From ETL to Lakeflow: Shifting to a Declarative Data Paradigm
The article focuses on moving away from traditional, "imperative" ETL processes to a modern, "declarative" approach using the Databricks Lakeflow platform.
Join the DZone community and get the full member experience.
Join For FreeIf you've worked on a data platform for more than a few years, you've almost certainly built the same pipeline twice. First, the way the team wrote pipelines in 2019: a notebook here, a Python script there, an Airflow DAG to glue it all together, and a long document explaining the order things had to run in. Then the rewrite, two years later, when somebody quit, and nobody could remember why a particular task had a sleep(180) in it.
Lakeflow is Databricks' answer to that pattern, and the shift it's pushing for is bigger than the marketing makes it sound. It isn't a new orchestrator. It's a move from imperative pipelines, where you write the steps, to declarative pipelines, where you write the destination and let the engine figure out the steps. What follows is the practical version of that shift — what's actually different, where the gains are real, and how to migrate without ending up with a half-converted lakehouse.
1. The Imperative ETL Trap: Why Traditional Pipelines Are Hitting a Wall
Imperative ETL is a fancy name for the way most pipelines are still written: a sequence of steps, hand-ordered, run on a schedule. It works fine until it doesn't, and the failure modes are remarkably consistent across teams I've worked with:
- The DAG outgrows its author. The person who wrote the original 30-task Airflow DAG moves teams. The next engineer is afraid to delete anything because they can't tell which tasks are still needed.
- Backfills are surgical operations. Re-running yesterday means manually figuring out which downstream tables are stale, in what order. Half the team's tribal knowledge lives in Slack threads about backfills.
- Quality checks are bolted on. Data quality lives in a separate framework, often a separate codebase, often run by a separate team. By the time a check fails, the bad data is already in the warehouse.
- Lineage is a slide in a deck. Whatever lineage exists was drawn by hand for a quarterly review and was out of date the day after.
None of these are bugs in the imperative model. They're features of it. When you write the steps, you own the steps — including all the cross-task assumptions the engine doesn't know about.
2. What "Declarative" Actually Means in Lakeflow
Declarative is one of those words that gets used loosely. In Lakeflow Pipelines, it has a specific, narrow meaning: you describe each table's logical definition (its source query, its expected schema, its quality rules), and the engine determines execution. It picks the order. It decides which tables are streaming and which are batch. It scales the cluster. It figures out incremental processing. It produces lineage automatically because lineage is now a derived property of the dependency graph it built for you.
What it isn't:
- It isn't "low-code." You're still writing SQL or PySpark. The thing that's gone is the orchestration boilerplate around it.
- It isn't a magic upgrade for any pipeline. Pipelines that genuinely need procedural logic — multi-step API calls with branching, complex pre/post-processing — still belong in Lakeflow Jobs (the orchestrator) or even external code, called from the pipeline.
- It isn't free. There's a learning curve in stopping yourself from writing the steps you used to write. The first month, most teams over-specify.
|
The mental shift: stop describing how the data should flow. Describe what each table is. Lakeflow figures out the flow. |
3. The Lakeflow Architecture: Connect, Pipelines, Jobs
Lakeflow is three components that share one governance layer (Unity Catalog). They map roughly onto the three traditional layers of a pipeline — ingestion, transformation, orchestration — but with the imperative wiring removed.
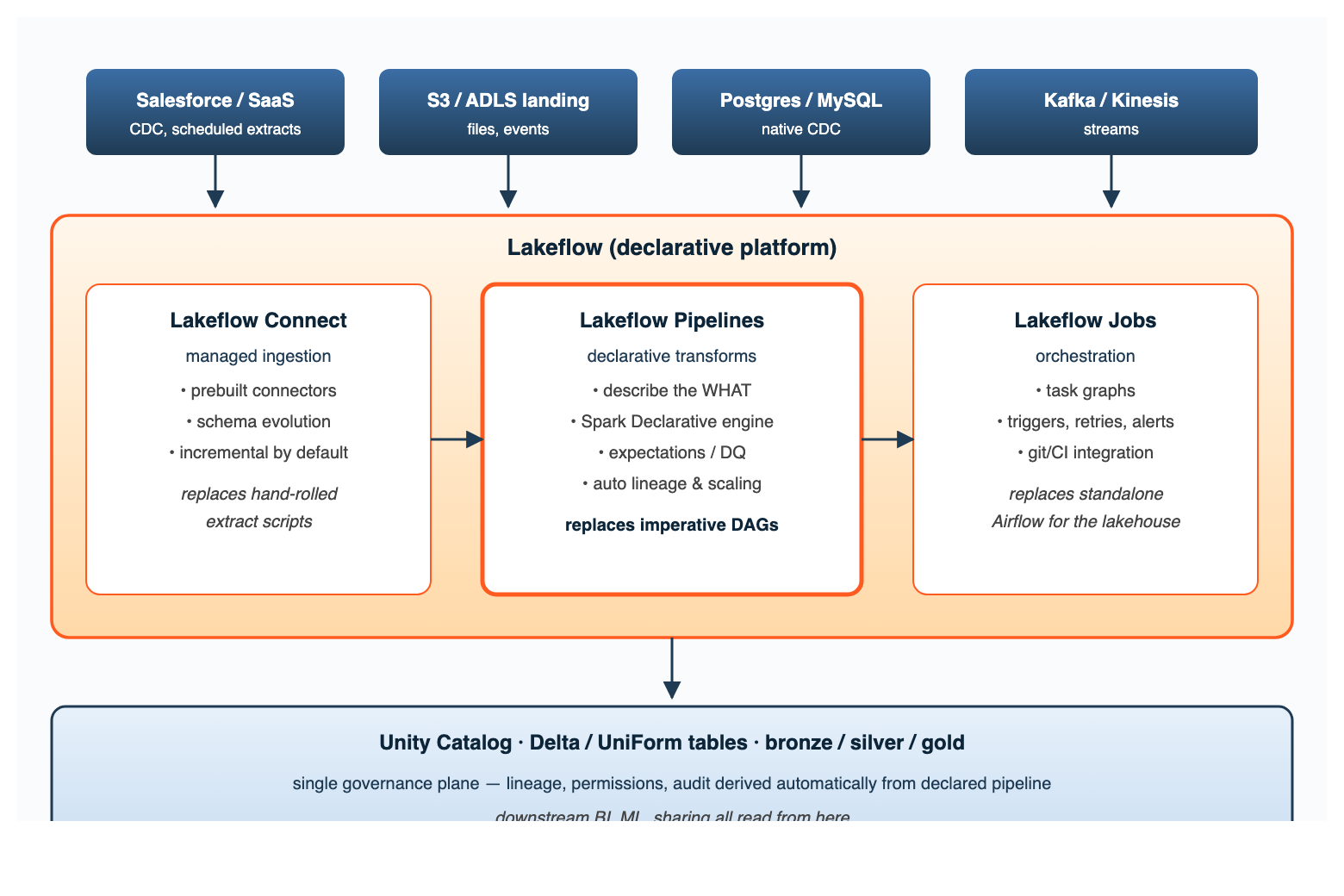
Figure 1. Lakeflow's three components on top of Unity Catalog. Pipelines is the declarative core; Connect feeds it, Jobs schedules it.
A few practical points about this picture. Lakeflow Connect is where managed connectors live (Salesforce, Workday, Postgres CDC, and a steadily growing list); it's the part you reach for instead of writing yet another ingestion script. Lakeflow Pipelines is where the declarative paradigm actually lives — every other component is conventional. And Lakeflow Jobs is the part that looks most like Airflow: task graphs, retries, alerts. The trick is that the things inside a Pipelines task aren't tasks themselves — they're table definitions, and the engine builds the internal DAG from their dependencies.
4. Translating an Imperative Pipeline to a Declarative One
The clearest way to feel the difference is to look at the same logic written both ways. Imagine a small bronze→silver→gold pipeline for transactions: ingest raw files, deduplicate, then aggregate to daily totals.
4a. The imperative version (notebook + Airflow style)
# bronze.py
df = spark.read.json("s3://landing/txns/")
df.write.format("delta").mode("append").saveAsTable("bronze.txns")
# silver.py -- runs after bronze finishes
raw = spark.table("bronze.txns")
clean = (raw.dropDuplicates(["txn_id"])
.filter("amount IS NOT NULL"))
clean.write.format("delta").mode("overwrite").saveAsTable("silver.txns")
# gold.py -- runs after silver finishes
agg = (spark.table("silver.txns")
.groupBy("ingest_date", "account_id")
.sum("amount")
.withColumnRenamed("sum(amount)", "daily_total"))
agg.write.format("delta").mode("overwrite").saveAsTable("gold.daily_totals")
# airflow_dag.py -- the part that actually controls execution
bronze_task >> silver_task >> gold_task4b. The same logic, declared in a Lakeflow Pipeline
import dlt
from pyspark.sql.functions import sum as _sum
@dlt.table(
name="bronze_txns",
comment="Raw transactions landed from S3.",
)
def bronze_txns():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("s3://landing/txns/"))
@dlt.table(name="silver_txns", comment="Deduplicated, validated transactions.")
@dlt.expect_or_drop("non_null_amount", "amount IS NOT NULL")
@dlt.expect("unique_txn", "txn_id IS NOT NULL")
def silver_txns():
return (dlt.read_stream("bronze_txns")
.dropDuplicates(["txn_id"]))
@dlt.table(name="gold_daily_totals")
def gold_daily_totals():
return (dlt.read("silver_txns")
.groupBy("ingest_date", "account_id")
.agg(_sum("amount").alias("daily_total")))Two things vanished in the rewrite. There is no DAG file, because the dependencies are inferred from dlt.read / dlt.read_stream calls. There is no separate data quality framework — quality lives next to the table definition, where it belongs. The engine decides what's streaming and what's batch from the calls themselves; bronze is a stream, silver is a stream of the bronze stream, gold is a batch over silver. None of that ordering is in the code I wrote.
5. Quality, Lineage, and Operational Visibility for Free
The expectations decorators above (@dlt.expect, @dlt.expect_or_drop, and the stricter @dlt.expect_or_fail) are not just convenience syntax; they become first-class objects in the pipeline. Every run produces a per-expectation pass/fail count, queryable directly:
-- How many silver rows failed each expectation, per run, last 7 days
SELECT pipeline_run_id,
flow_name,
expectation_name,
passed_records,
failed_records,
dropped_records
FROM event_log("<pipeline-id>")
WHERE event_type = 'flow_progress'
AND timestamp >= current_timestamp() - INTERVAL 7 DAYS
ORDER BY timestamp DESC;Lineage shows up automatically in Unity Catalog — both the table-level edges (gold_daily_totals depends on silver_txns) and column-level edges (gold's daily_total derives from silver's amount). Operationally, this is the change that has the largest day-to-day impact: when somebody asks "what does this column mean and where did it come from," you stop having to guess.
|
What this replaces: Great Expectations runs scheduled separately, OpenLineage stitched together by hand, and a homegrown observability dashboard reading task logs. All three of those projects either go away or shrink dramatically. |
6. Migration Strategy: How Teams Actually Move Off Imperative Pipelines
I've not seen a successful big-bang migration. The pattern that works is layered:
Phase 1 — New pipelines only
Make Lakeflow Pipelines the default for any new pipeline. This sounds obvious; the discipline is in saying no when somebody wants to add "just one more" Airflow DAG to the imperative side because it's faster this week.
Phase 2 — Convert the painful ones
Pick the existing pipelines that hurt the most — the ones with the longest backfill stories, the most ad-hoc quality checks, the worst lineage gaps. Those are the ones where the declarative model pays for the rewrite cost fastest. Don't start with the easy ones; their owners won't thank you for the disruption.
Phase 3 — Retire the orchestration boilerplate
Once a critical mass of pipelines has moved over, you can shrink (or in many cases delete) Airflow setups, custom dependency-tracking tools, and the side projects that grew up around imperative ETL. This is the phase where the cost savings actually show up in headcount and infrastructure bills.
|
Migration step |
Effort |
Watch out for |
|---|---|---|
|
New pipelines on Lakeflow |
Low |
Team momentum — easy to revert to old patterns. |
|
Convert the top 3 painful pipelines |
Medium |
Different streaming/batch semantics in expressed dependencies. |
|
Move expectations off external DQ tools |
Medium |
Existing alerting wired to the old framework. |
|
Retire imperative orchestrator |
High |
External callers (BI tools, ML jobs) that triggered DAGs directly. |
7. Where Declarative Still Hurts: Honest Limitations
I'd be lying if I said this was free. The places where the declarative model still bites:
- Procedural logic doesn't fit. If your "pipeline" is really a sequence of API calls with branching error handling, that's a Lakeflow Job (or external code), not a declarative table.
- Cross-pipeline orchestration is its own thing. Lakeflow Pipelines builds the DAG inside a pipeline. If you need pipeline A to wait for pipeline B, you still need Lakeflow Jobs above them.
- Debugging shifts from steps to definitions. When something is wrong, you're not stepping through a script — you're reading the event log and figuring out which expectation or upstream table caused it. The tooling is good; the muscle memory is different.
- Cost can surprise you. Auto-scaling on a misbehaving streaming source has the same risk it always has. Set max workers thoughtfully on day one; don't leave it to defaults.
Conclusion
The shift to declarative pipelines isn't really about syntax. It's about who owns the boring parts. In an imperative pipeline, the team owns the order, the retries, the lineage, the quality checks, and the cluster scaling — and pays in headcount when any of those break. In a declarative pipeline, those become properties of the engine, and the team owns the part that's actually interesting: the table definitions and the business logic. Lakeflow is the cleanest implementation of that idea I've used in production, and the teams I've watched migrate haven't asked to go back.
Opinions expressed by DZone contributors are their own.
Comments