Regular Expressions Denial of the Service (ReDOS) Attacks: From the Exploitation to the Prevention
Join the DZone community and get the full member experience.
Join For Freeautors :michael hidalgo, dinis cruz
introduction
when it comes to web application security, one of the recommendations to write software that is resilient to attacks is to perform a correct input data validation. however, as mobile applications and apis (application programming interface) proliferates, the number of untrusted sources where data comes from goes up, and a potential attacker can take advantage of the lack of validations to compromise our applications.
regular expressions provides a versatile mechanism to perform input data validation. developers use them to validate email addresses, zip codes, phone numbers and many other task that are easily implemented thought them.
unfortunately most of the time software engineers don't fully understand how regular expressions works in the background and by choosing a wrong regular expression pattern they can introduce a risk in the application.
in this article we are going to discuss about the so called regular expression denial of the service (redos) vulnerability and how we can identify this problems early in the software development life cycle (sdlc) stages by enforcing a culture focused on unit testing.
hardware features for this article
in order to provide information about execution time, performance, cpu utilisation and other facts, we are relying on virtual machine that uses windows 7 32-bit operating system, 5.22 gb ram. intel(r) core (tm) it-3820qm cpu @2.7 ghz. we are also using 4 cores.
understanding the problem.
the owasp foundation (2012) defines a regular regular expression denial of service attack as follows:
"the regular expression denial of service (redos) is a denial of service attack, that exploits the fact that most regular expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). an attacker can then cause a program using a regular expression to enter these extreme situations and then hang for a very long time."
although a broad explanation about regular expression engines is out of the scope of this article,it is important to understand that, according to stubblebine,t (regular expressions pocket reference), a pattern matching consist of finding a section of text that is described (matched) by a regular expression. two main rules are used to match results:
- the earliest (leftmost) wins : the regular expression is applied to the input starting at the first character and moving toward the last. as soon as the regular expression engine finds a match,it returns.
- standard quantifiers are greedy : according to stubblebine, "quantifiers specify how many times something can be repeated. the standard quantifiers attempt to match as many times as possible. the process of giving up characters and trying less-greedy matches is called backtracking."
for this article we are focused a regular expression engine called nondeterministic finite automaton (nfa).this engines usually compare each element of the regex to the input string, keeping track of positions where it chose between two options in the regex. if an option fails, the engine backtracks to the most recently saved position.(stubblebine,t 2007). it is important to note that this engine is also implemented in .net, java, python, php and ruby on rails.
this article is focused on c# and therefore we are relying on the microsoft .net framework system.text.regularexpression classes which at the heart uses nfa engines.
according to bryan sullivan
"one important side effect of backtracking is that while the regex engine can fairly quickly confirm a positive match (that is, an input string does match a given regex), confirming a negative match (the input string does not match the regex) can take quite a bit longer. in fact, the engine must confirm that none of the possible “paths” through the input string match the regex, which means that all paths have to be tested. with a simple non-grouping regular expression, the time spent to confirm negative matches is not a huge problem."
in order to illustrate the problem, let's use this regular expression (\w+\d+)+c which basically performs the following checks:
- between one and unlimited times, as many times as possible, giving back as needed.
- \w+ match any word character a-za-z0-9_ .
- \d+ match a digit 0-9
- matches the character c literally (case sensitive)
so matching values are 12c,1232323232c and !!!!cd4c and non matching values are for instance !!!!!c,aaaaaac and abababababc .
the following unit test was created to verify both cases.
const string regexpattern = @"(\w+\d+)+c";
public void testregularexpression()
{
var validinput = "1234567c";
var invalidinput = "aaaaaaac";
regex.ismatch(validinput, regexpattern).assert_is_true();
regex.ismatch(invalidinput, regexpattern).assert_is_false();
}
execution time : 6 millisecondsnow that we've verified that our regular expression works well, let's write a new unit test to understand the backtracking problem and the performance effects.
note that the longer the string, the longer the time the regular expression engine will take to resolve it. we will generate 10 random strings, starting at the length of 15 characters, incrementing the length until get to 25 characters,and then we will see the execution times.
const string regexpattern = @"(\w+\d+)+c";
[testmethod]
public void isvalidinput()
{
var sw = new stopwatch();
int16 maxiterations = 25;
for (var index = 15; index < maxiterations; index++)
{
sw.start();
//generating x random numbers using fluentsharp api
var input = index.randomnumbers() + "!";
regex.ismatch(input, regexpattern).assert_false();
sw.stop();
sw.reset();
}
}now let's take a look at the test results:
| random string | character length | elapsed time (ms) |
|---|---|---|
| 360817709111694! | 16 | 16ms |
| 2639383945572745! | 17 | 23ms |
| 57994905459869261! | 18 | 50ms |
| 327218096525942566! | 19 | 106ms |
| 4700367489525396856! | 20 | 207ms |
| 24889747040739379138! | 21 | 394ms |
| 156014309536784168029! | 22 | 795ms |
| 8797112169446577775348! | 23 | 1595ms |
| 41494510101927739218368! | 24 | 3200ms |
| 112649159593822679584363! | 25 | 6323ms |
by looking at this results we can understand that the execution time (total time to resolve the input text against the regular expression) goes up exponentially to the size of the input.
we can also see that when we append a new character, the execution time almost duplicates. this is an important finding because shows how expensive this process is, if we do not have a correct input data validation we can introduce performance issues in our application.
a real-life use-case and an appeal for a unit testing approach
now that we have seen the problems we can face by selecting a wrong (evil) regular expression, let's discuss about a realistic scenario where we need to validate input data thought regular expressions.
we strongly believe that unit testing techniques can not only help to write quality code but also we can use them to find vulnerabilities in the code we are writing. by writing unit test that performs security checks (like input data validation)
a common task in web applications consist on request an email address to the user signing in our application. from a ux (user experience perspective) complaining browsers support friendly error messages when an input, that was supposed to be an email address, does not match with the requirements in terms of format. here is a ui validation when a input textbox (with the email type is set) and the value is not a valid email address.
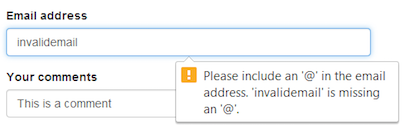
however relying on a ui validation is not longer enough. an eavesdropper can easily perform an http request without using a browser (namely by using a proxy to capture data in transit) and then send a payload that can compromise our application.
in the following use case, we are using a backend validation for the email address by using a regular expression. we will show you the real power of regular expressions here, we are not only testing that the regular expression validates the input but also how it behaves when it receives any arbitrary input.
we are using this evil regular expression to validate the email: ^( 0-9a-za-z @([0-9a-za-z][-\w][0-9a-za-z].)+[a-za-z]{2,9})$ .
with the following test we are verifying that a valid email and invalid emails formats are correctly processed by the regular expression, which is the functional aspect from a development point of view.
const string emailregex = @"^([0-9a-za-z]([-.\w]*[0-9a-za-z])*@([0-9a-za-z][-\w]*[0-9a-za-z]\.)+[a-za-z]{2,9})$";
[testmethod]
public void validateemailaddress()
{
var validemailaddress = "[email protected]";
var invalidemailaddress = new string[] { "a", "abc.com", "1212", "aa.bb.cc", "aabcr@s" };
regex.ismatch(validemailaddress, emailregex).assert_is_true();
//looping throught invalid email address
foreach (var email in invalidemailaddress)
{
regex.ismatch(email, emailregex).assert_is_false();
}
}
elapsed time: 6ms.so both cases are validate correctly. one could state that both scenarios supported by the unit test are enough to select this regular expression for our input data validations. however we can do a more extensive testing as you'll see.
the exploit
so far the previous regular expression selected to valid an email address seems to work well, we have added some unit test that verifies valid an invalid inputs.
but how does it behaves when we send an arbitrary input?, from a variable length, do we face a denial of the service attack?.
this kind of questions can be solved wit unit testing technique like this one:
const string emailregex = @"^([0-9a-za-z]([-.\w]*[0-9a-za-z])*@([0-9a-za-z][-\w]*[0-9a-za-z]\.)+[a-za-z]{2,9})$";
[testmethod]
public void validateemailaddress()
{
var validemailaddress = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!";
var watch = new stopwatch();
watch.start();
validemailaddress.regex(emailregex).assert_is_false();
watch.stop();
console.writeline("elapsed time {0}ms", watch.elapsedmilliseconds);
watch.reset();
}
**elapsed time : ~23 minutes (1423127 milliseconds).**results are disturbing. we can clearly see the performance problem introduced by evaluating the given input.it takes roughly 23 minutes to validate the input given the hardware characteristics described before.
in the following images you will see the cpu behaviour when running this unit test.
here is another cpu utlization:

and this is another image from the cpu utilization while the test is running.

fuzzing and unit testing: a perfect combination of techniques
in the previous unit test we found that a given input string can lead to have denial of the service issue in our application. note that we didn't need an extreme large payload, in our scenario 34 characters can illustrate this problem or even less. when using any regular expression it is recomendable to always test it against unit testing to cover most of the possible ways a user (which can be a potential attacker) can send.
here is where we can use fuzzing.
tobias klein in his book a bug hunter's diary a guide tour throught the wilds of sofware security defines fuzzing as
"a complete different approach to bug hunting is known as fuzzing. fuzzing is a dynamic-analysis technique that consist of testing an application by providing it with malformed or unexpected input.
then klein continues adding that:
"it isn't easy to identify the entry points of such complex applications, but complex software often tends to crash while processing malformed input data. page 05"
mano paul in his book official (isc)2 guide to the csslp talking about fuzzing states that:
"also known as fuzz testing or fault injection testing, fuzzing is a brute-force type of testing in which faults (random and pseudo-random input data) are injected into the software and it's behaviour is observed. it is a test whose results are indicative of the extended and effectiveness of the input validation.page 336".
taking previous definitions into consideration, we are going to implement a new unit test that can allow us to generate random input data and test our regular expression.
in this case, we are using this email regular expression "^[\w-.]{1,}\@([\w]{1,}.){1,}[a-z]{2,4}$"; and by doing an exhaustive testing we will see if we are not introducing a denial of the service problem.
we want to make sure that the elapsed time to resolve if the random string matches the regular expression is evaluated in less than 3 seconds:
const string emailregex = @"^[\w-\.]{1,}\@([\w]{1,}\.){1,}[a-z]{2,4}$";
//number of random strings to generte.
const int maxiterations = 10000;
[testmethod]
public void fuzz_emailaddress()
{
//valid email should return true
"[email protected]".regex(emailregex).assert_is_true();
//invalid email should return false
"abce" .regex(emailregex).assert_is_false();
//testing maxiterations times
for (int index = 0; index < maxiterations; index++)
{
//generating a random string
var fuzzinput = (index * 5).randomstring();
var sw = new stopwatch();
sw.start();
fuzzinput.regex(emailregex).assert_is_false();
//elapsed time should be less than 3 seconds per input.
sw.elapsed.seconds().assert_size_is_smaller_than(3);
}
}under the hardware features described before, this test passes. considering that we are using this computation (index * 5), the largest string generate is of 49995 character (which is 9999 *5).
having said that we were able to test a large string against the regular expression and we confirmed that even thought it is quite large input value, the time involved to verify if it was or not a valid email, it was less than 3 seconds.
now assuming that a check for the length of the email in the first place, it will guarantee that a malicious user can't inject a large payload in our application.
countermeasures provided in microsoft .net 4.5 and upper
if you are developing applications in microsoft .net 4.5 then you can take advantage of a new implementation on top of the ismatch method from the regex class . starting from .net 4.5 the ismatch method provides an overload that allows you to enter a timeout. note that this overload is not available in .net 4.0 .
this new parameter is called matchtimeout and according to microsoft :
"the matchtimeout parameter specifies how long a pattern matching method should try to find a match before it times out. setting a time-out interval prevents regular expressions that rely on excessive backtracking from appearing to stop responding when they process input that contains near matches. for more information, see best practices for regular expressions in the .net framework and backtracking in regular expressions . if no match is found in that time interval, the method throws a regexmatchtimeoutexception exception. matchtimeout overrides any default time-out value defined for the application domain in which the method executes." taken from here .
we've written a new unit test where we're using a regular expression that we know can lead to denial of the service. in this case we'll test an email address that previously generated a significant side effect in the performance of the application. we'll see then how we can reduce the impact of this process by setting up a timeout.
const string emailregexpattern = @"^([0-9a-za-z]([-.\w]*[0-9a-za-z])*@([0-9a-za-z][-\w]*[0-9a-za-z]\.)+[a-za-z]{2,9})$";
[testmethod]
public void validateemailaddress()
{
var emailaddress = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!";
var watch = new stopwatch();
watch.start();
//timeout of 5 seconds
try
{
regex.ismatch(emailaddress, emailregexpattern,
regexoptions.ignorecase,
timespan.fromseconds(5));
}
catch (exception ex)
{
ex.message.assert_not_null();
ex.gettype().assert_is(typeof(regexmatchtimeoutexception));
}
finally
{
watch.stop();
watch.elapsed.seconds().assert_size_is_smaller_than(5);
watch.reset();
}
}running this test in visual studio we can confirm it passes, which means that the backtracking mechanism is taking longer than 5 seconds to resolve.
it will throw a regexmatchtimeoutexception exception indicating that it might take longer than 5 seconds to evaluate the input. ideally one would expect this process to take less than a second, however several conditions or requirements might lead to allow a timeout in seconds.

note how this model provides a very needed defensive programming style where the software engineers make informed decisions on the code they write, in this case we can establish the next steps when our method times and that way we can decrease any denial of the service attack.
final thoughts
no one size fits all is so cliché that has to be true. we are not sure if the regular expressions you are currently using in your applications are vulnerable to this attack. what we can do for sure is to show you how you can take advantage of unit testing to write secure code.
when we write code we want to make sure that each single line of code is covered by a unit testing, which at the end of the day will guarantee early detections of error. however if we can combine this exercise with the adoption and implementation of test that can also try to attack/compromise the application (and we are not talking about anything fancy) like sending random strings, using fuzzing techniques, using combination of characters, exceeding the expected length, we will be helping to write software that is resilient to attacks.
as a recommendation always test your regular expressions agains uni test, make sure that they are resilient to the attack we have covered in this article and if you are able to identify those problematic patterns out there, do a contribution and report them so we are not introduce them in the software we write.
references
1.cruz,dinis(2013) the email regex that (could had) dosed a site.
2.hollos,s. hollos,r (2013) finite automata and regular expressions problems and solutions.
3.kirrage,j. rathnayake , thielecke, h.: static analysis for regular expression denial-of-service attacks. university of birmingham, uk
4.klein, t. a bug hunter's diary a guided tour through the wilds of software security (2011).
5.the owasp foundation (2012) regular expression denial of service - redos.
6.stubblebine, t(2007) regular expression pocket reference, second edition.
7.sullivan, b (2010) regular expression denial of service attacks and defenses
Opinions expressed by DZone contributors are their own.
Comments