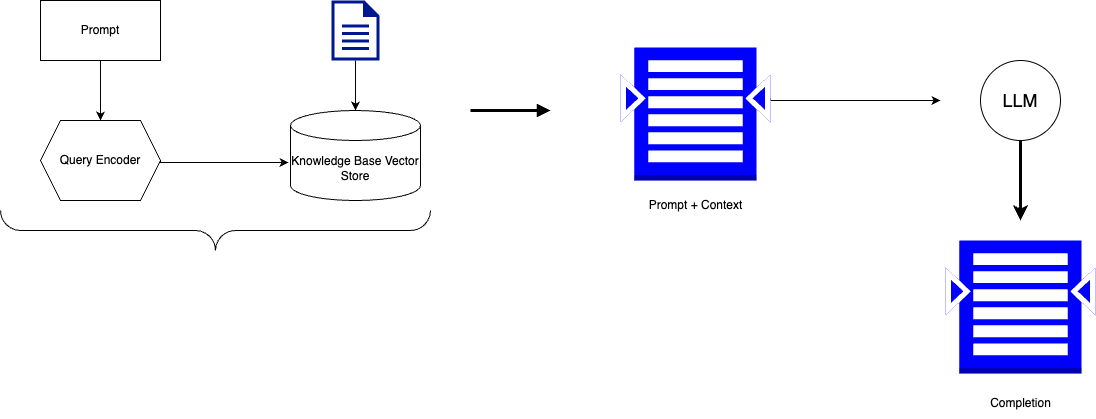
As you can see, by vectorizing business-specific data, which the LLM would not have access to, instead of just sending the prompt to the LLM for retrieval, you send the prompt and context and enable the LLM to provide more effective completions.
Challenges With RAG
However, as powerful as RAG systems are, they face challenges, particularly in maintaining contextual accuracy and efficiently managing vast amounts of data.
Other Challenges include:
- RAG systems will often find it very difficult to articulate complex relationships between information if it is distributed across a lot of documents.
- RAG solutions are very limited in their reasoning capabilities on the retrieved data.
- RAG solutions often tend to hallucinate when they are not able to retrieve desired information.
Knowledge Graphs to the Rescue
Knowledge graphs are sophisticated data structures that represent information in a graph format, where entities are nodes and relationships are edges. This structure plays a crucial role in overcoming the challenges faced by RAG systems, as it allows for a highly interconnected and semantically rich representation of data, enabling more effective organization and retrieval of information.
Benefits of Using Knowledge Graphs for RAG
Below are some key advantages for leveraging knowledge graphs:
- Knowledge graphs help RAG grasp complex information by providing rich context with the interconnected representation of information.
- With the help of knowledge graphs, RAG solutions can improve their reasoning capabilities when they traverse relationships in a better way.
By linking information retrieved to specific aspects of the graph, knowledge graphs help increase factual accuracy.
Impact of Knowledge Graphs on RAG
Knowledge graphs fundamentally enhance RAG systems by providing a robust framework for understanding and navigating complex data relationships. They enable the AI not just to retrieve information based on keywords, but to also understand the context and interconnections between different pieces of information. This leads to more accurate, relevant, and contextually aware responses, significantly improving the performance of RAG applications.
Now let us look at the importance of knowledge graphs in enhancing RAG application through a coding example. To showcase the importance, we will take the example of retrieving a player recommendation for an NFL Fantasy Football draft. We will ask the same question to the RAG application with and without knowledge graphs implemented, and we will see the improvement in the output.
RAG Without Knowledge Graphs
Let us look at the following code where we implement a RAG solution in its basic level for retrieving a football player of our choosing, which will be provided via a prompt. You can clearly see the output does not retrieve the accurate player based on our prompt.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Sample player descriptions
players = [
"Patrick Mahomes is a quarterback for the Kansas City Chiefs, known for his strong arm and playmaking ability.",
"Derrick Henry is a running back for the Tennessee Titans, famous for his power running and consistency.",
"Davante Adams is a wide receiver for the Las Vegas Raiders, recognized for his excellent route running and catching ability.",
"Tom Brady is a veteran quarterback known for his leadership and game management.",
"Alvin Kamara is a running back for the New Orleans Saints, known for his agility and pass-catching ability."
]
# Vectorize player descriptions
vectorizer = TfidfVectorizer()
player_vectors = vectorizer.fit_transform(players)
# Function to retrieve the most relevant player
def retrieve_player(query, player_vectors, players):
query_vector = vectorizer.transform([query])
similarities = cosine_similarity(query_vector, player_vectors).flatten()
most_similar_player_index = np.argmax(similarities)
return players[most_similar_player_index]
# Function to generate a recommendation
def generate_recommendation(query, retrieved_player):
response = f"Query: {query}\n\nRecommended Player: {retrieved_player}\n\nRecommendation: Based on the query, the recommended player is a good fit for your team."
return response
# Example query
query = "I need a versatile player."
retrieved_player = retrieve_player(query, player_vectors, players)
response = generate_recommendation(query, retrieved_player)
print(response)We have oversimplified the RAG case for ease of understanding. Below is what the above code does:
- Imports necessary libraries:
TfidfVectorizerfromsklearn,cosine_similarityfromsklearn, andnumpy - Defines sample player descriptions with details about their positions and notable skills
- Player descriptions are vectorized using TF-IDF to convert the text into numerical vectors for precise similarity comparison.
- Defines a function
retrieve_playerto find the most relevant player based on a query by calculating cosine similarity between the query vector and player vectors - Defines a function
generate_recommendationto create a recommendation message incorporating the query and the retrieved player's description
Provides an example query, "I need a versatile player.", which retrieves the most relevant player, generates a recommendation, and prints the recommendation message.
Now let's look at the output:
python ragwithoutknowledgegraph.py
Query: I need a versatile player.
Recommended Player: Patrick Mahomes is a quarterback for the Kansas City Chiefs, known for his strong arm and playmaking ability.
Recommendation: Based on the query, the recommended player is a good fit for your team.As you can see, when we were asked for a versatile player, the recommendation was Patrick Mahomes.
RAG With Knowledge Graphs
Now let us look at how knowledge graphs can help enhance RAG and give a better recommendation. As you see from the output below, the correct player is recommended based on the prompt.
import rdflib
from rdflib import Graph, Literal, RDF, URIRef, Namespace
# Initialize the graph
g = Graph()
ex = Namespace("http://example.org/")
# Define players as subjects
patrick_mahomes = URIRef(ex.PatrickMahomes)
derrick_henry = URIRef(ex.DerrickHenry)
davante_adams = URIRef(ex.DavanteAdams)
tom_brady = URIRef(ex.TomBrady)
alvin_kamara = URIRef(ex.AlvinKamara)
# Add player attributes to the graph
g.add((patrick_mahomes, RDF.type, ex.Player))
g.add((patrick_mahomes, ex.team, Literal("Kansas City Chiefs")))
g.add((patrick_mahomes, ex.position, Literal("Quarterback")))
g.add((patrick_mahomes, ex.skills, Literal("strong arm, playmaking")))
g.add((derrick_henry, RDF.type, ex.Player))
g.add((derrick_henry, ex.team, Literal("Tennessee Titans")))
g.add((derrick_henry, ex.position, Literal("Running Back")))
g.add((derrick_henry, ex.skills, Literal("power running, consistency")))
g.add((davante_adams, RDF.type, ex.Player))
g.add((davante_adams, ex.team, Literal("Las Vegas Raiders")))
g.add((davante_adams, ex.position, Literal("Wide Receiver")))
g.add((davante_adams, ex.skills, Literal("route running, catching ability")))
g.add((tom_brady, RDF.type, ex.Player))
g.add((tom_brady, ex.team, Literal("Retired")))
g.add((tom_brady, ex.position, Literal("Quarterback")))
g.add((tom_brady, ex.skills, Literal("leadership, game management")))
g.add((alvin_kamara, RDF.type, ex.Player))
g.add((alvin_kamara, ex.team, Literal("New Orleans Saints")))
g.add((alvin_kamara, ex.position, Literal("Running Back")))
g.add((alvin_kamara, ex.skills, Literal("versatility, agility, pass-catching")))
# Function to retrieve the most relevant player using the knowledge graph
def retrieve_player_kg(query, graph):
# Define synonyms for key skills
synonyms = {
"versatile": ["versatile", "versatility"],
"agility": ["agility"],
"pass-catching": ["pass-catching"],
"strong arm": ["strong arm"],
"playmaking": ["playmaking"],
"leadership": ["leadership"],
"game management": ["game management"]
}
# Extract key terms from the query and match with synonyms
key_terms = []
for term, syns in synonyms.items():
if any(syn in query.lower() for syn in syns):
key_terms.extend(syns)
filters = " || ".join([f"contains(lcase(str(?skills)), '{term}')" for term in key_terms])
query_string = f"""
PREFIX ex: <http://example.org/>
SELECT ?player ?team ?skills WHERE {{
?player ex:skills ?skills .
?player ex:team ?team .
FILTER ({filters})
}}
"""
qres = graph.query(query_string)
best_match = None
best_score = -1
for row in qres:
skill_set = row.skills.lower().split(', ')
score = sum(term in skill_set for term in key_terms)
if score > best_score:
best_score = score
best_match = row
if best_match:
return f"Player: {best_match.player.split('/')[-1]}, Team: {best_match.team}, Skills: {best_match.skills}"
return "No relevant player found."
# Function to generate a recommendation
def generate_recommendation_kg(query, retrieved_player):
response = f"Query: {query}\n\nRecommended Player: {retrieved_player}\n\nRecommendation: Based on the query, the recommended player is a good fit for your team."
return response
# Example query
query = "I need a versatile player."
retrieved_player = retrieve_player_kg(query, g)
response = generate_recommendation_kg(query, retrieved_player)
print(response)Let us look at what the above code does. The code:
- Imports necessary libraries: rdflib, Graph, Literal, RDF, URIRef, and Namespace
- Initializes an RDF graph and a custom namespace ex for defining URIs
- Defines players as subjects using URIs within the custom namespace
- Adds player attributes (team, position, skills) to the graph using triples
- Defines a function
retrieve_player_kgto find the most relevant player based on a query by matching key terms with skills in the knowledge graph - Uses SPARQL to query the graph, applying filters based on synonyms of key skills extracted from the query
- Evaluates query results to find the best match based on the number of matching skills
- Defines a function
generate_recommendation_kgto create a recommendation message incorporating the query and the retrieved player's information - Provides an example query
"I need a versatile player.", retrieves the most relevant player, generates a recommendation, and prints the recommendation message
Now let us look at the output:
python ragwithknowledgegraph.py
Query: I need a versatile player.
Recommended Player: Player: AlvinKamara, Team: New Orleans Saints, Skills: versatility, agility, pass-catching
Recommendation: Based on the query, the recommended player is a good fit for your team.Conclusion: Leveraging RAG for Enhanced Knowledge Graphs
Incorporating knowledge graphs into RAG applications results in more accurate, relevant, and context-aware recommendations, showcasing their importance in improving AI capabilities.
Here are a few key takeaways:
ragwithoutknowledgegraph.pyuses TF-IDF and cosine similarity for text-based retrieval, relying on keyword matching for player recommendations.ragwithknowledgegraph.pyleverages a knowledge graph, using RDF data structure and SPARQL queries to match player attributes more contextually and semantically.- Knowledge graphs significantly enhance retrieval accuracy by adeptly understanding the intricate relationships and context between data entities.
- They support more complex and flexible queries, improving the quality of recommendations.
- Knowledge graphs provide a structured and interconnected data representation, leading to better insights.
- The illustration demonstrates the limitations of traditional text-based retrieval methods.
- It highlights the superior performance and relevance of using knowledge graphs in RAG applications.
- The integration of knowledge graphs significantly enhances AI-driven recommendation systems.
Additional Resources
Below are some of the resources that help with learning knowledge graphs and their impact on RAG solutions.
Courses to Learn More About RAG and Knowledge Graphs
- https://learn.deeplearning.ai/courses/knowledge-graphs-rag/lesson/1/introduction
- https://ieeexplore.ieee.org/document/10698122
Open-Source Tools and Applications
Opinions expressed by DZone contributors are their own.
Comments