Fast Data Access Part 2: From Manual Hacks to Modern Stacks
Rebuild a legacy risk pipeline with GemFire, Spark, and Spring Boot. Sub-2ms alerts, ACID upserts, real-time dashboards, and a one-command demo.
Join the DZone community and get the full member experience.
Join For FreeIt's been a while since I wrote Part 1 of this series. If you recall, back in 2019, we built a "Fast Data" pipeline using GemFire 9 and Spark 2.4.
Precap of Part 1: Do you remember the pain we went through?
- We had to manually build the
geode-spark-connectorfrom source code (gradlew clean build). - We were stuck editing
cache.xmlfiles by hand. - We were loading data into legacy Hive tables, which meant dealing with the "Small File Problem" and zero transaction support.
The 2026 Update: Life is way easier now. We don't build custom connectors anymore; we just pull official dependencies from Maven. GemFire 10.1 and Spark 4.1 have matured into a seamless stack.
How we rebuilt a legacy risk pipeline with VMware GemFire, Apache Spark, and Spring Boot-and how you can run it locally in under 5 minutes.
1. Real-World Use Cases
Picture a busy, high-speed stock trading floor. This computer setup acts as an ultra-fast safety net and a perfect record-keeper combined. First, if a trader suddenly bets too much money, the system catches it and sends an alert instantly, in milliseconds, instead of waiting for an end-of-day report when the damage is already done.
Second, it acts like an airplane’s black box for government regulators. If an auditor shows up and asks, "What exactly did your books look like at 10:42 AM last Tuesday?", the system can literally "rewind time" to show them perfectly accurate records. Behind the scenes, it neatly updates changing trade statuses without creating a messy pile of duplicate files, handles a massive firehose of incoming data, and does it all without the computer ever "freezing" or lagging to catch its breath. In short, it lets trading companies see exactly how much risk they are taking in real-time, while keeping their record books spotless for the government.
This architecture solves problems that trading desks, risk teams, and compliance officers face every day:
| Use Case | Business Need | How This Stack Delivers |
|---|---|---|
| Intraday Risk Limits | Know immediately when a desk exceeds $10M exposure. Breach at 10:42 AM must not wait for a 6 PM batch. | GemFire Continuous Queries fire in <2ms when a FILLED trade breaches threshold. Push, not poll. |
| Regulatory Audit Trail | SEC, MiFID II, Dodd-Frank require immutable history of every trade state change. "What was the position at 10:42?" | Iceberg ACID MERGE + Time Travel. Single source of truth, no duplicate rows. SELECT * FROM trade_history TIMESTAMP AS OF '2026-02-13 10:42:00'. |
| Trade Lifecycle (NEW -> FILLED) | A trade updates multiple times. Append-only Hive/Parquet gives 3 rows per trade. Compliance needs one row per trade, latest state. | Spark MERGE INTO with Iceberg. Upsert on tradeId; only the latest state is the "current" row. |
| Zero-Downtime Risk Engine | GC pauses during market hours = missed alerts, potential regulatory breach. | ZGC on GemFire; 500GB heaps with pauses <2ms. Spring Boot hot path stays responsive. |
| Multi-Desk Exposure | Aggregate exposure across DESK_A, DESK_B, etc. Real-time dashboards. | GemFire holds current state; CQ pushes to dashboard. Spark syncs to Iceberg for historical analytics. |
| FIX/gRPC Ingestion | Algo engines send trades via FIX or gRPC. Need sub-millisecond ingestion. | Spring Boot REST (demo) or gRPC; GemFire upsert. Production: same pattern with FIX adapter. |
2. Why Spring Boot, Spark, and GemFire?
Each technology is chosen for a specific job. Here's the justification:
Why Spring Boot?
| Reason | Detail |
|---|---|
| Rapid API Development | REST endpoints, validation (@Valid), Actuator health in minutes. No boilerplate. |
| Production-Ready | Health checks, metrics, graceful shutdown. Ops teams expect this. |
| GemFire Integration | spring-boot-starter-data-gemfire + BOM = version-aligned, no dependency hell. |
| Ecosystem | FIX adapters, gRPC, Kafka-all have Spring Boot starters. Swap REST for FIX in production. |
| Java 17 | Records, pattern matching. FinTech needs immutable domain models. |
Alternatives considered: Raw servlets or Quarkus. Spring Boot wins for GemFire BOM alignment and team familiarity.
Why Apache Spark?
| Reason | Detail |
|---|---|
| MERGE (Upsert) at Scale | Iceberg's MERGE INTO runs as a Spark job. Batch sync of millions of trades. |
| GemFire Connector | gemfire-spark-connector reads directly from /Trades region. No export step in production. |
| SQL-First | spark.sql("MERGE INTO ...") - analysts and compliance can read/write SQL. |
| S3/Cloud Native | Iceberg on s3a://; Spark handles cloud I/O. |
| Scheduled Jobs | Run sync every 5 min, hourly, or on-demand. Fits Airflow, Kubernetes CronJob. |
Alternatives considered: Flink for streaming. Spark wins for batch MERGE + Iceberg maturity + GemFire connector.
Why VMware GemFire (Geode)?
| Reason | Detail |
|---|---|
| Sub-Millisecond Reads | In-memory, partitioned. Trade lookup by tradeId in <1ms. |
| Continuous Queries (CQ) | OQL runs on the server. Alert fires only when a trade matches the predicate. No polling. |
| Horizontal Scale | Add servers; data partitions automatically. 500GB+ heaps per node. |
| ZGC Support | Pauses <2ms even at 500GB heap. Critical for latency-sensitive risk. |
| Spring Data | @Region, GemfireTemplate, @ContinuousQuery - first-class Spring integration. |
Alternatives considered: Redis, Hazelcast. GemFire wins for CQ (push-based alerts), Spring Data, and FinTech adoption.
3. Stack Versions and Download Links
| Component | Version | Purpose | Download / Maven |
|---|---|---|---|
| Java | 17 (LTS) | Runtime for Spring Boot & Spark | Adoptium, Oracle JDK 17 |
| Maven | 3.8+ | Build tool | Apache Maven |
| Spring Boot | 2.7.18 | Risk Engine (hot path) | spring-boot-starter-parent 2.7.18 |
| VMware GemFire | 10.1 | In-memory hot storage (production) | Tanzu GemFire 10.1, Broadcom Docs |
| GemFire BOM | 1.0.4 | Aligns Spring Boot 3.1 + GemFire 10.1 | com.vmware.gemfire:spring-boot-3.1-gemfire-10.1:1.0.4 (Broadcom repo) |
| Apache Spark | 3.5.3 | Cold path MERGE, Iceberg runtime | Spark 3.5.3, Maven Central |
| Apache Iceberg | 1.7.1 | ACID table format, MERGE support | iceberg-spark-runtime-3.5, Iceberg Docs |
| Scala | 2.13.12 | Spark/Scala API | Bundled with Spark; Scala 2.13 |
| winutils | hadoop-2.7.1 | Spark on Windows (Hadoop native) | steveloughran/winutils (hadoop-2.7.1/bin) |
| Git | 2.x | Clone repository | git-scm.com |
Note: VMware GemFire is the commercial product (Broadcom/Tanzu). Apache Geode is the open-source fork. This stack uses GemFire for production (CQ, BOM, support); Geode can be used for local dev with some config changes.
Version Compatibility Matrix
| Spring Boot | GemFire BOM | Java | Spark | Iceberg |
|---|---|---|---|---|
| 2.7.x | - | 17 | 3.5.x | 1.7.x |
| 3.1.x | spring-boot-3.1-gemfire-10.1:1.0.4 | 17 | 3.5.x | 1.7.x |
Quick Install Commands
Java 17 (Windows - Chocolatey):
choco install temurin17Maven (Windows - Chocolatey):
choco install maven
Maven (Linux - apt):
sudo apt install openjdk-17-jdk maven
4. The Problem: Part 1 Recap
It has been seven years since I wrote Part 1. Back then, we were building "fast data" pipelines with duct tape. We manually built connectors, fought with cache.xml, and prayed that garbage collection wouldn't freeze our trading platform during market hours.
| Pain | What Happened |
|---|---|
| Manual Dependency Hell | Run ./gradlew clean build on connector source just to get a JAR |
| Hive Fragility | Write to Hive tables; job fails -> partial files, zero transaction guarantees |
| GC Pauses | Heap past 32GB = death sentence for latency |
5. The 2026 Reality
I recently rebuilt that legacy stack for a financial risk engine. The requirements were strict:
- Hot path: Active exposure in milliseconds (GemFire)
- Cold path: Immutable, auditable history of every trade state change for regulators (Iceberg)
- Zero downtime: No GC pauses allowed
We built it with VMware GemFire 10.1, Apache Spark 3.5, and Spring Boot 3.
6. Pain Points We Solve
Teams building real-time risk engines hit the same walls. Here's what we addressed:
| Pain Point | Our Contribution |
|---|---|
| "I can't run Spark on Windows" | setup-winutils.ps1 - one-click Hadoop native binaries |
| "I need to see both UIs running" | run-demo.ps1 - visible windows, 90s Spark UI, auto-open dashboard |
| "Hive append = duplicate rows" | Iceberg MERGE INTO - upsert with ACID semantics |
| "Risk alerts are too slow" | Continuous Queries - <2ms push-based alerts |
| "No GemFire access for local dev" | In-memory hot path - same API, one config change for prod |
| "Java 17 + Spark = reflection errors" | MAVEN_OPTS in run scripts - --add-opens preconfigured |
| "No single E2E command" | run-e2e.bat / run-all.ps1 - one command, repeatable |
7. Architecture: The Intraday Loop
We don't just dump data. We implement a "Hot State, Cold History" loop.
- GemFire holds the current state of the Order Book
- Spark + Iceberg captures the audit trail (every state transition)
The diagrams below are presented in sequence: start with the high-level flow, then drill into components, then follow the hot-path and cold-path sequences, then see how GemFire/Geode and Spark are structured, and finally, how everything deploys in production.
7.1 High-Level Architecture (Data Flow)
This diagram shows the six-step data flow across the system. Trades enter via FIX or gRPC (step 1), get upserted into GemFire (step 3), trigger continuous queries for real-time alerts (step 4), and are synced to Iceberg via Spark for the audit trail (steps 5-6).
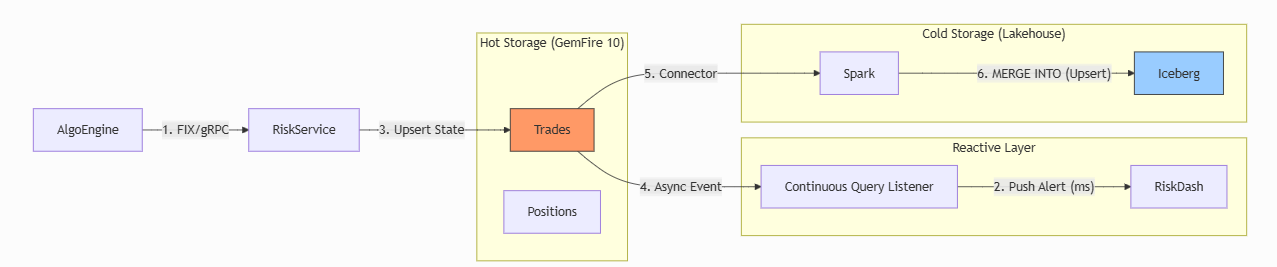
Figure 1: High-level data flow. Steps 1-6 show the path from trade ingestion to hot storage, real-time alerts, and cold audit trail.
7.2 Component Architecture (Layered View)
This layered view shows how each component fits together. The Ingestion Layer accepts trades from multiple protocols; the Application Layer (Spring Boot) orchestrates risk checks and exports; GemFire holds hot state; the Reactive Layer pushes alerts; and Spark syncs to Iceberg.
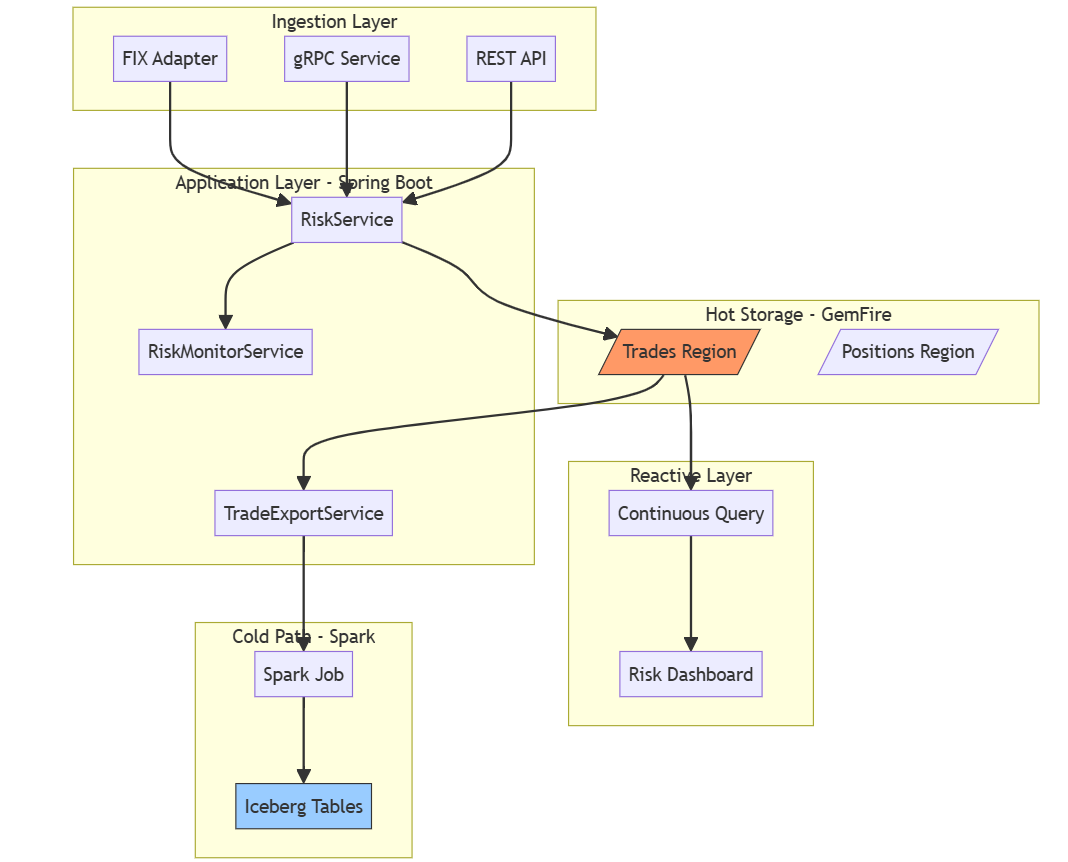 Figure 2: Component architecture. Five layers from ingestion to cold storage, with data flowing top to bottom.
Figure 2: Component architecture. Five layers from ingestion to cold storage, with data flowing top to bottom.
7.3 Sequence Diagram: Hot Path (Trade Ingestion to Risk Alert)
This sequence shows the millisecond-level flow when a trade breaches the $10M limit. The Algo Engine posts the trade; RiskService upserts to GemFire; the Continuous Query fires asynchronously when the trade matches the OQL predicate; the dashboard displays the CRITICAL alert in under 2ms.
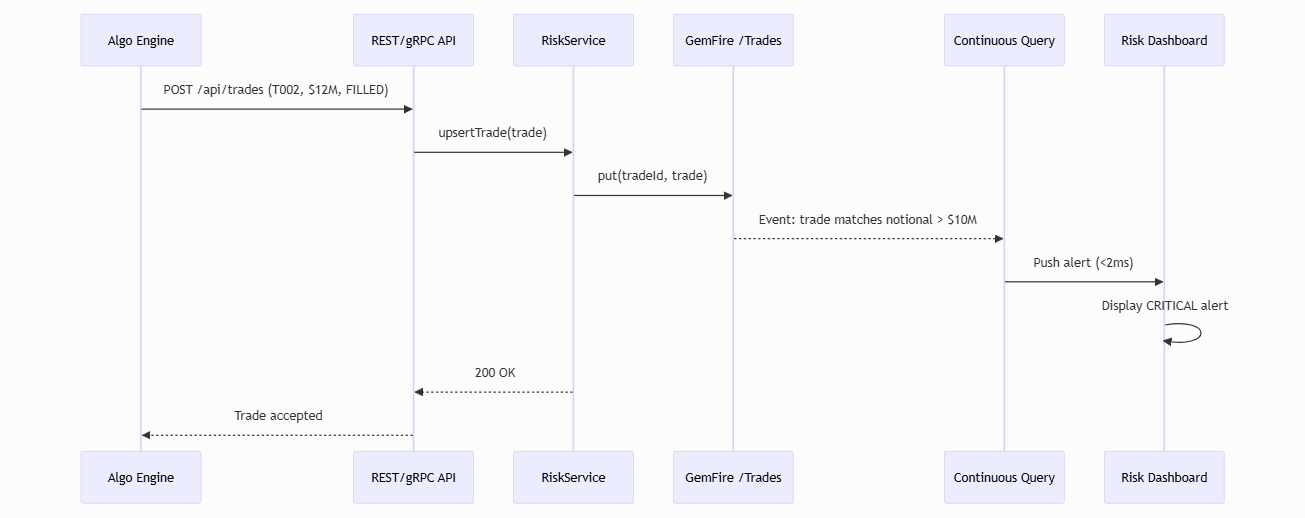
Figure 3: Hot-path sequence. From trade POST to CRITICAL alert in under 2ms. CQ runs on the GemFire server; only matching trades trigger network traffic.
7.4 Sequence Diagram: Cold Path (Spark Sync to Iceberg)
This sequence shows the batch sync that runs every 5 minutes (or on-demand). Spark reads from GemFire via the connector (or CSV in local demo), executes the MERGE INTO SQL, and commits to Iceberg with ACID guarantees. No duplicate rows; existing tradeIds are updated, new ones are inserted.
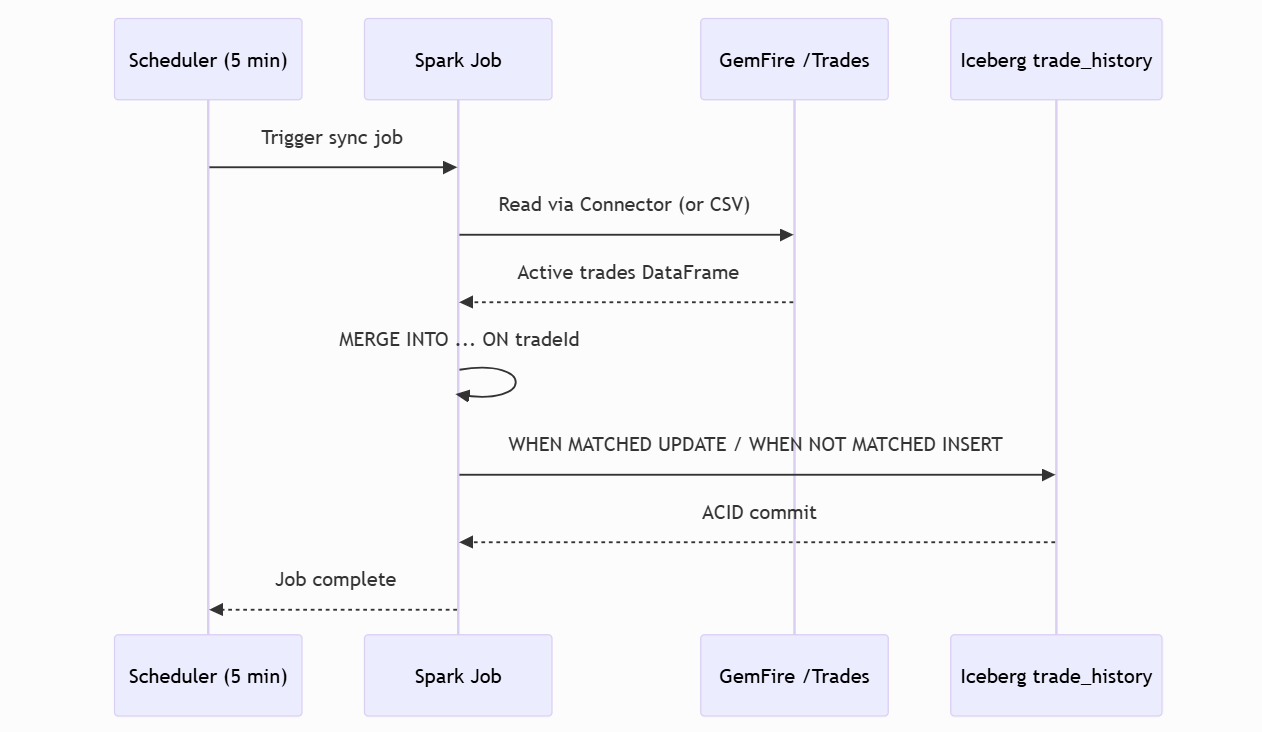
Figure 4: Cold-path sequence. Spark MERGE syncs hot state to Iceberg. ACID commit ensures no partial writes.
7.5 GemFire / Apache Geode Cluster Structure
GemFire (or Apache Geode) uses a locator for membership and a partitioned region for /Trades. Data is distributed across servers by tradeId hash. The locator routes client requests; servers hold the data and run Continuous Queries. Replication can be configured for high availability.
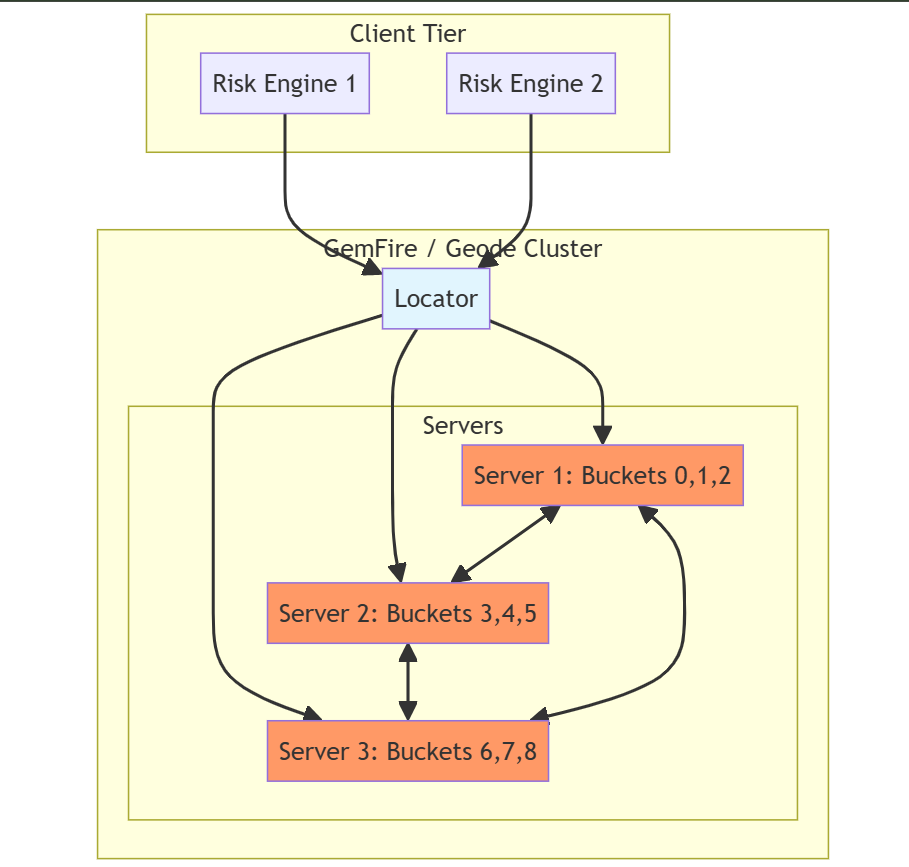
Figure 5: GemFire/Geode cluster. Locator manages membership; servers hold partitioned /Trades data. CQ runs on the server that owns the bucket.
7.6 Apache Spark Job Structure (MERGE INTO)
When Spark runs the MERGE INTO, it builds a DAG: read source (GemFire or CSV), create/load target Iceberg table, execute merge plan (scan, join, write). The job runs in stages; each stage has tasks that process partitions in parallel.
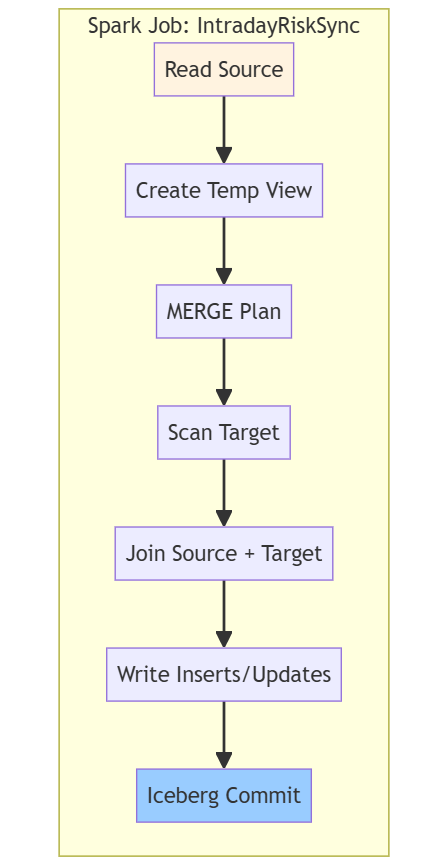
Figure 6: Spark job structure. DAG for MERGE INTO: read, join, write, commit. Iceberg commit is atomic.
7.7 Deployment Architecture (Production)
Production deployment spans four zones: Trading (algo engines), Risk Engine (Spring Boot), GemFire (in-memory cluster), and Spark/Data (batch jobs, S3 warehouse). Risk Engine instances connect to the GemFire locator; Spark reads from GemFire and writes to S3-backed Iceberg.
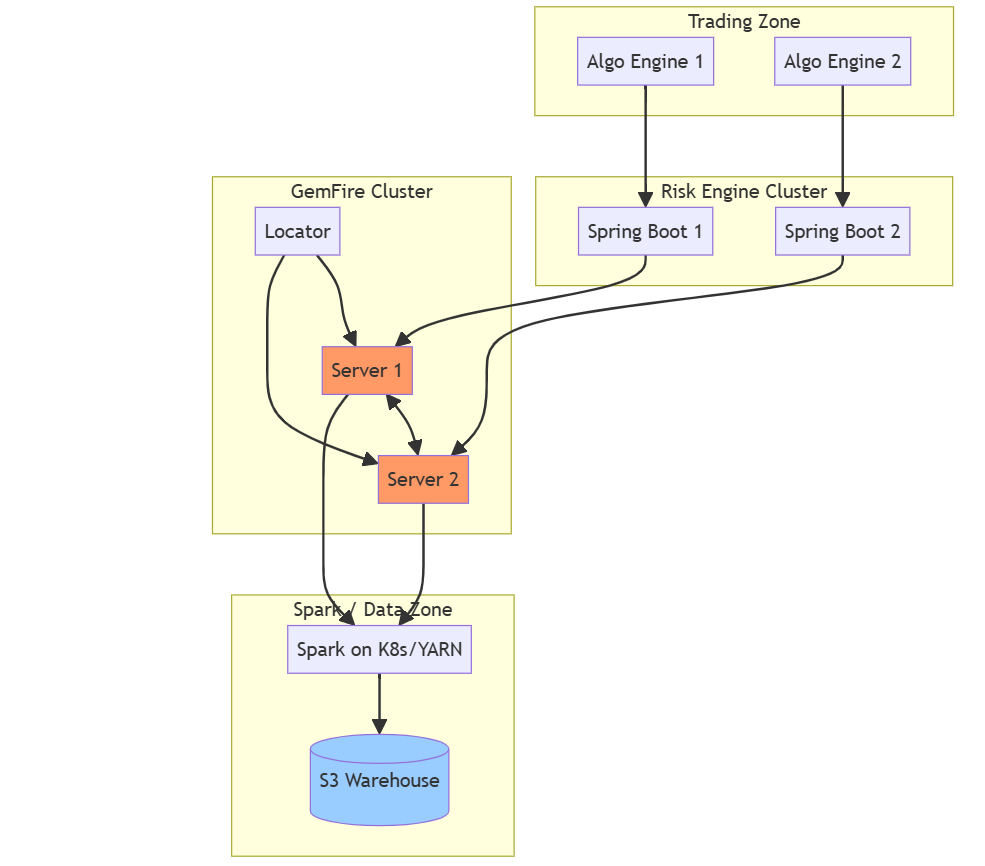
Figure 7: Production deployment. Four zones: Trading, Risk Engine, GemFire, Spark/Data. GemFire servers replicate; Spark writes to S3.
8. Prerequisites and Setup
| Requirement | Version | Download |
|---|---|---|
| Java | 17+ | Adoptium or Oracle JDK 17 |
| Maven | 3.8+ | Apache Maven |
| Git | Any | git-scm.com |
Verify installation:
java -version # Expected: openjdk 17.x or java 17.x9. Quick Start (One Command)
Download the Project
git clone <repository-url>Run the Full Demo
Windows:
.\run-demo.batOr:
.\scripts\run-demo.ps1What happens:
- Builds Risk Engine and Spark Sync
- Starts Risk Engine in a new visible window
- Opens dashboard at http://localhost:8080
- Ingests 4 sample trades (including T002 $12M -> CRITICAL alert)
- Runs Spark Lakehouse sync (90 seconds for screenshots)
- Prints Spark UI URL (http://localhost:4040 or 4041-4044)
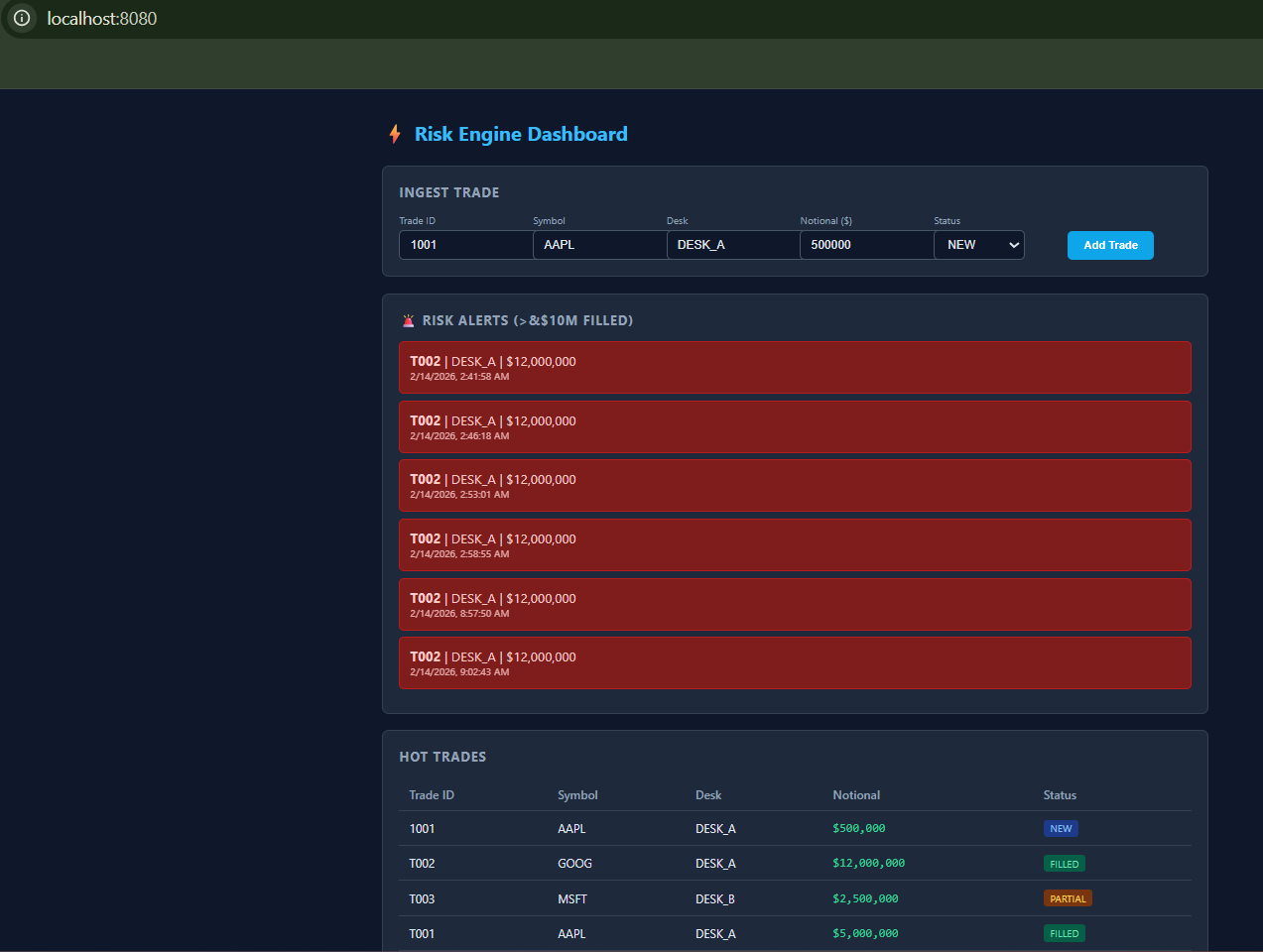
Dashboard with trades and CRITICAL alert for T002
Spark UI showing Jobs/Stages during MERGE
Windows: Fix Spark NativeIO Error
If you see UnsatisfiedLinkError: NativeIO$Windows.access0:
.\scripts\setup-winutils.ps1
Restart your terminal, then run .\run-demo.bat again.
10. The Code: Hot Path
10.1 Maven Dependencies (risk-engine/pom.xml)
Local demo (in-memory store):
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
Production (GemFire):
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.vmware.gemfire</groupId>
<artifactId>spring-boot-3.1-gemfire-10.1</artifactId>
<version>1.0.4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.vmware.gemfire</groupId>
<artifactId>spring-boot-starter-data-gemfire</artifactId>
</dependency>
<dependency>
<groupId>com.vmware.gemfire</groupId>
<artifactId>gemfire-cq</artifactId>
</dependency>
</dependencies>10.2 Domain Model (Trade.java)
Java records are ideal for immutable FinTech data. They handle hashCode/equals for GemFire partition hashing.
package com.hedgefund.risk.domain;
public record Trade(
String tradeId,
String symbol,
String deskId,// e.g., "DESK_A"
double notional, // price * quantity
String status, // NEW, PARTIAL, FILLED
long timestamp )
{}10.3 Request DTO With Validation (TradeRequest.java)
package com.hedgefund.risk.web;
import javax.validation.constraints.*;
public record TradeRequest( @NotBlank(message = "tradeId is required")
String tradeId, @NotBlank @Pattern(regexp = "^[A-Z0-9.]{1,20}$")
String symbol, @NotBlank @Pattern(regexp = "^[A-Z0-9_]{1,50}$")
String deskId, @DecimalMin(value = "0", message = "notional must be non-negative")
double notional, @NotBlank @Pattern(regexp = "^(NEW|PARTIAL|FILLED|CANCELLED)$")
String status ) {}
10.4 REST Controller (TradeController.java)
@RestController
@RequestMapping("/api/trades")
public class TradeController {private final RiskService riskService;
@GetMapping public List<Trade> getAllTrades() {
return riskService.getAllTrades();
}
}10.5 Risk Monitor Service (RiskMonitorService.java)
Continuous risk check: fires when a FILLED trade exceeds $10M.
@Component
public class RiskMonitorService { private static final double RISK_LIMIT = 10_000_000.00;
public void onTradeUpserted(Trade trade) {
if (trade != null && trade.notional() > RISK_LIMIT && "FILLED".equals(trade.status())) {
String msg = String.format("Desk %s exceeded limits with Trade %s ($%,.2f)",
trade.deskId(), trade.tradeId(),
trade.notional());
log.error("[CRITICAL] " + msg);
alerts.add(new RiskAlert(trade.tradeId(),
trade.deskId(),
trade.notional(),
Instant.now()));
}
}
public record RiskAlert(String tradeId,
String deskId,
double notional,
Instant timestamp) {}
}Production (GemFire): Use @ContinuousQuery with OQL: SELECT * FROM /Trades t WHERE t.notional > 10000000 AND t.status = 'FILLED' - runs on server, alert in <2ms.
10.6 CSV Export for Spark (TradeExportService.java)
Exports trades every 5 seconds. Production uses GemFire Connector instead.
@Service
public class TradeExportService {
@Scheduled(fixedRate = 5000)
public void exportForSpark() {
var trades = adapter.values();
String csv = list.stream()
.map(t -> "%s,%s,%s,%.2f,%s,%d".formatted(
t.tradeId(),
t.symbol(),
t.deskId(),
t.notional(),
t.status(),
t.timestamp()
))
.collect(Collectors.joining("\n"));
Files.writeString(
exportPath.resolve("trades.csv"),
CSV_HEADER + csv,
StandardOpenOption.CREATE,
StandardOpenOption.TRUNCATE_EXISTING
);
}
}11. The Code: Cold Path
11.1 Spark + Iceberg MERGE (RiskLakehouseSync.scala)
Trades update (NEW -> PARTIAL -> FILLED). Append-only gives 3 rows per trade. We use MERGE (Upsert).
@RestController
@RequestMapping("/api/trades")
public class TradeController {
private final RiskService riskService;
@GetMapping
public List<Trade> getAllTrades() {
return riskService.getAllTrades();
}
}Production: Use spark.read.format("io.pivotal.gemfire.spark.connector").option("region", "Trades").load() and warehouse s3a://finance-data-lake/warehouse.
11.2 Iceberg Time Travel
Regulator asks: "What did the Risk Report look like at 10:42 AM?"
SELECT * FROM risk_lake.compliance.trade_history
TIMESTAMP AS OF '2026-02-13 10:42:00';12. Manual Setup (Step-by-Step)
Step 1: Build
cd risk-engine && mvn clean package -DskipTests
cd ../spark-sync && mvn clean package -DskipTestsStep 2: Start Risk Engine
cd risk-engine mvn spring-boot:run| Endpoint | URL |
|---|---|
| Dashboard | http://localhost:8080 |
| Health | http://localhost:8080/actuator/health |
| Trades API | http://localhost:8080/api/trades |
| Alerts API | http://localhost:8080/api/alerts |
Step 3: Ingest Trades
Dashboard: Open http://localhost:8080 and use the form.
API (PowerShell):
Invoke-RestMethod -Uri "http://localhost:8080/api/trades" -Method Post `
-Body '{"tradeId":"T001","symbol":"AAPL","deskId":"DESK_A","notional":5000000,"status":"FILLED"}' `
-ContentType "application/json"
Invoke-RestMethod -Uri "http://localhost:8080/api/trades" -Method Post `
-Body '{"tradeId":"T002","symbol":"GOOG","deskId":"DESK_A","notional":12000000,"status":"FILLED"}' `
-ContentType "application/json"Expected: T002 ($12M) triggers CRITICAL alert.
Step 4: Wait 5-8 Seconds
CSV exports to risk-engine/data/hot_trades/trades.csv every 5 seconds.
Step 5: Run Spark Sync
Windows:
$env:MAVEN_OPTS = "--add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED"
cd spark-sync
mvn exec:java -Dexec.mainClass="com.hedgefund.risk.RiskLakehouseSync"Linux/macOS:
export MAVEN_OPTS="--add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED"
cd spark-sync mvn exec:java -Dexec.mainClass="com.hedgefund.risk.RiskLakehouseSync"Spark UI: http://localhost:4040 (or 4041-4044)
13. Troubleshooting
| Issue | Solution |
|---|---|
UnsatisfiedLinkError: NativeIO$Windows.access0 |
Run .\scripts\setup-winutils.ps1, restart terminal |
| Spark UI not loading | Check terminal for port (4040-4044) |
| Risk Engine won't start | Port 8080 in use; check mvn spring-boot:run logs |
| No trades in Spark | Wait 5-8s after ingest; verify trades.csv exists |
14. Production Notes
| Component | Production Change |
|---|---|
| Hot Path | Add spring-boot-starter-data-gemfire, configure pool servers |
| Iceberg | Warehouse: s3a://finance-data-lake/warehouse |
| Spark | Use GemFire Connector: format("io.pivotal.gemfire.spark.connector").option("region", "Trades") |
| GC | ZGC on GemFire servers; 500GB heaps, pauses <2ms |
15. Summary and Next Steps
If you're still maintaining the architecture from Part 1, you're paying a "Legacy Tax" every time you debug a corrupted Hive partition. Upgrade to the 2026 stack-your on-call rotation will thank you.
What you get:
- Sub-2ms risk alerts via Continuous Queries
- ACID upserts with Iceberg (no duplicate rows)
- One-command demo with both UIs visible
- Windows-friendly setup (winutils script)
- Production-ready path (GemFire BOM, S3 warehouse)
Try it: Clone the repo, run .\run-demo.bat, and see the full pipeline in action.
Related Links
Full working code you can find here: https://github.com/vaquarkhan/cd-risk-engine.
Opinions expressed by DZone contributors are their own.
Comments