Running Microservices on Top of In-Memory Data Grid: Part I
With this post, we start a series that will provide a guide on building a fault-tolerant, scalable, microservice-based solution with Apache Ignite In-Memory Data Fabric.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Nowadays, many companies are basing their applications and solutions on microservices architecture. One of the main benefits of this approach is that it allows splitting a solution into a number of loosely coupled software components (microservices). These software components might have their own release and life cycles and even their own development teams. Moreover, these software blocks might even be developed and maintained using different languages and technologies. However, since all of the microservices are intended to be a part of something bigger (the application or solution), they always have at least one mechanism for interacting and exchanging data with each other.
At the same time, microservice-based solutions that are used under high load or have to process rapidly growing volumes of data usually face the same issues and difficulties as the applications and solutions that are not microservices-based.
- Disk-backed databases can no longer keep up with growing volumes of data that have to be stored and processed in parallel. Databases are becoming a performance bottleneck affecting the overall solution or application.
- Times when a solution's high-availability guarantee was a nice feature to have are becoming a thing of the past. Today, high-availability of an application is becoming a de-facto requirement.
With this post, we start a series of articles that will provide a step-by-step guide on how to build a fault-tolerant and scalable microservice-based solution using Apache Ignite In-Memory Data Fabric.
Microservice-Based Solution With Apache Ignite
The picture below depicts the main building blocks of the overall solution. Let's go through them one-by-one defining their roles.
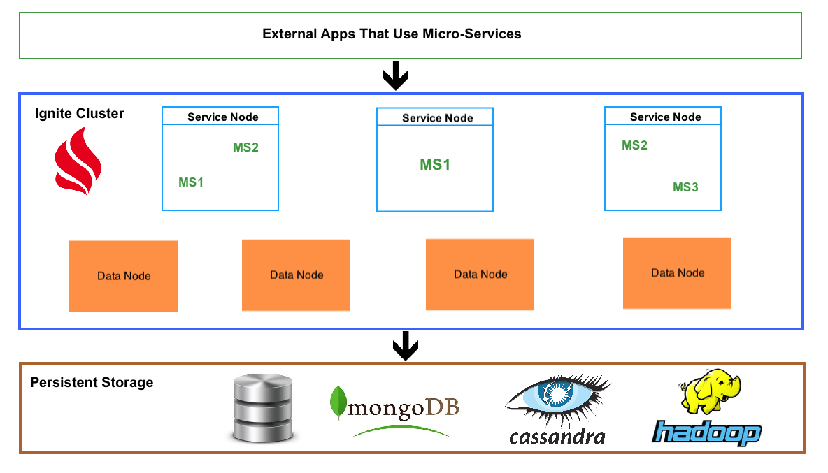
Figure 1
Ignite Cluster Layer
The cluster serves a dual purpose.
Firstly, it is the main data storage that holds a dataset directly in memory. Since the data is located much closer to the CPU, a microservice doesn't need to go to disk all the time to get the data from there. This significantly improves overall performance. A special group of cluster nodes (data nodes) is dedicated to this first purpose.
A data node is an Ignite server node that holds a portion of the dataset and enables execution of queries and computations. Moreover, a data node doesn't require the deployment of supporting classes of model objects and computations thanks to its reliance on binary formatting. Binary formatting is used for object serialization and to enable a peer-class-loading mechanism that helps manage computation classes pre-loading from nodes that incorporate application logic (service nodes).
Secondly, the cluster manages microservice lifecycle and equips microservices with all the APIs they need to communicate with each other and with data nodes. To achieve this, an Ignite cluster-based solution includes the aforementioned service nodes. These are the nodes where microservices will be deployed and application logic will be executed. A service node can host one or more microservices depending on your solution and workload details. Each microservice implements Apache Ignite Service interface which makes it inherently fault-tolerant and provides an easy way to call one microservice from another.
Ignite takes care of deploying one or many copies of a microservice on a range of service nodes while also automatically handling load balancing and fault-tolerance. In Figure 1 above, this kind of microservices is named MS<N> (MS1, MS2, etc.). The benefit of spreading the workload across multiple service and data nodes is that you do not need to restart the whole cluster if microservice MS1 has to be changed. All that is required is to update MS1 classes on the service nodes where the microservice is deployed so only a subset of the nodes needs to be restarted.
All the nodes (service and data) are interconnected, which allows MS1 deployed on one service node communicate with any other microservice deployed on another (or the same) service node and get and send data and computations to any of data nodes.
Persistent Storage Layer
This layer is optional and can be used for scenarios in which:
- It is not feasible or relevant to hold all the data in memory.
- One requires the ability to recover the data set from a disk-based copy in the event the whole cluster goes down or needs to be restarted.
To enable the persistent storage layer, you simply need to provide Apache Ignite data grid with a CacheStore implementation. Among default implementation, you can find RDBMS, MongoDB, and Cassandra.
Layer Used by External Applications
These are "users" of your microservice-based architecture. Basically, this is the layer that triggers a variety of execution flows by calling one microservice or another.
This layer can talk to your microservices using an external protocol specific to each microservice (while internally, microservices communicate with each other through Apache Ignite Services) or connect to them using Apache Ignite client connections. There is considerable flexibility and a diversity of options in this area.
To Be Continued
The discussed architecture makes it possible to scale out horizontally, storing datasets in memory and enabling microservices with high-availability characteristics. In the upcoming blog posts, we will show examples of how to implement this approach. Stay tuned.
Published at DZone with permission of Denis Magda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments