The Hidden Risk of SaaS-Based AI: You’re Training Models You Don’t Control
SaaS-based AI centralizes learning outside your organization. Each API call may improve shared models, shifting control and competitive leverage away from the data owner.
Join the DZone community and get the full member experience.
Join For FreeEvery time your organization calls a SaaS AI API, you may be strengthening a model your competitor also benefits from. The more you use it, the more you pay to improve infrastructure you do not own — and may never control.
Architectural Inversion
SaaS-based AI doesn’t just introduce risk; it fundamentally inverts the traditional enterprise model. Instead of building internal capability, organizations now pay to improve external models. The learning power — the ability to generalize, adapt, and optimize — is centralized away from the data owner. You’re not just losing privacy; you’re losing leverage.
SaaS-Based AI: How It Works
SaaS AI platforms offer APIs for tasks like image recognition, NLP, or analytics. When you send data, the provider’s model processes it and often uses your data to retrain and improve itself. This creates a feedback loop: 
SaaS AI Data Flow
Consider two companies in financial services:
- Company A sends 10,000 labeled fraud transactions to a SaaS AI provider.
- Company B sends 8,000 similar patterns.
The provider’s unified model now generalizes across both datasets. Company A’s proprietary fraud detection patterns are now part of a model that Company B can benefit from — and vice versa. The risk is tangible: Your competitive edge becomes communal, and you have no control over how your data is used or who else benefits.
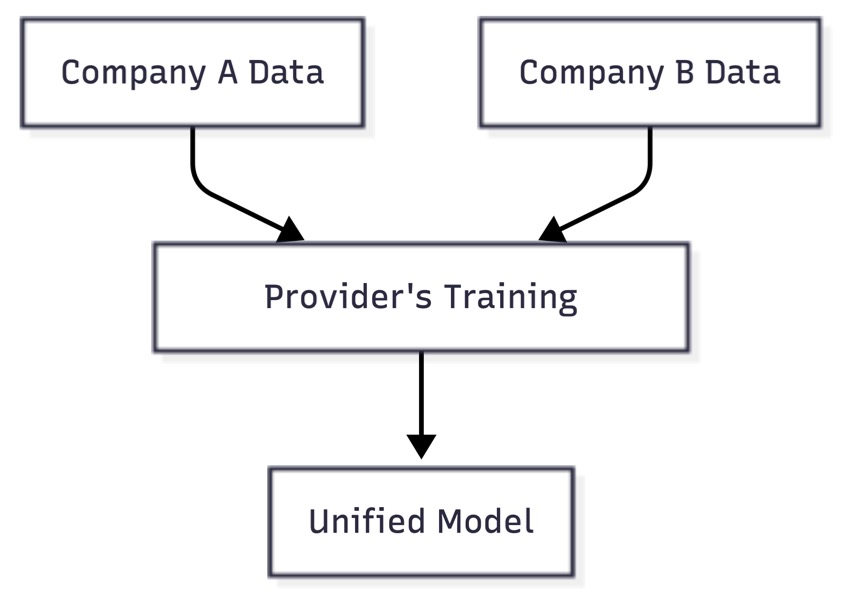
Shared Model Training
Multiple companies’ data streams feed into a single provider’s model training pipeline, resulting in a unified model that benefits from all inputs.
Real-World Examples
1. Healthcare Diagnostics
A hospital uses a SaaS-based AI tool to analyze medical images for cancer detection. Over time, the tool’s accuracy improves, but the hospital cannot verify whether its proprietary patient data is being used to train the model for other clients, potentially violating patient privacy laws. Worse, if a competitor hospital uses the same SaaS tool, they may benefit from the first hospital’s rare-case data, gaining diagnostic accuracy without contributing their own edge cases.
2. Retail Demand Forecasting
A large retailer integrates a SaaS AI for demand forecasting. The model is retrained regularly with data from all clients. One day, the model starts overestimating demand for a specific product category. Investigation reveals that a competitor’s promotional campaign, included in the shared training data, skewed the model’s predictions for everyone. The retailer’s inventory costs spike, and the root cause is buried in the provider’s opaque model update process.
3. SaaS AI and Language Models
Many SaaS AI providers now offer language models (e.g., for customer support chatbots) that learn from user interactions. If your company’s support logs are used to fine-tune the provider’s base model, your unique customer phrasing, product issues, and even internal jargon can become part of the model’s general knowledge. This means a competitor using the same provider could see their chatbot suddenly “understand” your product’s terminology or troubleshooting steps.
How Model Updates and Fine-Tuning Pipelines Work
Most SaaS AI providers operate on a continuous learning loop. When you submit data, it may be used in several ways:
- Batch retraining: Your data is added to a growing corpus, and the model is periodically retrained on the entire dataset.
- Online learning: The model is updated incrementally as new data arrives, allowing it to adapt in near real-time.
- Fine-tuning pipelines: For some services, your data is used to fine-tune a base model, which is then merged back into the main model or used to update weights globally.
In all cases, the provider’s infrastructure is designed to maximize the value of every data point — not just for you, but for the entire customer base. This is especially true for embedding-based systems, where your data helps shape the vector space that all users rely on.
Embedding-Based Systems
Modern AI platforms often use embeddings — high-dimensional representations of data — to power search, recommendations, and classification. When your data is ingested, it influences the structure of this embedding space. As a result, the “knowledge” your organization provides is woven into the very fabric of the model, making it nearly impossible to disentangle or reclaim.
Architectural Implications: Loss of Leverage
- Centralized learning power: The provider, not the client, controls the model’s evolution.
- Opaque abstraction: You cannot audit, roll back, or customize the model’s behavior.
- Vendor leverage: The provider can change pricing, access, or model logic at any time.
This isn’t just a privacy issue — it’s a structural shift in how enterprise systems gain and lose leverage.
Compliance: Still Relevant, Less Central
Regulatory concerns (GDPR, HIPAA) remain important, but for engineers and architects, the bigger issue is architectural control. You can’t guarantee data residency, audit trails, or deletion — but more critically, you can’t guarantee that your data isn’t being used to train models for others.
Unintended Model Behavior
- Model drift: Unified models retrained on diverse data can change unpredictably.
- Bias introduction: Patterns from one client can introduce bias for another.
- No rollback: If a new model version degrades performance, you can’t revert.
Mitigation Strategies: Architectural, Not Just Procedural
- Demand transparency: Know how your data is used, but recognize that transparency is not control.
- Private or on-prem AI: Retain learning power by running models internally.
- Trade-off: Higher operational cost, more responsibility for security and maintenance, but full control over model evolution and data usage.
- Federated learning: Prefer architectures where only model updates, not raw data, are shared.
- Nuance: Federated learning is not trivial — it requires robust coordination, secure aggregation, and careful handling of model updates to avoid leaking sensitive information through gradients or updates.
- When SaaS AI is justified: For non-core workloads, rapid prototyping, or when the value of shared learning outweighs the risk, SaaS AI can still be the right choice. The key is to be intentional about where and how you cede learning power.
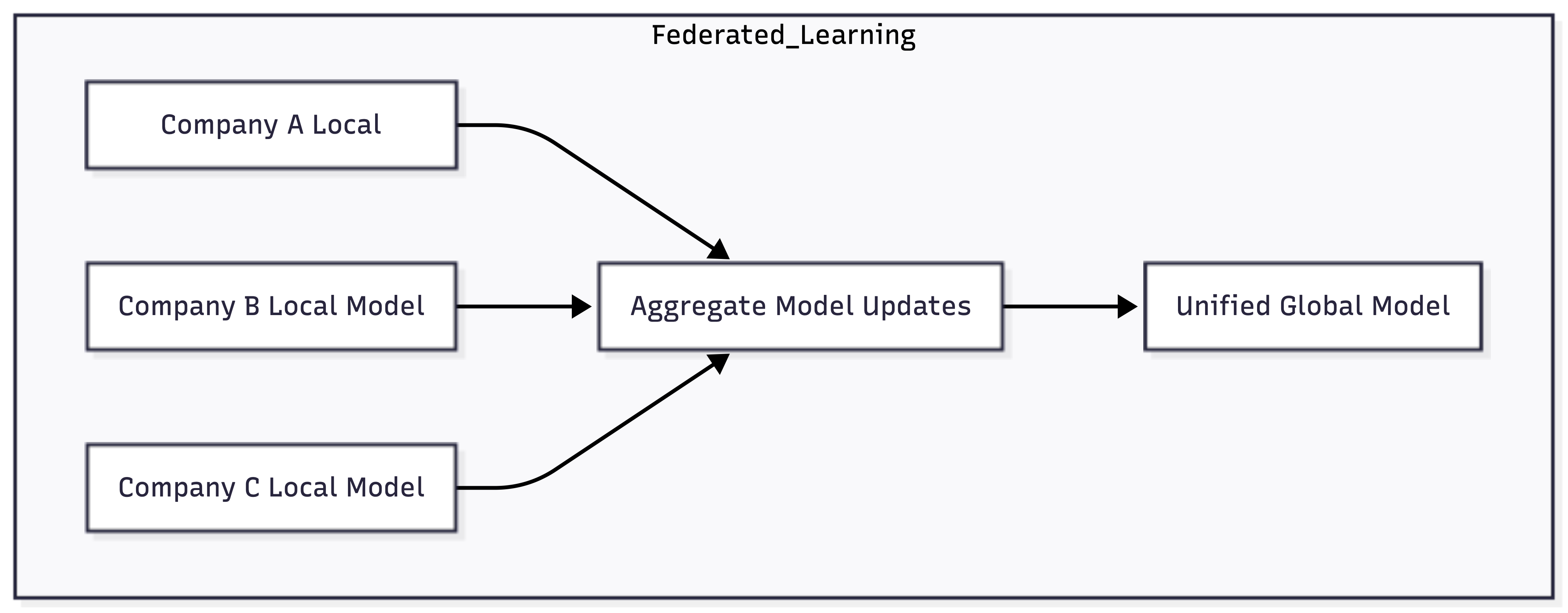
Federated Learning vs. Centralized Training
Each company trains a model locally; only model updates are aggregated, not raw data.
Future Directions: What to Ask Your Vendor
- Can you opt out of data sharing for model improvement?
- Is your data used to train models for other clients?
- Can you audit or export your data and model contributions?
- What is the provider’s policy on model versioning and rollback?
- Are there technical guarantees for data isolation in embedding spaces?
Structural Impact
AI adoption is not just a tooling decision — it is an architectural decision about where learning power resides. The real risk is not just privacy or compliance, but the loss of leverage and control over the systems that define your competitive advantage.
The organizations that control where learning happens will define the next competitive era.
Opinions expressed by DZone contributors are their own.
Comments