Red Hat Data Grid 8 for Beginners
This article describes how to get started with Data Grid Server 8.0 which is isolated from the Red Hat JBoss Enterprise Application Platform.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Data Grid ?
Data Grid is a high-performance, distributed in-memory data store. It stores all info in memory rather than on Disk or file that makes it faster. It is built from Infinispan open-source Software project and is available to deploy as an embedded library or as a standalone server.
Data Grid 8.0 Server
Data Grid 8.0 Server is isolated from Red Hat JBoss Enterprise Application Platform (EAP) and is re-designed to be lightweight and more secure with much faster start times. It is designed to create a running Data Grid cluster within few minutes with negligible configuration changes.
8.0 release comes with features like Data Grid Operator, available from the Operator Hub on Red Hat OpenShift , it simplifies the process of creating and managing Data Grid clusters on OpenShift.
It also has a powerful CLI to to access data and perform management operations . Alongside this CLI supports bash commands like cd and ls and provides clear examples of commands.
How to Quickly Set up Data Grid Server 8.0 and Learn the Basics?
Procedure to Download Data grid 8.0
- Download the Red Hat Data Grid 8.0 server from the Get Data Grid for Development
- Verify the the integrity of your download using checksum.
- Run the
md5sumorsha256sumcommand with the server download archive as the argument and compare the checksum value with the Data Grid Software Details page.
xxxxxxxxxx
$ md5sum redhat-datagrid-8.0.0-server.zip
f6d302b8cec812c604c45031cc30ee8d redhat-datagrid-8.0.0-server.zip
5. Next for installation you can extract the Data Grid server archive to a directory on your host.For example:
xxxxxxxxxx
unzip redhat-datagrid-8.0.0-server.zip
The resulting directory is $RHDG_HOME.
By default Data Grid servers running on the same network discover each other with the MPING protocol.
Data Grid server 8.0 provides a default configuration with clustering capabilities so your data is replicated across all nodes.
To start two Data Grid servers on the same host and verify the cluster view:
- Install and run a new Data Grid server instance.
$ bin/server.sh
- Open a terminal in $RHDG_HOME ,copy the root directory to server2.
$ cp -r server server2
- Specify a port offset by passing -o and the location of the server2 root directory.
$ bin/server.sh -o 100 -s server2
- Verify the server logs for the following messages:
xxxxxxxxxx
13:00:51,137 INFO (main) [org.infinispan.SERVER] ISPN080034: Server 'vasharma-57675' listening on http://127.0.0.1:11222
13:00:51,137 INFO (main) [org.infinispan.SERVER] ISPN080001: Red Hat Data Grid Server 10.1.5.Final-redhat-00001 started in 4682ms
13:02:50,330 INFO (jgroups-5,vasharma-57675) [org.infinispan.CLUSTER] ISPN000094: Received new cluster view for channel cluster: [vasharma-57675|1] (2) [vasharma-57675, vasharma-32704]
13:02:50,335 INFO (jgroups-5,vasharma-57675) [org.infinispan.CLUSTER] ISPN100000: Node vasharma-32704 joined the cluster
13:02:50,831 INFO (remote-thread--p3-t1) [org.infinispan.CLUSTER] [Context=org.infinispan.CLIENT_SERVER_TX_TABLE]ISPN100002: Starting rebalance with members [vasharma-57675, vasharma-32704], phase READ_OLD_WRITE_ALL, topology id 2
- To start Data Grid servers on two different host pass -b 192.168.xxx.x
./server.sh -s /location of the server root directory
-b 192.168.xxx.x
- Open
127.0.0.1:11222in any browser to access the Data Grid console
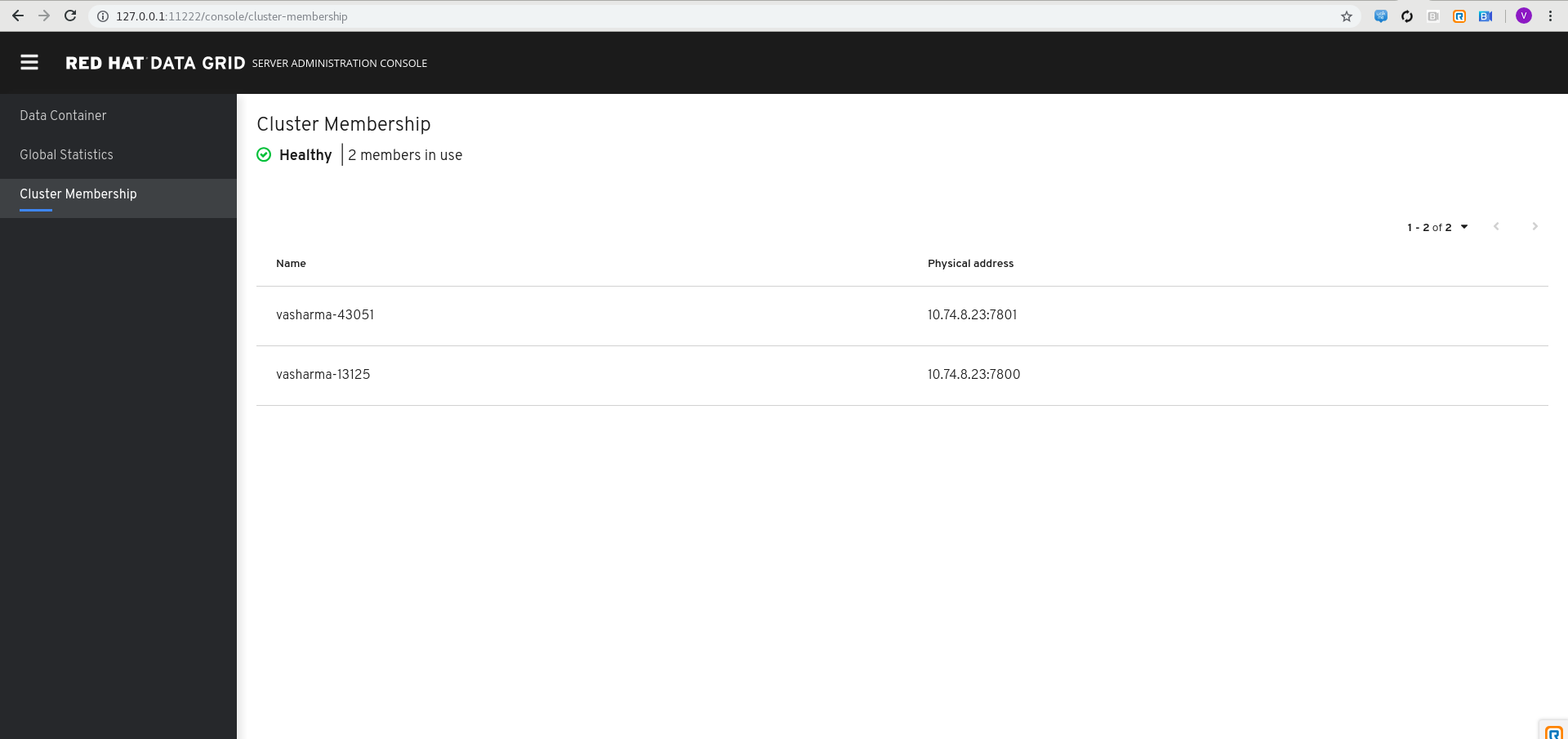
Configuration Files of Data Grid 8
- infinispan-local.xml
- infinispan.xml
- infinispan-xsite.xml
By default if not specified Data Grid 8.0 uses $RHDG_HOME/server/conf/infinispan.xml for configuration.
Configuration file can be specified while starting data grid server using -c option .
For example : $ ./server.sh -c infinispan-local.xml.
Infinspan-local.xml can be used to start Data Grid in standalone mode..
Data Grid server 8.0 no longer provides a domain mode as in previous versions that were based on EAP.
Data Grid 8.0 CLI
In order to connect to CLI start the Data Grid CLI as follows:
- Open a terminal in
$ISPN_HOME. Run the CLI.
$ bin/cli.sh [disconnected]>
Run the
connectcommand to connect to a Data Grid server on the default port of11222:
[disconnected]> connect
[hostname1@cluster//containers/default]>
Specify the location of a Data Grid server. For example, connect to a local server that has a port offset of 100:
[disconnected]> connect 127.0.0.1:11322
[hostname2@cluster//containers/default]>
Press the tab key to display available commands and options. Use the -hoption to display help text.
CLI is used to gracefully shutdown running servers. This ensures that Data Grid passivates all entries to disk and persists state.
Use the
shutdown servercommand to stop individual servers.
[//containers/default]> shutdown server $hostname
Use the
shutdown clustercommand to stop all servers joined to the cluster.
[//containers/default]> shutdown cluster
Data Grid Operator
The OpenShift Operators Tech Topic and the Operators in the CoreOS documentation are simplified resources for more details about Operators.
If new to OpenShift you can try Interactive learning.
Data Grid Operator helps to create, configure, and manage Data Grid clusters. You can try Katakoda.com - Getting Started with Data Grid on OpenShift
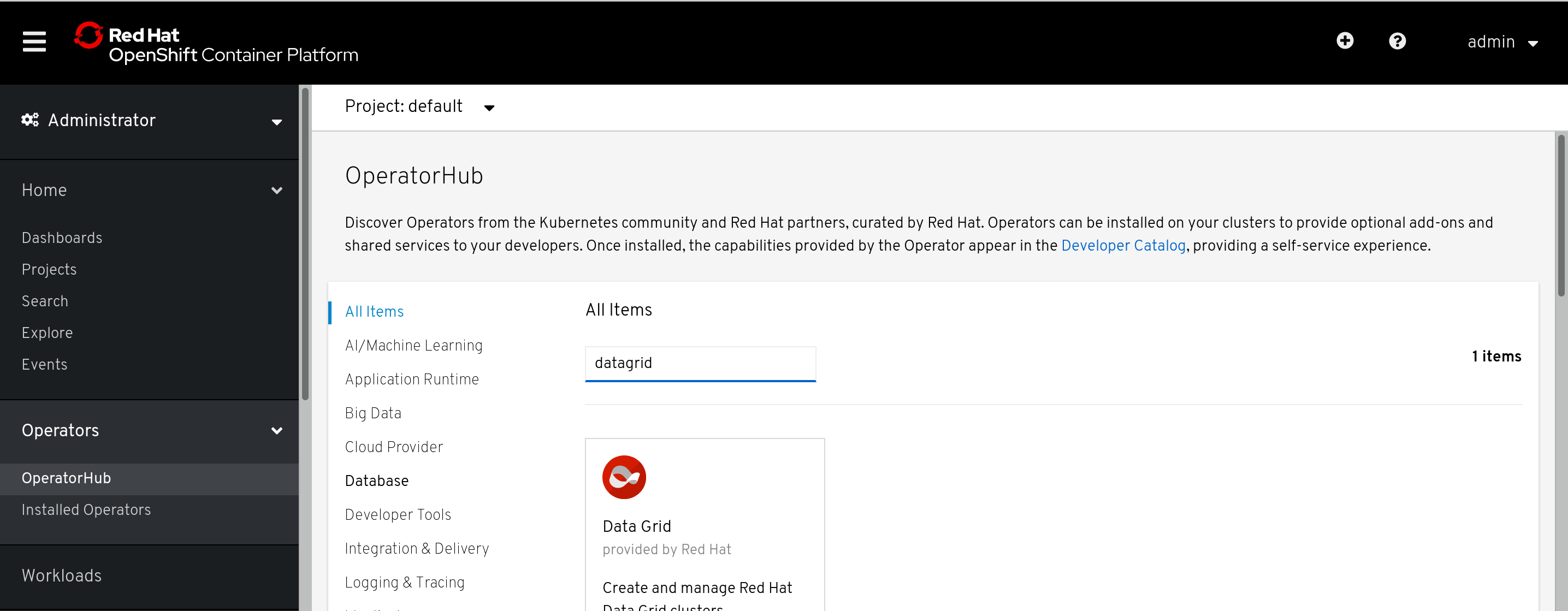
Red Hat Data Grid 8.0 introduces a fully supported Operator that provides operational intelligence, using Kubernetes APIs to handle operations and manage application life-cycles. As a result, it’s easier than ever before to deploy and manage complex applications—like distributed datastores that is consumed as a service. They get upgraded automatically, with no need for human intervention.
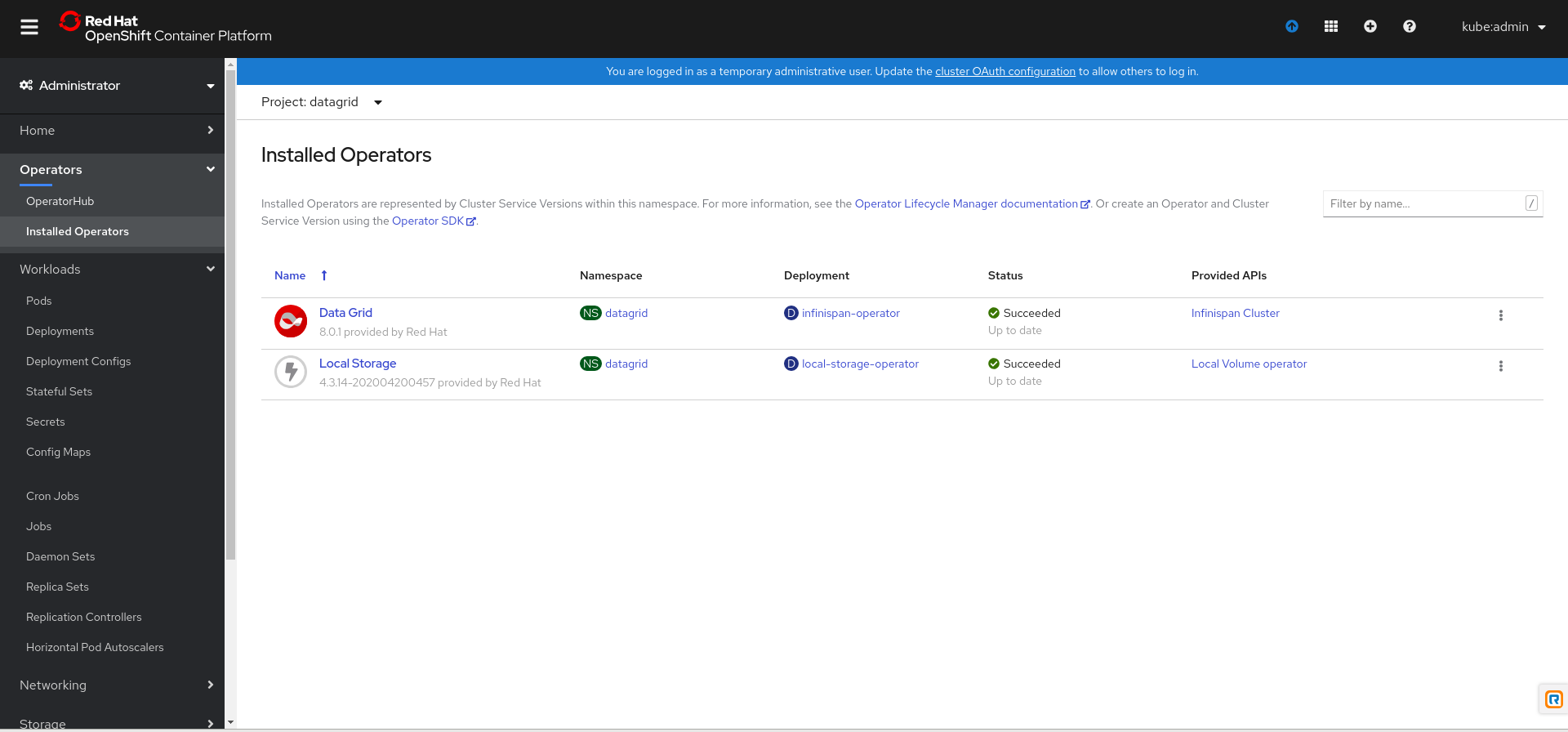
Prerequisites
- Create a Data Grid Operator subscription.
- Have an
occlient
Data Grid Operator adds a new Custom Resource (CR) of type Infinispan that lets you handle Data Grid clusters as complex units on OpenShift.
You configure Data Grid clusters running on OpenShift by modifying the Infinispan CR.
The minimal Infinispan CR for Data Grid clusters is as follows:
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: ---> names the Data Grid Cluster
spec:
replicas:2 ---> specifies the number of nodes in Cluster.
Procedure
Specify the number of Data Grid nodes in the cluster with
spec.replicasin your Infinispan CR.For example, create a
cr_demo.yamlfile as follows:YAML
xxxxxxxxxx1
1$ cat > cr_demo.yaml<<EOF2apiVersioninfinispan.org/v13kindInfinispan4metadata5nameexample-rhdatagrid6spec7replicas28EOF
Apply your Infinispan CR.
$ oc apply -f cr_minimal.yaml
Verify Data Grid Operator creating the Data Grid nodes.
$ oc get po NAME READY STATUS RESTARTS AGE infinispan-operator-0 1/1 Running 0 3m example-rhdatagrid-3 1/1 Running 0 8s example-rhdatagrid-2 1/1 Running 0 8s example-rhdatagrid-1 1/1 Running 0 8s
Cluster view can be verified from logs :
xxxxxxxxxx
$ oc logs example-rhdatagrid-0 | grep ISPN000094
INFO org.infinispan.CLUSTER (MSC service thread 1-2) \
ISPN000094Received new cluster view for channel infinispan\
example-rhdatagrid-0|0 (1) example-rhdatagrid-0
INFO org.infinispan.CLUSTER (jgroups-3,example_crd_name-0) \
ISPN000094Received new cluster view for channel infinispan\
example-rhdatagrid-0|1 (2) example-rhdatagrid-0 example-rhdatagrid-1
Opinions expressed by DZone contributors are their own.
Comments