Semantic Contracts: The Missing Layer Between Good Data and Reliable AI
Semantic contracts prevent silent data and AI failures by enforcing shared data meaning and assumptions across pipelines in CI and at runtime.
Join the DZone community and get the full member experience.
Join For FreeModern data platforms are objectively better than they were five years ago.
Schemas are versioned. Pipelines are tested. Data quality checks catch nulls, range violations, and anomalies. Lineage is tracked. Observability dashboards exist.
And yet, organizations deploying LLM-powered analytics, copilots, and agent-driven workflows are encountering a new and unsettling class of failures. These failures do not trigger alerts, break dashboards, or violate schemas.
The data is technically correct.
The pipelines are operationally healthy.
The AI responses are confident, articulate, and wrong.
This is not a tooling failure.
It is a semantic failure.
In this article, we argue that modern data stacks are missing a critical layer called semantic contracts. Semantic contracts are explicit, executable definitions of meaning that sit between clean data and AI consumption. We will explore why this layer is now essential, how semantic drift silently undermines AI systems, and how data engineers can design and enforce semantic contracts without rewriting their entire platform.
The New Failure Mode: When Data Is Correct but Meaning Is Not
Consider a dataset with the following column:
active_customer BOOLEANThe column exists.
The data type is correct.
Null checks pass.
Cardinality looks reasonable.
Historical trends are stable.
From a traditional data engineering perspective, this column appears healthy.
But what does active mean?
Depending on the team and the business context, it could mean any of the following:
- Logged in during the last 30 days
- Completed a purchase in the last 90 days
- Has a paid subscription that has not expired
- Has not been soft deleted
- Has interacted with customer support recently
Each definition is plausible.
Each definition has been used in real production systems.
Each definition produces materially different answers.
Now imagine a seemingly harmless change: a product team updates the definition from logged in within 30 days to completed a purchase within 90 days. The schema does not change. Data quality checks still pass. Dashboards continue to render.
An LLM answering the question
“How many active customers do we have this quarter?”will confidently respond using the new meaning, even if downstream systems, executive reporting, or historical comparisons implicitly assume the old one.
No exception is raised.
No alert fires.
No one notices — until trust erodes.
Why This Problem Barely Existed Before AI
Before AI-driven analytics, semantic drift was largely mitigated by humans.
Analysts questioned unexpected numbers.
Business stakeholders asked follow-up questions.
Engineers noticed discrepancies during reviews.
Institutional knowledge filled the gaps.
LLMs remove those human friction points entirely.
They do not question definitions.
They do not notice subtle shifts in meaning.
They do not ask whether a metric changed recently.
Instead, they assume consistency, infer relationships, and generate persuasive narratives.
This makes semantic drift exponentially more dangerous in AI systems than in traditional business intelligence workflows.
The Hidden Assumption in Modern Data Platforms
Most modern data architectures implicitly assume the following:
If the schema is stable and the data is valid, then the meaning is stable.
That assumption is no longer safe.
Schemas protect structure.
Data quality checks protect values.
Neither protects intent.
Semantic contracts exist to make intent explicit, versioned, and enforceable.
What Exactly Is a Semantic Contract?
A semantic contract is a machine-readable specification that defines:
- What a dataset or field means
- The business rules that give it meaning
- The assumptions under which that meaning is valid
- The conditions under which downstream usage is unsafe
Unlike documentation, semantic contracts are designed to be validated automatically, enforced in CI and at runtime, and consumed by both humans and machines.
Semantic Contracts Versus Existing Controls
| Control Layer | Primary Focus | Failure It Prevents |
|---|---|---|
| Schema contracts | Structure | Missing or renamed fields |
| Data quality checks | Validity | Bad or malformed values |
| Lineage | Dependency tracking | Hidden upstream changes |
| Semantic contracts | Meaning | Silent interpretation drift |
A Concrete Semantic Contract Example
Below is a practical semantic contract expressed in YAML. It is intentionally simple but powerful enough to prevent real-world failures.
dataset: customer_profile
semantic_version: 1.2
fields:
active_customer:
definition: >
A customer is considered active if they have completed
at least one successful transaction within the last 90 days.
source_of_truth:
table: transactions
condition: status = 'SUCCESS'
window_days: 90
exclusions:
- soft_deleted = true
- subscription_only = true
assumptions:
timezone: UTC
late_arrival_tolerance_days: 3
backfill_behavior: recompute
ai_usage:
approved:
- churn_analysis
- quarterly_reporting
forbidden:
- real_time_decisioning
- fraud_detection
This contract captures meaning, scope, and constraints rather than just structure.
Where Semantic Contracts Fit Architecturally
Semantic contracts should be treated as first-class pipeline artifacts, not comments or wiki pages.
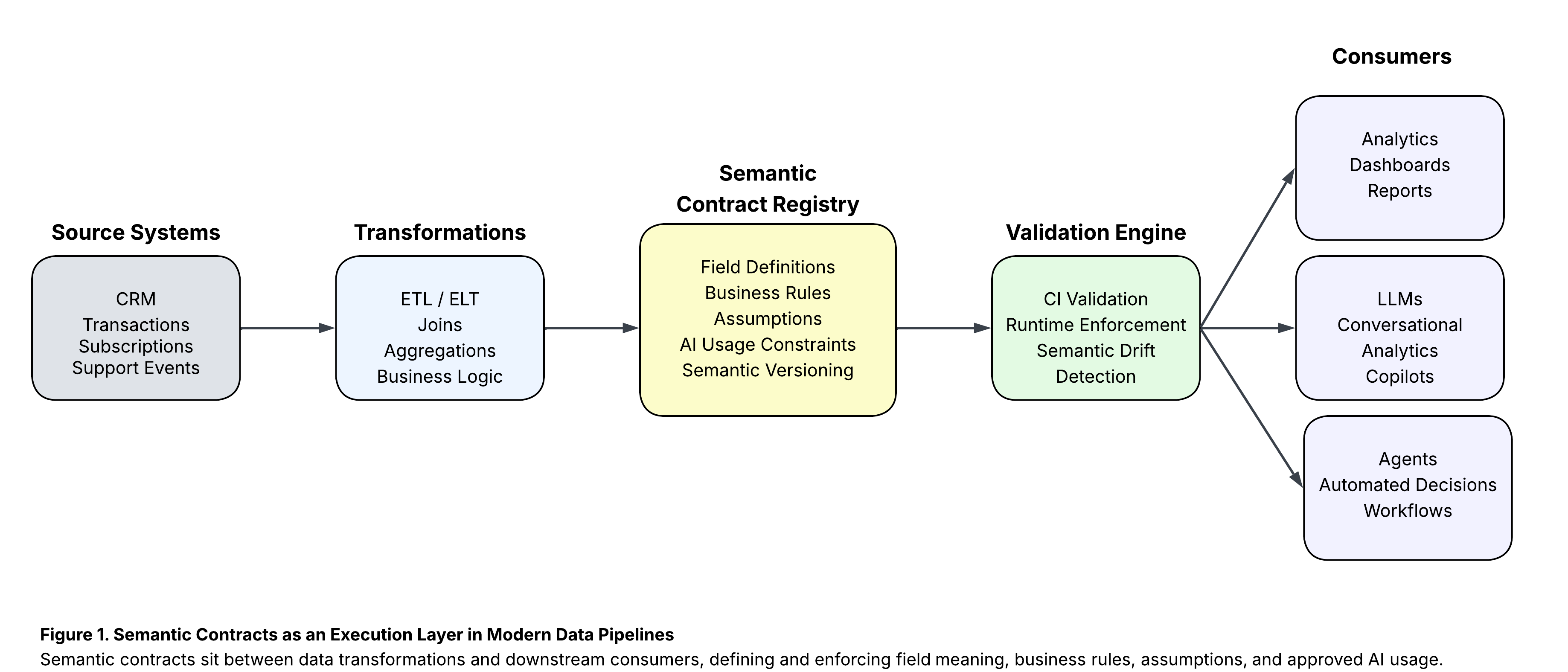
Key Design Principles
- Contracts are versioned independently of schemas
- Semantic changes require explicit acknowledgment
- AI usage is gated by semantic compatibility
- Violations fail fast before data is consumed
Enforcing Semantic Contracts in Data Pipelines
Semantic contracts only matter if they can stop bad data from propagating.
Step 1: Load and Parse the Contract
import yaml
with open("customer_profile.semantic.yaml") as f:
contract = yaml.safe_load(f)
Step 2: Validate Business Semantics, Not Just Values
Example: ensure that active_customer aligns with transaction history.
def validate_active_customer(customers, transactions, contract):
window = contract["fields"]["active_customer"]["window_days"]
qualifying_tx = transactions[
(transactions["status"] == "SUCCESS") &
(transactions["transaction_date"] >= current_date() - window)
]
expected_active_ids = set(qualifying_tx["customer_id"])
actual_active_ids = set(
customers[customers["active_customer"]]["customer_id"]
)
violations = actual_active_ids - expected_active_ids
if violations:
raise Exception(
f"Semantic violation: {len(violations)} customers marked active "
f"without qualifying transactions"
)
This validation would never be caught by schema or data quality checks.
Semantic Contracts in CI and CD
Semantic drift should be treated as a breaking change.
CI Rules That Matter
- Any change to
definition,window_days, orexclusionsrequires a semantic version bump - Downstream approval is required
- Cached AI embeddings or summaries must be invalidated
if semantic_definition_changed and not semantic_version_incremented:
raise Exception(
"Semantic definition changed without version bump"
)
This prevents the most common failure pattern:
We changed the logic but forgot to tell anyone.
Runtime Enforcement for AI Systems
Semantic contracts should also protect AI inference paths.
Before an LLM answers a question:
- Identify the dataset used
- Read its semantic contract
- Verify the requested use case is approved
- Reject or constrain responses if incompatible
def validate_ai_usage(contract, requested_use_case):
if requested_use_case not in contract["ai_usage"]["approved"]:
raise Exception(
f"Dataset not approved for AI use case: {requested_use_case}"
)
This turns governance from static policy documents into executable control.
Common Semantic Failure Patterns Seen in Production
- Metric reinterpretation: revenue quietly changes from gross to net
- Time window drift: “last 30 days” becomes calendar month
- Status inflation: boolean flags shift from factual to marketing-driven
- AI overreach: batch metrics used for real-time decisioning
- Partial backfills: historical data does not align with new definitions
None of these violate schemas.
All of them break trust.
Why Semantic Contracts Are Now Mandatory
Three trends make semantic contracts unavoidable:
- Conversational analytics removes human validation loops
- Agentic systems automate decisions at machine speed
- Cross-domain AI combines datasets never designed to align semantically
In this environment, undocumented meaning becomes a liability.
A Practical Adoption Model
You do not need to boil the ocean.
Phase 1: Awareness
- Identify datasets consumed by AI
- Document two or three critical semantic assumptions per dataset
Phase 2: Enforcement
- Add CI checks for semantic changes
- Version semantic contracts independently
Phase 3: Runtime Control
- Gate AI use cases explicitly
- Log semantic versions with every AI response
Phase 4: Maturity
- Automate semantic drift detection
- Integrate semantic metadata into lineage and observability
Each phase delivers value independently.
Semantic Contracts Versus More Metadata
Semantic contracts are not about adding more metadata fields.
They are about making meaning explicit, making changes intentional, and making AI systems safer by design.
Metadata describes.
Contracts constrain.
Final Thought
Schemas tell systems how data is shaped.
Data quality checks tell systems whether data is valid.
Lineage tells systems where data comes from.
Semantic contracts tell systems what data means.
In an AI-driven world, meaning is the most important contract of all.
Opinions expressed by DZone contributors are their own.
Comments