Designing a Real-Time Data Activation Platform Using Segment CDP, Databricks, and Iterable
We rebuilt a failing activation stack as a governed platform using Segment, Databricks, and Iterable, reducing incidents and enabling safer self-service.
Join the DZone community and get the full member experience.
Join For FreeThe first sign our activation stack was failing wasn’t latency or scale. It was when two internal teams triggered conflicting workflows from the same event, and neither system could explain why.
That moment made something clear: once multiple teams depend on the same signals, activation stops being a marketing workflow problem and becomes a software architecture problem.
We evolved a real-time data activation platform over several years using Segment and Iterable, with Databricks acting as the governance and control layer. Today, the platform processes hundreds of millions of events and enforces compliance upstream, allowing non-engineering teams to operate safely without risking data quality or privacy.
This article walks through the architectural decisions, trade-offs, and operational lessons that only surfaced once the system was under real production pressure.
Why Activation Broke at Scale
As soon as multiple teams began relying on shared customer signals, our batch pipelines became a bottleneck for anything time-sensitive. Different groups triggered workflows across separate systems, but those systems were fragmented underneath.
Event ingestion, identity resolution, compliance enforcement, and activation logic were spread across tools with limited observability and inconsistent guarantees.
From an engineering perspective, the problems compounded quickly:
- Inconsistent event schemas across product signals
- Tight coupling between product code and downstream tools
- Compliance checks applied late in the workflow
- High operational load on engineers for routine changes
Engineers spent more time explaining why something triggered than fixing actual bugs.
At that point, activation stopped behaving like an application feature and started behaving like a platform.
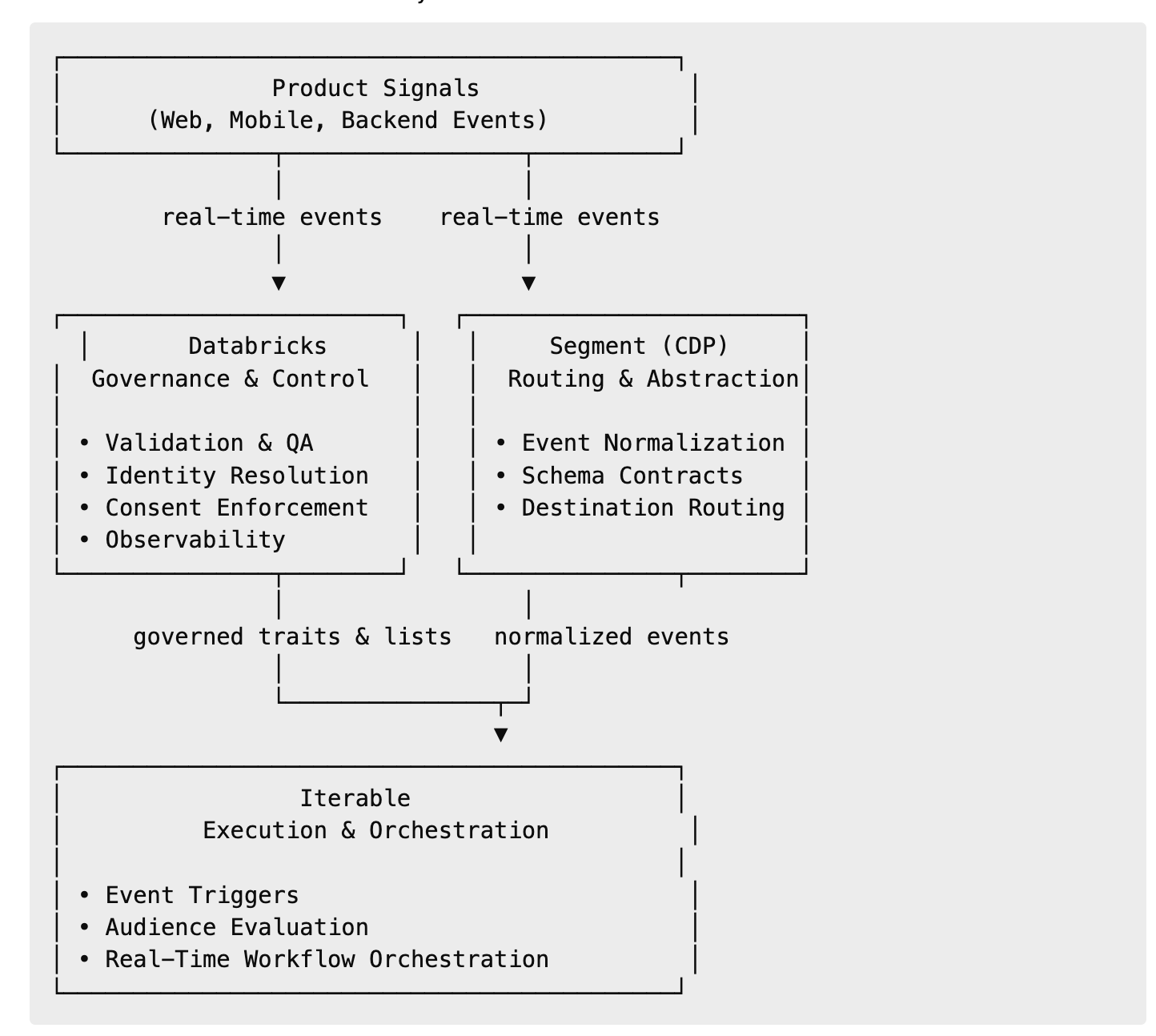
Architectural Overview: Explicit Layers
The platform follows a layered, event-driven design. Each layer owns a single concern, even when that separation makes the system harder to reason about end-to-end.
Ingestion and Contract Layer (Segment)
Defines event schemas, enforces contracts, and routes signals safely.
Governance and Control Layer (Databricks)
Applies data quality checks, identity resolution, consent enforcement, and observability.
Execution Layer (Iterable)
Evaluates audiences and triggers workflows using only validated data.
Operational Feedback Layer
Monitors failures, detects drift, and supports incident response.
Segment and Databricks operate in parallel rather than as a linear pipeline. Product signals fan out to both systems simultaneously. Iterable consumes validated inputs from both paths, keeping execution fast without embedding governance logic directly into workflows.
What “Real-Time” Means in Practice
“Real-time” did not mean sub-second guarantees everywhere.
Operationally:
- Events reached Segment within seconds
- Governance checks completed within a few seconds to a minute
- Iterable workflows triggered immediately after validation
Latency was acceptable in governance paths, but not in execution paths. Backpressure and retries were handled upstream. If data failed validation or arrived too late, it was quarantined rather than allowed to block execution or trigger incorrect messaging.
Segment: Event Contracts at the Boundary
Segment serves as the contract boundary between product instrumentation and downstream systems.
That decision came after breaking things more than once.
Early on, we formalized event schemas and ownership models. Instrumentation stopped being “best effort” and started behaving like an API.
Key practices included:
- Strongly typed event definitions
- Versioned schemas with backward compatibility
- Explicit ownership per event and attribute
- Environment-based routing for isolation
A simplified event contract looked like this:
{
"event_name": "user_profile_updated",
"version": "v2",
"properties": {
"user_id": { "type": "string" },
"consent_status": { "type": "boolean" },
"updated_at": { "type": "timestamp" }
},
"required": ["user_id", "updated_at"]
}Breaking schema changes were blocked in CI and at ingestion time. Treating schemas as contracts reduced downstream breakage and made changes auditable. In practice, this felt much closer to API governance than analytics tracking.
Databricks: Governance and Control Plane
Databricks was positioned as the control plane for data readiness, not just analytics.
Every event or trait intended for activation passed through validation and enrichment before reaching execution systems. Identity validation turned out to be the hardest piece to stabilize. Many early incidents were traced back to identity issues, even when symptoms appeared elsewhere.
Databricks enforced:
- Freshness and completeness checks
- Consent and suppression rules
- Anomaly detection on event volume and distribution
We also monitored aggregate behavior. Sudden spikes or drops in event volume triggered alerts. Distribution drift on key fields flagged undocumented schema changes.
These checks caught failures early, often before they reached execution. Incident response became faster, and teams trusted the platform enough to operate without constant engineering oversight.
Iterable: Execution Without Tight Coupling
Iterable serves as the execution layer, triggering workflows seconds after validated signals arrive.
It only consumes data that has already passed governance checks. As a result, workflow failures almost always pointed upstream, not into Iterable itself.
An execution input contract looked like:
{
"audience_id": "high_value_users",
"validated_at": "2025-09-18T10:12:00Z",
"consent_checked": true
}Iterable remained focused on orchestration, not data correctness. In production, this setup supported tens of millions of executions per month without requiring constant engineering intervention.
Failure Modes and Safeguards
The platform was designed for failure, not just correctness.
- Schema drift – Detected at ingestion and blocked before routing.
- Identity mismatches – Quarantined during governance checks and surfaced via alerts.
- Consent violations – Execution halted immediately, not deferred.
- Event spikes or lag – Detected via thresholds; non-critical signals throttled or dropped.
Each failure mode had a defined owner and response path, reducing ambiguity during incidents.
Compliance as Architecture
Compliance could not be bolted on after the fact.
Privacy, consent, and suppression rules were enforced directly within the data pipeline. This produced consistent behavior across regions and simplified onboarding for new use cases.
More importantly, it prevented retroactive fixes when regulations changed. Enforcement logic lived in one place, not scattered across dozens of workflows.
Trade-Offs and Lessons Learned
This architecture came with real costs:
- Schema changes required review and versioning
- New signals took days, not hours, to onboard
- Contracts and documentation needed continuous maintenance
It also meant saying “no” more often early on, which was unpopular until the incident volume dropped.
Over time, those costs paid for themselves by reducing firefighting and allowing downstream teams to move without pulling engineers into routine changes.
Practical Takeaways
For teams building similar systems:
- Treat event schemas like APIs.
- Enforce identity and consent upstream.
- Quarantine bad data instead of compensating downstream.
- Make failure modes explicit and owned.
- Accept slower onboarding in exchange for operational stability.
Conclusion
Once activation became critical to multiple teams, it started behaving like any other distributed backend system.
Contracts, observability, fault isolation, and governance mattered more than individual tools. Treating activation as an engineering problem allowed the platform to scale without dragging engineers into day-to-day operations.
If we had to rebuild the platform, we would start with identity contracts before choosing any tools. Every shortcut we took there came back during an incident, never during a roadmap discussion.
Opinions expressed by DZone contributors are their own.
Comments