REST API Microservice AI Design and Spreadsheet Rules
Use API Logic Server open source platform to build and deploy spreadsheet rules for any SQL database. This article shows a budgeting application using declarative rules.
Join the DZone community and get the full member experience.
Join For FreeLet's use ChatGPT to build a REST API Microservice for a budgeting application. This needs to support multi-tenant security and include actual spending matched against budget categories. Of course, a Google sheet or Excel would be the simple answer. However, I wanted a multi-user cloud solution and to use the new open-source REST API microservice platform API Logic Server (ALS). Our microservice needs an SQL database, an ORM, a server, REST API, react-admin UI, and a docker container.
AI Design of the Data Model
I started by asking ChatGPT 3.5 to generate a budget application data model.
## Create MySQL tables to do a budgeting application with sample account dataThis gave me the basic starting point with a budget, category, user, transaction (for actual spending), and account tables. However, we need to translate the spreadsheet model to a database design with rules to handle the sums, counts, and formulas. I started with the SQL group and asked ChatGPT to add new tables for CategoryTotal, MonthTotal, and YearTotal. I renamed the tables and added a flag on the category table to separate expenses from income budget items.
![budget application]() MySQL
MySQL
-- Month Total
select month_id, count(*), sum(amount) as 'Budget Amount', sum(actual_amount)
from budget
where user_id = 1 and year_id = 2023
group by year_id, month_id
-- Category Total
select category_id, count(*), sum(amount) as 'Budget Amount', sum(actual_amount)
from budget
where user_id = 1 and year_id = 2023
group by year_id, category_id

-- Month Total
select month_id, count(*), sum(amount) as 'Budget Amount', sum(actual_amount)
from budget
where user_id = 1 and year_id = 2023
group by year_id, month_id
-- Category Total
select category_id, count(*), sum(amount) as 'Budget Amount', sum(actual_amount)
from budget
where user_id = 1 and year_id = 2023
group by year_id, category_id 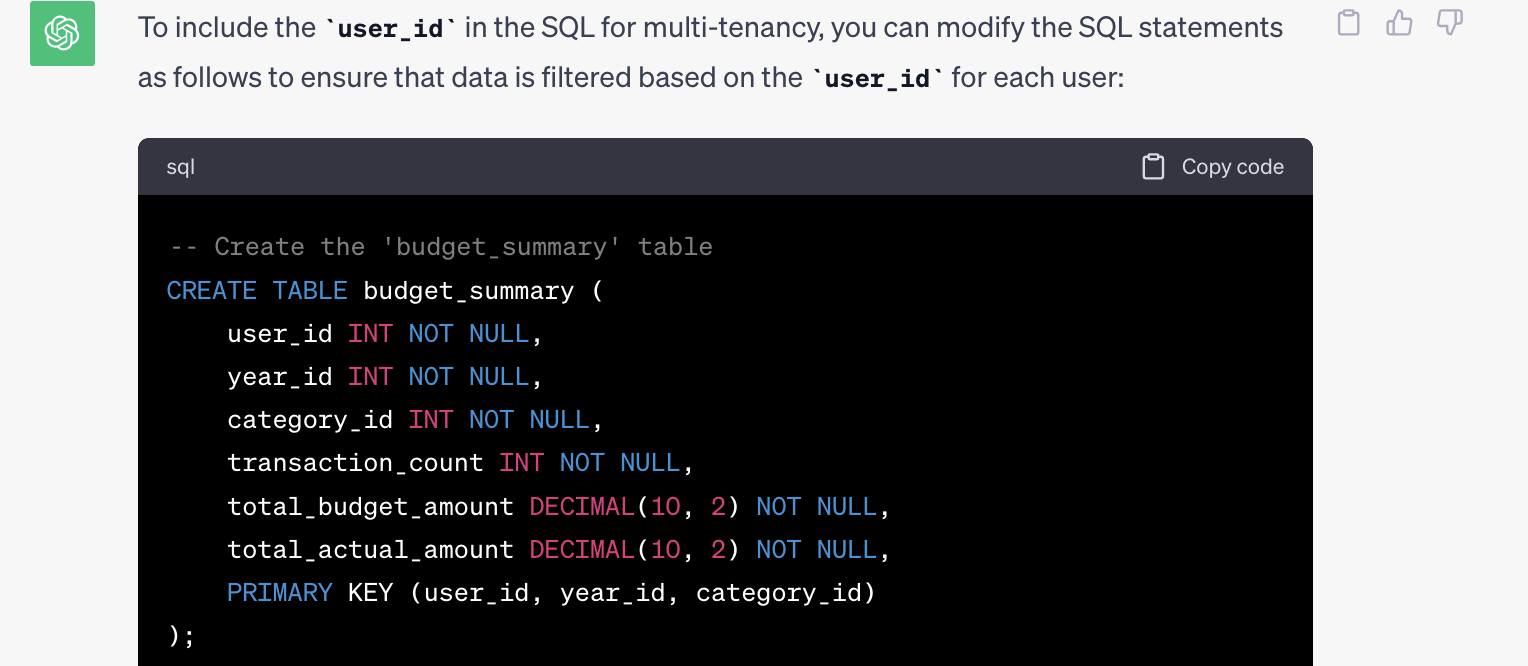
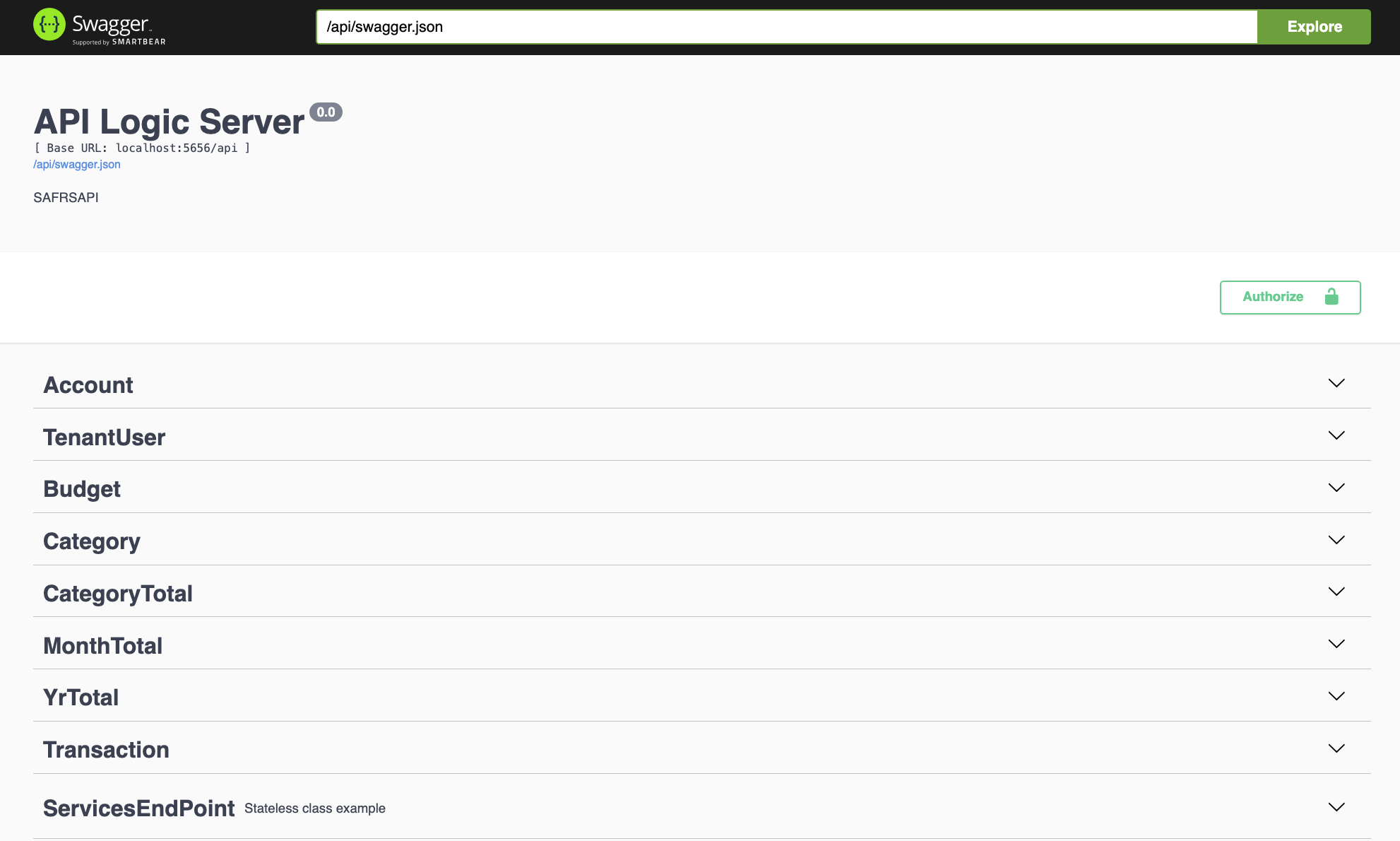
I installed Python and API Logic Server (an open-source Python microservice platform) and used the command line interface to connect to the MySQL database. This created a SQLAlchemy model, a react-admin UI, and an OpenAPI (Swagger).

Command Line To Create a New Project
Install ALS, create the sample project, and start VSCode (press F5 to run).
$python -m venv venv; venv\Scripts\activate # win
$python3 -m venv venv; . venv/bin/activate # mac/linux
$python -m pip install ApiLogicServer
Collecting ApiLogicServer
Downloading ApiLogicServer-9.5.0-py3-none-any.whl (11.2 MB)
━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━━━━━━━━━━━ 5.3/11.2 MB 269.0 kB/s eta 0:00:23
.... truncated ....
$ApiLogicServer create --project_name=BudgetApp --db_url=BudgetApp
$cd BudgetApp
$code .SQLAlchemy Model
Api Logic Server created a SQLAlchemy class definition for each table. This shows the Budget entity (table: budget), columns, and relationships. If the database model changes, this can easily be regenerated as part of the development lifecycle process.
class Budget(SAFRSBase, Base):
__tablename__ = 'budget'
_s_collection_name = 'Budget' # type: ignore
__bind_key__ = 'None'
__table_args__ = (
ForeignKeyConstraint(['year_id', 'category_id', 'user_id'], ['category_total.year_id', 'category_total.category_id', 'category_total.user_id'], ondelete='CASCADE'),
ForeignKeyConstraint(['year_id', 'month_id', 'user_id'], ['month_total.year_id', 'month_total.month_id', 'month_total.user_id'], ondelete='CASCADE')
)
budget_id = Column(Integer, primary_key=True)
year_id = Column(Integer, server_default="2023")
month_id = Column(Integer, nullable=False)
user_id = Column(ForeignKey('tenant_user.user_id'), nullable=False)
category_id = Column(ForeignKey('categories.category_id'), nullable=False)
description = Column(String(200))
amount : DECIMAL = Column(DECIMAL(10, 2), nullable=False)
actual_amount : DECIMAL = Column(DECIMAL(10, 2), server_default="0")
variance_amount : DECIMAL = Column(DECIMAL(10, 2), server_default="0")
count_transactions = Column(Integer, server_default="0")
budget_date = Column(DateTime, server_default=text("CURRENT_TIMESTAMP"))
is_expense = Column(Integer, server_default="1")
# parent relationships (access parent)
category : Mapped["Category"] = relationship(back_populates=("BudgetList"))
user : Mapped["TenantUser"] = relationship(back_populates=("BudgetList"))
category_total : Mapped["CategoryTotal"] = relationship(back_populates=("BudgetList"))
month_total : Mapped["MonthTotal"] = elationship(back_populates=("BudgetList"))
# child relationships (access children)
TransactionList : Mapped[List["Transaction"]] = relationship(back_populates="budget")OpenAPI Created for Each Table
Declarative Rules
API Logic Server rules are similar to spreadsheet definitions but derive (and persist) values at the column level when updates are submitted. And like a spreadsheet, the order of operations is determined based on the state dependency of the change. API Logic Server has an open-source rule engine (LogicBank) that monitors updates using SQLAlchemy before the flush event. That means rule invocation is automatic, multi-table, and eliminates an entire class of programming errors (i.e., rules execute for every insert, update, or delete).
To aggregate a column, we need a parent table. Note that in a spreadsheet, the column totals are aggregated using a ‘sum’ or ‘count.’ The insert_parent flag allows the child row to create the parent row if it does not exist (using the multiple foreign keys) before doing the aggregations. This feature can do multi-level group-bys for all types of applications (e.g., accounting group by debit/credit for year, month, quarter). While an SQL group-by can yield a similar result, declarative rules adjust and persist the column values during insert, update, or delete.
Spreadsheet-like declarative rules are entered using code completion, and examples are shown below:
RULE |
Example |
Notes |
Sum |
Rule.sum(derive=models.MonthTotal.budt_amount, as_sum_of=models.Budget.amount, where=Lambda row: row.year_id == 2023) |
Derive parent-attribute as sum of designated child attribute; optional child qualification |
Count |
Rule.count(derive=models.Budget.transaction_count, as_count_of=models.Transaction,where=Lambda row: row.year_id == 2023) |
Derive parent-attribute as count of child rows; optional child qualification |
Formula |
Rule.formula(derive=models.Budget.variance, as_expression=lambda row: row.actual_amount - row.amount) |
Lambda function computes column value |
Constraint |
Rule.constraint(validate=models.Customer, as_condition=lambda row: row.Balance <= row.CreditLimit, error_msg="balance ({row.Balance}) exceeds credit ({row.CreditLimit})") |
Boolean lambda function must be True else transaction rolled back with message |
Copy |
Rule.copy(derive=models.Transaction.month_id, from_parent=models.Budget.month_id) |
Child value copied from parent column |
Event |
Rule.row_event(on_class=models.Budget, calling=my_function) |
Python Function call (early eventy, row event, and commit event) |
Sum Rule
These simple declarations will aggregate the budget amount transaction amount and calculate the variance to the CategoryTotal, MonthTotal, and YrTotal tables. Note the flag (insert_parent) will create the parent row if it does not exist before doing the aggregation... The code completion feature makes the rule declarations easy. The rules are optimized and will handle insert updates. Delete by adjusting the values instead of doing an SQL group by formula, sum, or count each time a change is detected. (see logic/declare_logic.py)
Rule.sum(derive=models.YrTotal.budget_total, as_sum_of=models.CategoryTotal.budget_total,insert_parent=True)
Rule.sum(derive=models.CategoryTotal.budget_total, as_sum_of=models.Budget.amount,insert_parent=True)
Rule.sum(derive=models.MonthTotal.budget_total, as_sum_of=models.Budget.amount,insert_parent=True)Note: rules are un-ordered and will create a runtime log of the firing sequence based on state dependencies. That makes iterations rapid (no need to review logic to determine where to insert new code) and less error-prone.
Create a Custom API
In addition to SQLAlchemy Model creation, API Logic Server also creates a restful JSON API for created endpoints. This unblocks UI developers immediately.
Here, we create a new custom REST API to POST a batch of actual CSV transactions. While API Logic Server has already created endpoints for API/budget and API/transaction — this is a demonstration of how to extend the REST API. The new endpoints show up in the OpenAPI (Swagger) and allow testing directly. The SQLAlchemy and Flask/safrs JSON API allow a great deal of flexibility to perform complex filters and queries to shape rest APIs’. (see api/customize_api.py)
class BatchTransactions(safrs.JABase):
@classmethod
@jsonapi_rpc(http_methods=["POST"])
def csv_transaction_insert(cls, *args, **kwargs):
""" # yaml creates Swagger description
args :
budget_id: 1
amount: 100
category_id: 1
description: 'test transaction insert'
"""
db = safrs.DB
session = db.session
# we parse the POST *kwargs to handle multiple transactions - returns JSON
# the csv has date, category, and amount
for csv_row in get_csv_payload(kwargs):
trans = models.Transaction()
trans.category_id = lookup_category(csv_row, "category")
trans.amount = csv_row.amount
trans.transaction_date = csv_row.date
session.add(trans)
return {"transaction(s) insert done"}
@classmethod
@jsonapi_rpc(http_methods=["GET"])
def get_budget(cls, *args, **kwargs):
'''
Use SQLAlchemy to get budget, category, month, and year total
'''
db = safrs.DB # valid only after is initialized, above
session = db.session
user_id = Security.current_user().user_id
budget_list = session.query(models.Budget).filter(models.Budget.year_id == 2023 and models.Budget.user_id == user_id).all()
result = []
for row in budget_list:
budget_row = (jsonify(row).json)['attributes']
month_total = (jsonify(row.month_total).json)['attributes']
category_total = (jsonify(row.category_total).json)['attributes']
year_total = (jsonify(row.category_total.yr_total).json)['attributes']
result.append({"budget":budget_row,
"category_total":category_total,
"month_total": month_total,
"year_total": year_total})
return jsonify(result)Declarative Security
We can initialize the API Logic Server to use a custom secure login, and this will enable declarative security. Security has two parts: authentication (login) and authorization (access). The security/declare_authorization.py file lets us declare a global tenant filter for all roles (except admin or sa). Adding a GlobalFilter will apply an additional where clause to any table that has a column named "user_id." The default role permission applies to the users' role and defines the global access setting. Grants can be applied to a role to further extend or remove access to an endpoint.
class Roles():
''' Define Roles here, so can use code completion (Roles.tenant) '''
tenant = "tenant"
renter = "renter"
admin = "admin"
sa = "sa"
DefaultRolePermission(to_role=Roles.tenant,can_read=True, can_delete=False)
DefaultRolePermission(to_role=Roles.admin,can_read=True, can_delete=True)
GlobalFilter(global_filter_attribute_name="user_id",
roles_not_filtered = ["sa", "admin"],
filter="{entity_class}.user_id == Security.current_user().id")Iterative Development
The concept of API lifecycle management is critical. I added a variance column to each table (budget, month_total, category_total, and yr_total) to calculate the difference between the actual_amount minus budget_amount. I changed the SQL database (SQLite) and then asked the API Logic Server command line to rebuild-model-from-database. This will rebuild the database/model.py and the react-dmin UI, while preserving the logic and security we already defined.
CLI to rebuild-from-database
ApiLogicServer rebuild-from-database --project_name=BudgetApp --db_url=BudgetAppFormula Rules operate at the column (aka field) level to calculate the variance between the budget entry and all the transaction actuals. The variance will be calculated if either the budget or the transaction's actual amounts change.
Rule.formula(derive=models.Budget.variance_amount,
as_expression=lambda row: row.actual_amount - row.amount)
Rule.formula(derive=models.CategoryTotal.variance_amount,
as_expression=lambda row: row.actual_amount - row.budget_total)
Rule.formula(derive=models.MonthTotal.variance_amount,
as_expression=lambda row: row.actual_amount - row.budget_total)
Rule.formula(derive=models.YrTotal.variance_amount,
as_expression=lambda row: row.actual_amount - row.budget_total)Testing
The OpenAPI (Swagger) endpoint generates CURL command to test inserting Budget and Transaction entries. Using the react-admin UI to view the YrTotal endpoint to see if the aggregation group-by worked correctly. There are some Behave (TDD) tests that do the same thing. The Open API will generate both a URL and a CURL entry for the API developers and for testing locally. Below is the react-admin UI showing the YrTotal budget, actual, and variance amounts.
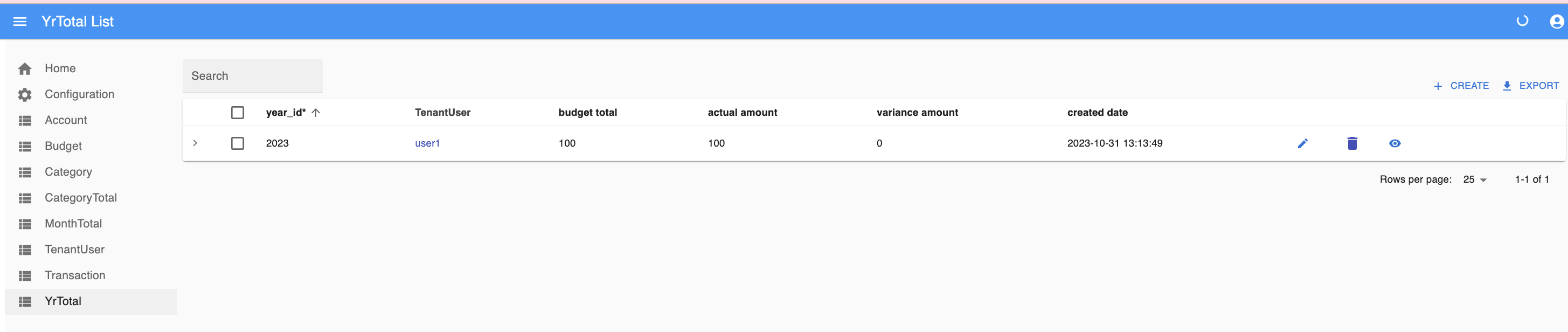
Example CURL command to post a budget entry:
$curl -X 'POST' \ 'http://localhost:5656/api/budget' \
-H 'accept: application/vnd.api+json' \
-H 'Content-Type: application/json' \
-d '{ "meta":
"data": {
"attributes": {
"year_id": 2023,
"month_id": 1,
"user_id": 1,
"category_id": 1,
"description": "Budget Test",
"amount": amount,
},
"type": "Budget"
}
}'Tracing the Rules
The VSCode debug window shows a detailed list of the rules that fired and the rule execution order. More detailed information is available in the logs. Like a spreadsheet, as data value changes are made, the runtime LogicBank will fire the rules in the correct order to adjust the sums, counts, constraints, events, and formulas for months, categories, and year totals.

Docker Container
The DevOps folder in the API Logic Server has several subfolders to build and deploy this project as a docker container (and an optional NGINX container) locally or to the cloud. This allows me to quickly deploy my application to the cloud for testing and immediate user feedback.
Summary
Using the open-source API Logic Server with SQLAlchemy, Flask, safs/JSON API, and LogicBank to simulate the spreadsheet rules requires thinking of data as SQL Tables and applying rules accordingly to do the automated group-bys for sums and counts on CategoryTotal for each category, MonthTotal for each column by category, and YrTotal to sum all budget expenses. This is a multi-tenant secure cloud-based application built in a day using ChatGPT and automated microservice generation with declarative, spreadsheet-like rules. The ability to write a custom endpoint to bring back all the budget, category, month, and year totals in a single endpoint gives us, the UI developer, a complete spreadsheet functionality.
API Logic Server provides automation for iterative building and deployment of a REST API microservice with declarative logic and security. These declarative rules help turn any SQL database into a spreadsheet.
Opinions expressed by DZone contributors are their own.
Comments