See What's New in Neo4j 4.0
Join the DZone community and get the full member experience.
Join For FreeIf you’re not directly plugged in to Neo4j-specific news, you may not have seen the recent splash of all-new features in Neo4j’s latest database version release. Or, perhaps you saw it but it wasn’t clear how it could benefit or help you in the work that you are doing.
This is an exciting release, most of which is based around the evolution of the Neo4j database into a full database management system (DBMS)! There are a variety of new features that go along with this development and assist users and teams in managing multiple graphs.
With this post, I want to dive head first and highlight the technical details with applicable examples to help determine how to use the features and what this means for you as a developer. Without further ado, let’s get started!
Multidatabase
With Neo4j now, you can create and use more than one active database at the same time. This works in standalone and causal cluster scenarios and provides the ability to maintain multiple, separate graphs in one installation.
The graph DBMS automatically creates a system database and a default database. The system database is named system and contains the overall system information that applies across databases - managing administration of individual databases (stopping and starting) and maintaining user privileges (security roles and privileges). The default database is named neo4j (can be changed) and is where you can store and query graph data and integrate with other applications and tools. Other databases can be added and removed as needed based on data needs.
Many relational and other databases also have this ability to segregate domains by database in a single system. This can be extremely valuable for scenarios where we want to store disparate data sets/domains in the same DBMS. For instance, HR information could be divided into databases for employee data, payroll data, tax form data, etc.
As a brief walkthrough example, let us suppose you have a relatively small business and want to take advantage of the connectedness of graph data for a couple of different use cases - an organization hierarchy and a support ticket system for helping customers with your products/services. They are completely separate areas of the business, but you do not need separate instances of Neo4j in order to manage both use cases.
You can install Neo4j and start up the database, where it will create a system database for managing the system and administration information and a default data instance (neo4j). In the default database, we can import our organizational hierarchy data and manage any labels, constraints, and queries that go along with that domain. For our support ticket system, we can create a new database (we will call it support-tickets) and import/load the relevant data there to handle those domain-specific needs.
You can manage sizes and optimizations for both databases from the system database and also switch between the two data instances for queries by using some Cypher administrative commands.
Resources for operating multiple databases in Neo4j include a developer guide tutorial, reference information in the documentation, and administrative commands in the Cypher manual. Other helpful information for blogs and videos is listed in the 4.0 resources list.
Unlimited Scaling
Neo4j has implemented a graph sharding approach called Fabric to support distributing data across instances or systems. It provides the capability of both accessing data in separate graphs, as well as a connected graph stretched across multiple partitions/databases. We can query across this graph data with a single Cypher statement for returning or altering data in one or more distributed stores.
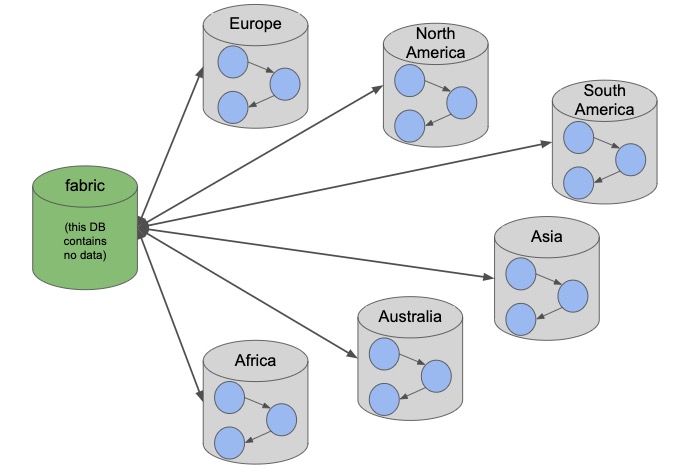
Neo4j sharding contains a fabric database, which serves as the entrypoint to the rest of the databases and data. This particular database only manages the external interface, so it does not store data or hold other information. Any other partitions involved (fabric graphs) can hold and store data to be accessed from client applications or other instances. Remember that multidatabase is also now a part of 4.0, so fabric graphs can be local (within the same DBMS) or remote (external DBMSs). Sharding combined with multi-database can provide solutions for multi-tenancy and data separation/privacy business cases.
Some NoSQL databases offer some concept of sharding (horizontal scaling), though sharding in the graph world is bit different with equal importance given to entities and relationships. Splitting data across partitions can be very helpful for dividing very, very large datasets, as well as segmenting pieces of the graph for processing queries against those individual segments. It allows you to query the shard by itself for narrower queries or knit the shards together for broader queries.
As an example, let us go back to our organization hierarchy and support ticket use cases from before and focus on sharding with the support ticket system, as it is likely to be the more expansive of the two data sets. The data model for this domain might look something like the one below.
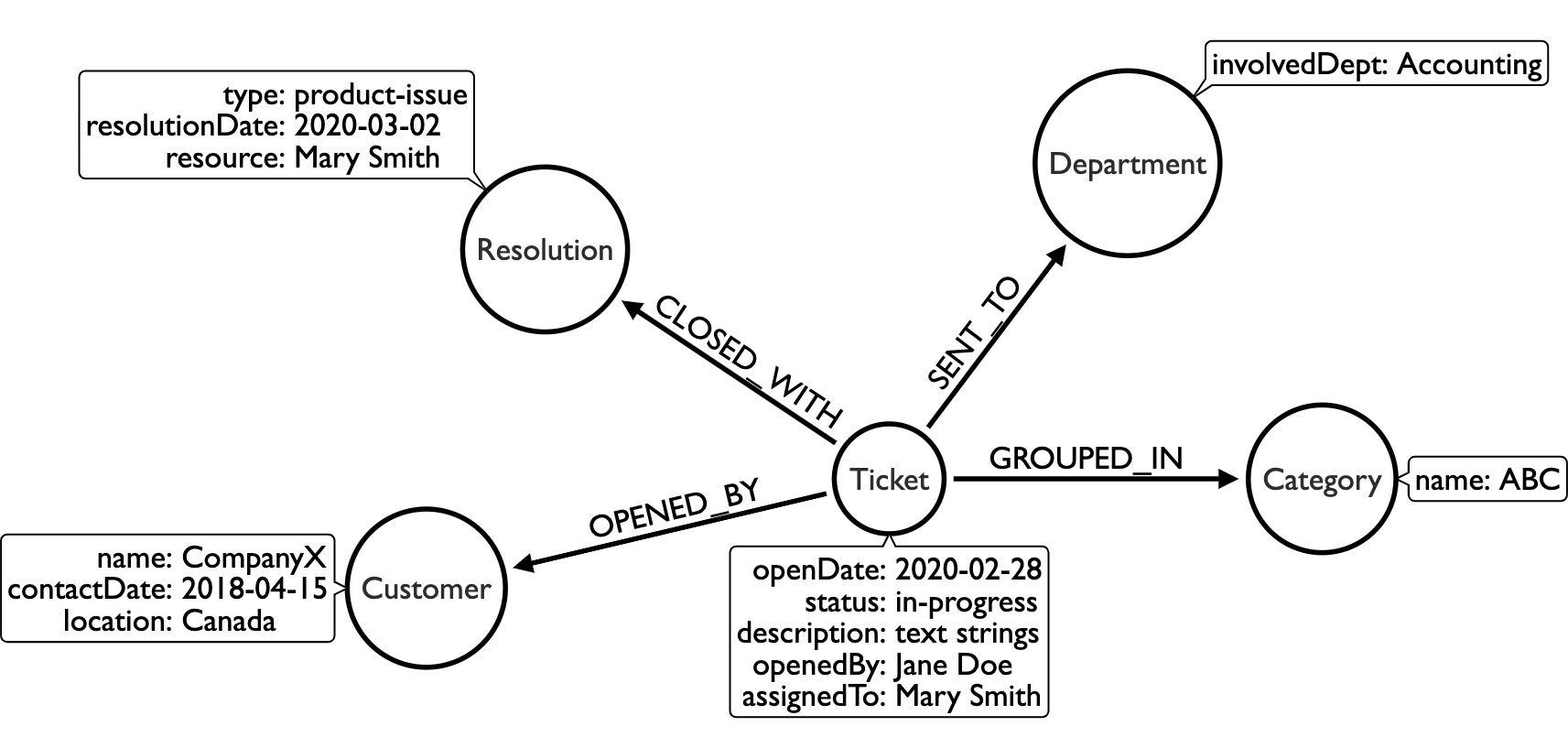
We could separate this into shards based on common query needs. For instance, departments might want to look at tickets assigned to them on a regular basis to work on them. The Ticket, Department, and Category nodes can be put in a shard for those types of queries. An operations team might want to analyze the amount of tickets coming in and how they were resolved (common issues, time to ticket closure, certain problem categories), segmenting the Ticket, Category, and Resolution data into another shard.
Finally, an account manager could want to track customer issues to find those customers using most resources, requiring additional training or services, or inactivity. The Ticket and Customer information could go into another shard. Monthly or annual reporting at higher levels may weave all of these shards together, giving leadership an overall picture of how teams are doing and what improvements might be needed through the organization.
Resources for Neo4j sharding include a developer guide on concepts with an example and reference information in the documentation. Other helpful blogs and videos are listed in the 4.0 resources list.
Reactive Drivers
This version of Neo4j has incorporated the principles of the reactive manifesto in passing data between the database and clients using the drivers. Developers can take advantage of the reactive approach to process queries and return results. This means that communication between the driver and the database can be managed and adjusted dynamically according to data needs of the client.
Reactive programming principles allow the consuming side (applications, other systems, etc) to specify the amount of data received within a certain window of time. The driver for Neo4j will also maintain rate limits for requesting data from the server, providing flow control throughout the entire Neo4j stack.
No matter the volume of transactions or data coming from the database (even during times of high activity), the system can maintain limits on how much it can send and receive at once based on available resources. This prevents overloads and collapses or failures, as well as lost transmissions or later catch up loads during the downtime.
We can go back to our support ticket system example. Perhaps we see volumes of 2 tickets one minute and 8 tickets the next minute, but our client application can only process 2 at a time. We could set limits to retrieve only 2 at a time. That way, our application can handle the load without toppling over and causing further processing backlog.
An example of using a transaction function to reactively retrieve tickets in the database is shown in Java below.
xxxxxxxxxx
public Flux<ResultSummary> printAllTickets()
{
String query = "MATCH (t:Ticket) WHERE t.id = $id RETURN t.description";
Map<String,Object> parameters = Collections.singletonMap( "id", 0 );
return Flux.usingWhen( Mono.fromSupplier( driver::rxSession ),
session -> session.readTransaction( tx -> {
RxResult result = tx.run( query, parameters );
return Flux.from( result.records() )
.doOnNext( record -> System.out.println( record.get( 0 ).asString() ) ).then( Mono.from( result.consume() ) );
}
), RxSession::close );
}
More details about Neo4j’s reactive drivers and how they work is documented in the driver manual. Reactive processing with Neo4j is also available in integration libraries such as Spring Data Neo4j (SDN-RX), Micronaut, and others. There is a video for SDN-RX and a blog post for general driver updates. Other examples and content are assembled in the resources post.
Security
Security in Neo4j offers granular controls for more specific user-based access. There is a new fine-grained security model that is based on database schema (labels, relationship types, and properties) privileges that operates alongside improved role-based security policies.
With only role-based security, users can limit read or write access, but don’t have as much fine-tuned control over paths or properties within the graph. The schema-based addition grants control for users to read, write, or pass through (traverse) sensitive entities, as well as grant or deny access to data on specific nodes and relationships (such as SSN, birthdate, medical diagnoses, etc). This is handled by the ability to segment general roles into separate privileges, specifying the segments allowed, and determining any properties that can or cannot be viewed by an individual.
We can go back to our example use case and apply some of these security privileges to it. For instance, in our ticket system, we might have an operations associate (david), a salesperson (priya), and an IT administrator (janet) who need access to the system. Each person should be able to access certain things and be restricted from accessing other things. Here are our criteria:
David, the ops associate: should be able to view all the tickets and resolutions, but should be restricted from seeing specific customer information
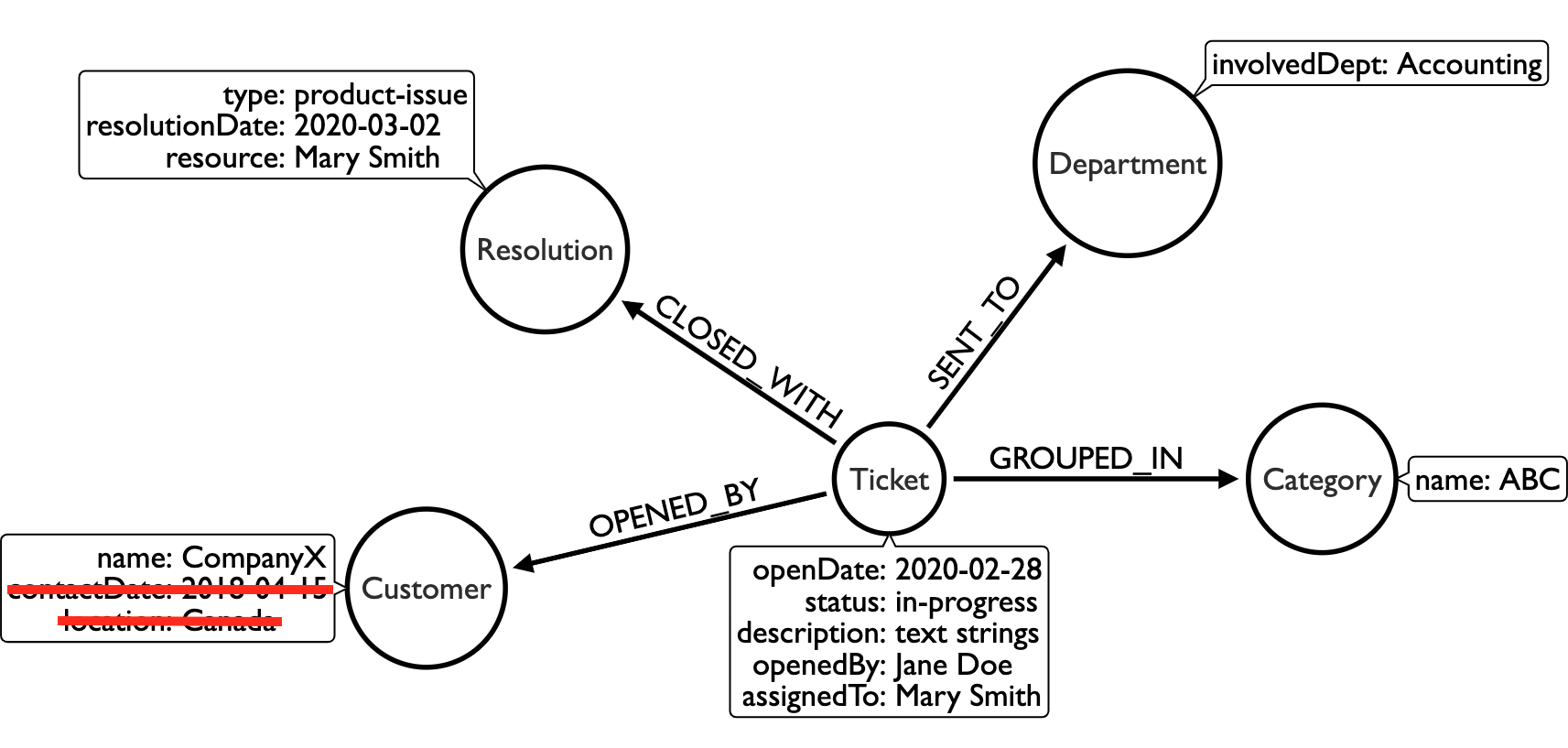
Here is David’s security setup:
xxxxxxxxxx
CREATE ROLE operations;
GRANT ACCESS ON DATABASE support-tickets TO operations;
// We allow the ops associate to find all nodes
GRANT TRAVERSE ON GRAPH support-tickets NODES * TO operations;
// Allow the ops associate to find all relationships
GRANT TRAVERSE ON GRAPH support-tickets RELATIONSHIPS CLOSED_WITH, SENT_TO, GROUPED_IN, OPENED_BY TO operations;
// Allow reading of all properties on relevant nodes
GRANT READ {*} ON GRAPH support-tickets NODES Category, Department, Resolution, Ticket TO operations;
// Only allow reading Customer name property
GRANT READ {name} ON GRAPH support-tickets NODES Customer TO operations;
GRANT ROLE operations TO david;
Priya, the salesperson: should be able to view all customer information for her role, but should be restricted from seeing many of the ticket details, everything on a resolution, and nothing for department and category
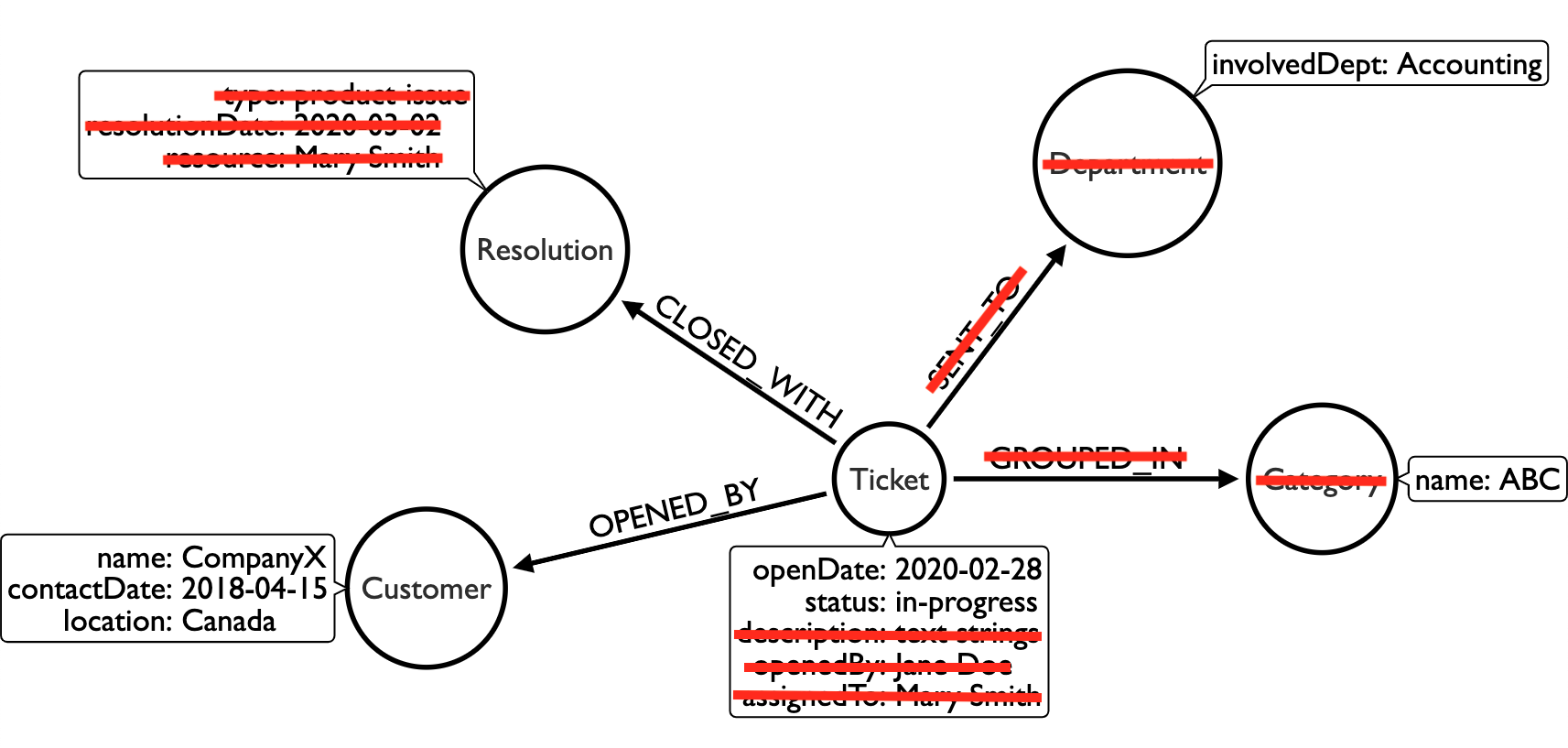
Here is Priya’s security setup:
xxxxxxxxxx
CREATE ROLE sales;
GRANT ACCESS ON DATABASE support-tickets TO sales;
// We allow the salesperson to find all nodes
GRANT TRAVERSE ON GRAPH support-tickets NODES Customer, Ticket, Resolution TO sales;
// Now only allow the researcher to find certain relationships
GRANT TRAVERSE ON GRAPH support-tickets RELATIONSHIPS CLOSED_WITH, OPENED_BY TO sales;
// Allow reading of all properties on relevant nodes
GRANT READ {*} ON GRAPH support-tickets NODES Customer TO sales;
// Only allow reading Ticket openDate, status properties
GRANT READ {openDate, status} ON GRAPH support-tickets NODES Ticket TO sales;
GRANT ROLE sales TO priya;
Janet, the IT administrator: should be able to see nearly everything, since she handles privileges and access for employees, but we should restrict some customer information
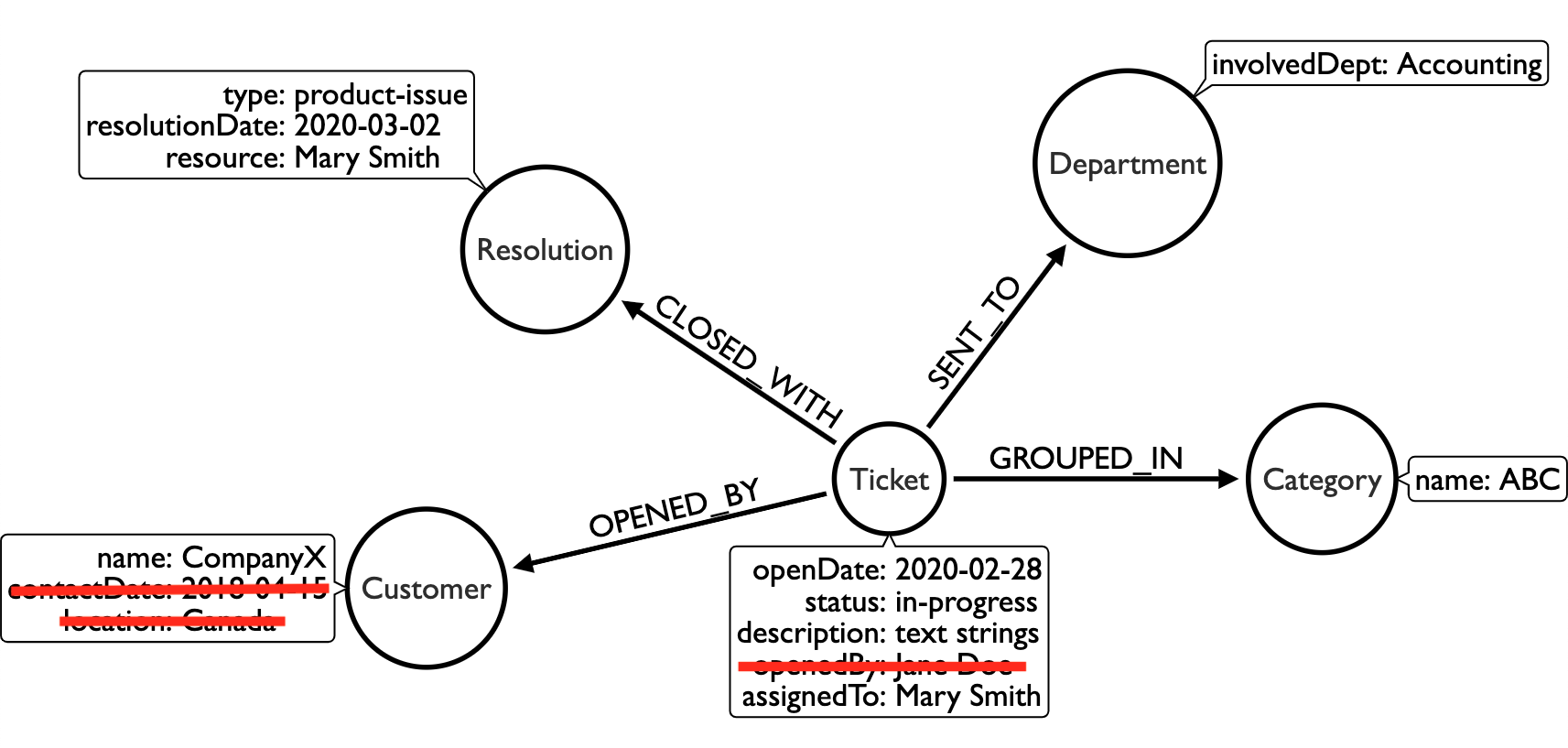
Here is Janet’s security setup:
xxxxxxxxxx
CREATE ROLE itadmin;
GRANT ACCESS ON DATABASE support-tickets TO itadmin;
// Allow itadmins to traverse, read, and write everything
GRANT TRAVERSE ON GRAPH support-tickets TO itadmin;
GRANT READ {*} ON GRAPH support-tickets TO itadmin;
GRANT WRITE ON GRAPH support-tickets TO itadmin;
// Deny reading specific customer details on Customer and Ticket nodes
DENY READ {contactDate, location} ON GRAPH support-tickets NODES Customer TO itadmin;
DENY READ {openedBy} ON GRAPH support-tickets NODES Ticket TO itadmin;
A video covering these Neo4j security features provides more details, as well as the reference material in the documentation.
And Much, Much More!
The list above contains only the most significant features to impact developers, but there are several other additions, as well. From expanded capabilities for subqueries in Cypher to a consistent, simplified routing scheme, there is so much to benefit a developer’s daily work. Check out all the features, fixes, and other inclusions for this release that can be reviewed in detail from our Neo4j documentation.
What Are You Waiting For?!
Feeling excited to try or upgrade to the new Neo4j and get knee-deep in the code? For immediate and free access, download the Neo4j Desktop release with 4.0 included for your operating system. It includes Enterprise edition via a developer license.

It's also available for servers in both Enterprise and Community editions. Enterprise edition is accessible via a commercial license on servers for Linux, Mac, or Windows, as well as through repositories with yum, Debian/Ubuntu, and Docker. You can also access 4.0 server for free via Community edition as an open source license.

Feedback and Questions
As always, Neo4j welcomes feedback on any issues, bugs, features, and concerns/comments! Don’t hesitate to reach out to through available channels and contribute back. To provide feedback, contact Neo4j in one of these ways:
Customers: Submit issues or ask for help through your regular channels, such as the customer support portal. For sensitive data or use cases, this is the best way to retain confidentiality and get things solved.
Developers and technical users: Submit issues through our GitHub public repository and please be sure to specify the version.
Everyone: If you have ideas to share, comments or more generic questions, we encourage you to use our Neo4j Community site in the 4.0 topic.
Happy exploring!
Opinions expressed by DZone contributors are their own.
Comments