Exploring Reactive and Proactive Observability in the Modern Monitoring Landscape
Embracing the shift in landscape from traditional monitoring systems to automated anomaly detection, pattern recognition, and root cause analysis.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
The modern digital world, with its complex web of microservices, containerized apps, and cloud-native systems, demands a rethinking of how we monitor and observe these environments. From the traditional monitoring systems, there is an evident shift to two main approaches that have emerged: Reactive and Proactive observability.
What is Reactive and Proactive Observability?
Organizations rely on metrics, logs, and traces to retroactively identify the underlying causes of issues, similar to treating an infection. Reactive observability is a conventional approach that examines system behavior after an incident has occurred. This reactive method requires organizations to have the necessary tools and expertise, which helps them detect symptoms and connect them to a solution that resolves the problem.
How many of those on-call engineers are paged in the middle of the night and have to sift painfully through a bunch of code to figure out the actual issue? Proactive monitoring is about taking preventive measures to maintain overall well-being. This reduces the likelihood of problems arising in the first place. To implement this proactive strategy, teams continuously monitor and employ predictive analytics to identify potential risks. This proactive approach addresses the majority of risks even before they have a chance to occur, promoting a healthier system overall and minimizing the impact of potential incidents.
Emerging Trends in Monitoring Strategies
Modern monitoring strategies are increasingly incorporating proactive observability methodologies, which delve into solutions that require predictive analysis, anomaly detection, and automated remediation. This preemptively addresses potential problems before they manifest into disruptive incidents that cause significant downtime. The rise of artificial intelligence and machine learning is significantly impacting monitoring, enabling the creation of self-learning systems that can identify patterns, predict future anomalies, and automatically optimize system performance.
Benefits of Proactive Observability
The integration of proactive observability methodologies transcends the constraints inherent in traditional reactive strategies. This helps improve system reliability, optimize performance, and enhance overall operational efficiency. Proactive observability anticipates and prevents incidents, uncovering the “unknown” unknowns, thereby minimizing downtime and associated financial losses. This enhances the end-user experience by preventing service disruptions.
Drivers for Proactive Observability
Several factors drive the adoption of proactive observability, including the growing complexity of modern IT environments, the demand for continuous uptime and optimal performance, and the increasing availability of advanced analytics and automation tools.
- Artificial intelligence and machine learning technologies analyze large amounts of data, while identifying patterns, and providing insights to human operators. These advancements enable:
- Anomaly Detection: Identify unusual patterns real-time, such as sudden spikes in CPU usage or unexpected network traffic.
- Root Cause Analysis (RCA): Identify underlying reasons for anomalies, reducing time and effort required compared to traditional methods.
- Forecasting: Predict system behavior based on historical trends, allowing teams to take preventive actions before issues arise. For instance, an AI-powered observability tool might detect when infrastructure systems are running low on resources. For example, low on memory, and recommend mitigation strategies. If appropriate SLAs are in place, the system can even take automated action without waiting for manual intervention.
- AIOps: These platforms integrate AI and ML with IT operations. This helps streamline monitoring, alerting, and resolving issues. These platforms can:
- Reduce unnecessary alerts by filtering out false positives.
- Combine data from multiple sources to provide a deeper understanding of system health.
- Utilize automated workflows to address common problems without the need for human intervention.
- Adoption of cloud-native technologies, such as Kubernetes and microservices has increased the complexity of IT environments. Proactive observability tools are designed to handle this complexity by:
- Providing granular visibility into containerized applications.
- Implementing dynamic monitoring that adapts as services scale up or down.
- Offering contextual insights into dependencies between microservices.
Case Studies on Proactive Monitoring
There are numerous real-world examples that demonstrate how organizations have successfully implemented proactive observability to enhance system reliability, minimize downtime, and optimize performance. Let’s dive deeper into a case study with an e-commerce platform.
An e-commerce company running traditionally takes a proactive approach by implementing an AIOps-powered observability solution to improve its website reliability during peak shopping seasons. These solutions leverage predictive analytics to forecast traffic spikes and automatically scale resources in advance. As a result, downtimes are significantly reduced. This results in significantly improved customer satisfaction scores during high-demand periods, keeping shoppers happy and loyal.
Here’s a graph that highlights how customer happiness improves over time when predictive analytics in observability is adopted.
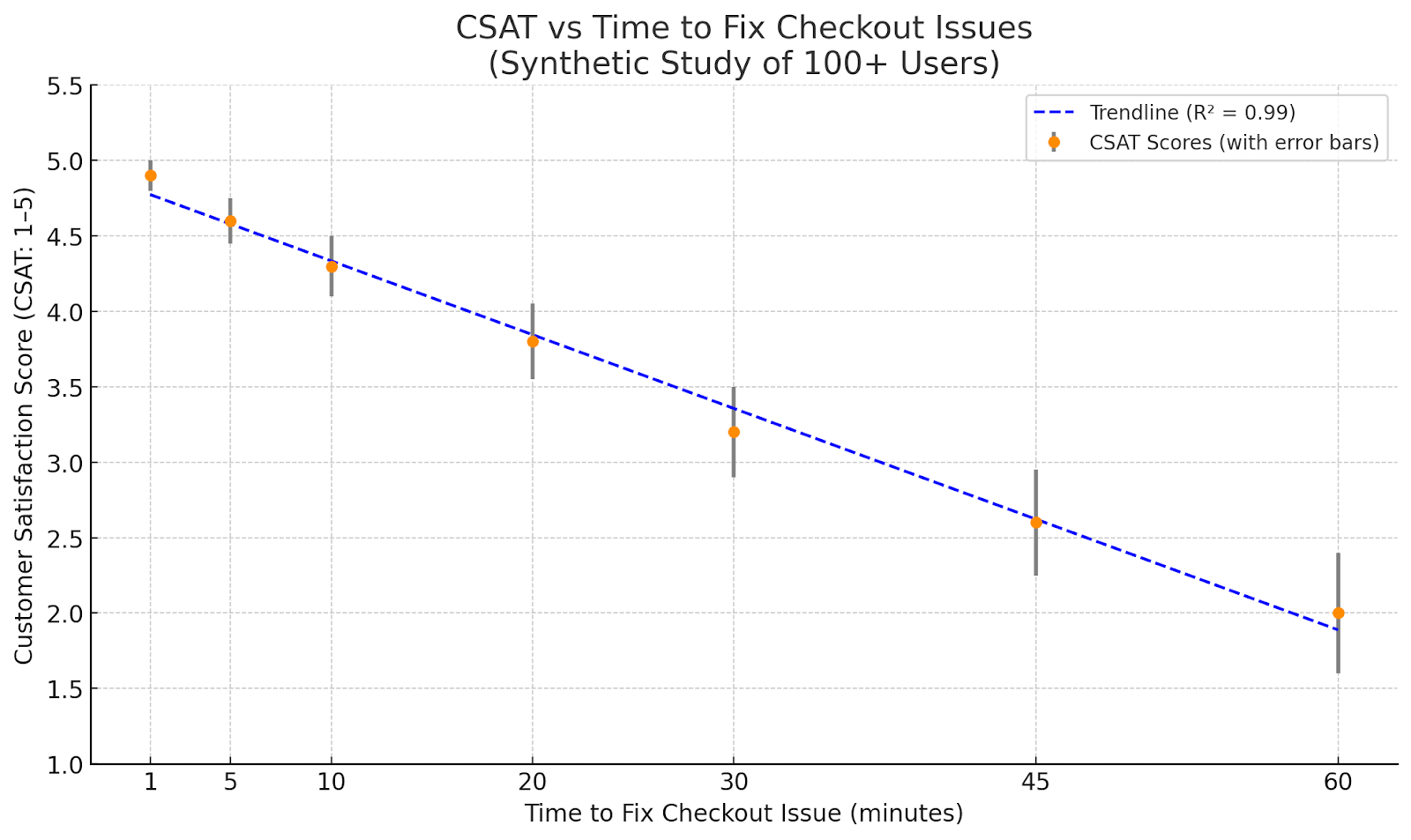
- Error bars indicate variability in CSAT scores, increasing in size as fix times rise, reflecting more inconsistent customer experiences.
- The trendline (dashed blue) indicates a negative correlation between fixed time and CSAT, with a strong fit (R² shown in the legend).
Note: This is a synthetic study where I analyzed data from 100+ users, bucketizing the time it took for resolving an issue during e-commerce checkout to see how it directly impacted their experience.
Challenges and Limitations
While proactive observability offers promising advantages, organizations must navigate the inherent challenges and limitations associated with implementing these strategies. For instance, analyzing large sets of data can be a challenge and is often a complex undertaking. The teams should look out for false positives. It is also important to understand the initial investment in tooling and expertise, as these can be substantial. It is critical for organizations to carefully evaluate the ROI to justify the expenditure and invest in these areas.
Conclusion
There is a predominant shift from traditional monitoring to proactive observability. They are not mutually exclusive, but complementary approaches that can work together to ensure the reliability, performance, and security of modern IT systems. Proactive observability aims to detect and prevent problems before they arise.
By leveraging the strengths of this strategy, organizations can adopt a holistic observability framework that empowers them to better understand their IT environments, identify potential risks, and take preemptive actions. This helps maintain optimal system performance and minimize disruptive incidents. This plays a significant role where teams are empowered to be proactive problem-solvers rather than reactive firefighters.
Opinions expressed by DZone contributors are their own.
Comments