Streaming Data Joins: A Deep Dive Into Real-Time Data Enrichment
Unravel the complexities of streaming data joins in this guide covering key concepts, design, and best practices for optimal real-time data enrichment.
Join the DZone community and get the full member experience.
Join For FreeIntroduction to Data Joins
In the world of data, a "join" is like merging information from different sources into a unified result. To do this, it needs a condition – typically a shared column – to link the sources together. Think of it as finding common ground between different datasets.
In SQL, these sources are referred to as "tables," and the result of using a JOIN clause is a new table. Fundamentally, traditional (batch) SQL joins operate on static datasets, where you have prior knowledge of the number of rows and the content within the source tables before executing the Join. These join operations are typically simple to implement and computationally efficient. However, the dynamic and unbounded nature of streaming data presents unique challenges for performing joins in near-real-time scenarios.
Streaming Data Joins
In streaming data applications, one or more of these sources are continuous, unbounded streams of information. The join needs to happen in (near) real-time. In this scenario, you don't know the number of rows or the exact content beforehand.
To design an effective streaming data join solution, we need to dive deeper into the nature of our data and its sources. Questions to consider include:
- Identifying sources and keys: Which are the primary and secondary data sources? What is the common key that will be used to connect records across these sources?
- Join type: What kind of Join (
Inner Join,Left Join,Right Join,Full Outer Join) is required? - Join window: How long should we wait for a matching event from the secondary source to arrive for a given primary event (or vice-versa)? This directly impacts latency and Service Level Agreements (SLAs).
- Success criteria: What percentage of primary events do we expect to be successfully joined with their corresponding secondary events?
By carefully analyzing these aspects, we can tailor a streaming data join solution that meets the specific requirements of our application.
The streaming data join landscape is rich with options. Established frameworks like Apache Flink and Apache Spark (also available on cloud platforms like AWS, GCP, and Databricks) provide robust capabilities for handling streaming joins. Additionally, innovative solutions that optimize specific aspects of the infrastructure, such as Meta's streaming join focusing on memory consumption, are continuously emerging.
Scope
The goal of this article isn't to provide a tutorial on using existing solutions. Instead, we'll delve into the intricacies of a specific streaming data join solution, exploring the tradeoffs and assumptions involved in its design. This approach will illuminate the underlying principles and considerations that drive many of the out-of-the-box streaming join capabilities available in the market.
By understanding the mechanics of this particular solution, you'll gain valuable insights into the broader landscape of streaming data joins and be better equipped to choose the right tool for your specific use case.
Join Key
The key is a shared column or field that exists in both datasets. The specific Join Key you choose depends on the type of data you're working with and the problem you're trying to solve. We use this key to index incoming events so that when new events arrive, we can quickly look up and find any related events that are already stored.
Join Window
The join window is like a time frame where events from different sources are allowed to "meet and match." It's an interval during which we consider events eligible to be joined together. To set the right join window, we need to understand how quickly events arrive from each data source. This ensures that even if an event is a bit late, we still have its related events available and ready to be joined.
Architecting Streaming Data Joins
Here's a simplified representation of a common streaming data pipeline. The individual components are shown for clarity, but they wouldn't necessarily be separate systems or jobs in a production environment.
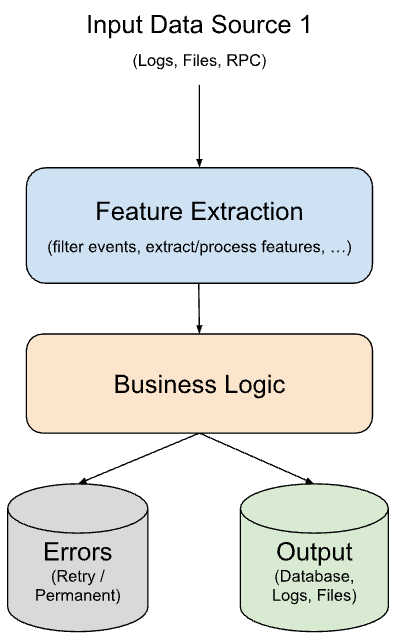
Description
A typical streaming data pipeline processes incoming events from a data source (Source 1), often passing them through a c. This component can be thought of as a way to refine the data: filtering out irrelevant events, selecting specific features, or transforming raw data into more usable formats. The refined events are then sent to the Business Logic component, where the core processing or analysis happens. This Feature Extraction step is optional; some pipelines may send raw events directly to the Business Logic component.
Problem
Now, imagine our pipeline needs to combine information from additional sources (Source 2 and Source 3) to enrich the main data stream. However, we need to do this without significantly slowing down the processing pipeline or affecting its performance targets.
Solution
To address this, we introduce a Join Component just before the Business Logic step. This component will merge events from all the input sources based on a shared unique identifier, let's call it Key X. Events from each source will flow into this Join Component (potentially after undergoing Feature Extraction).
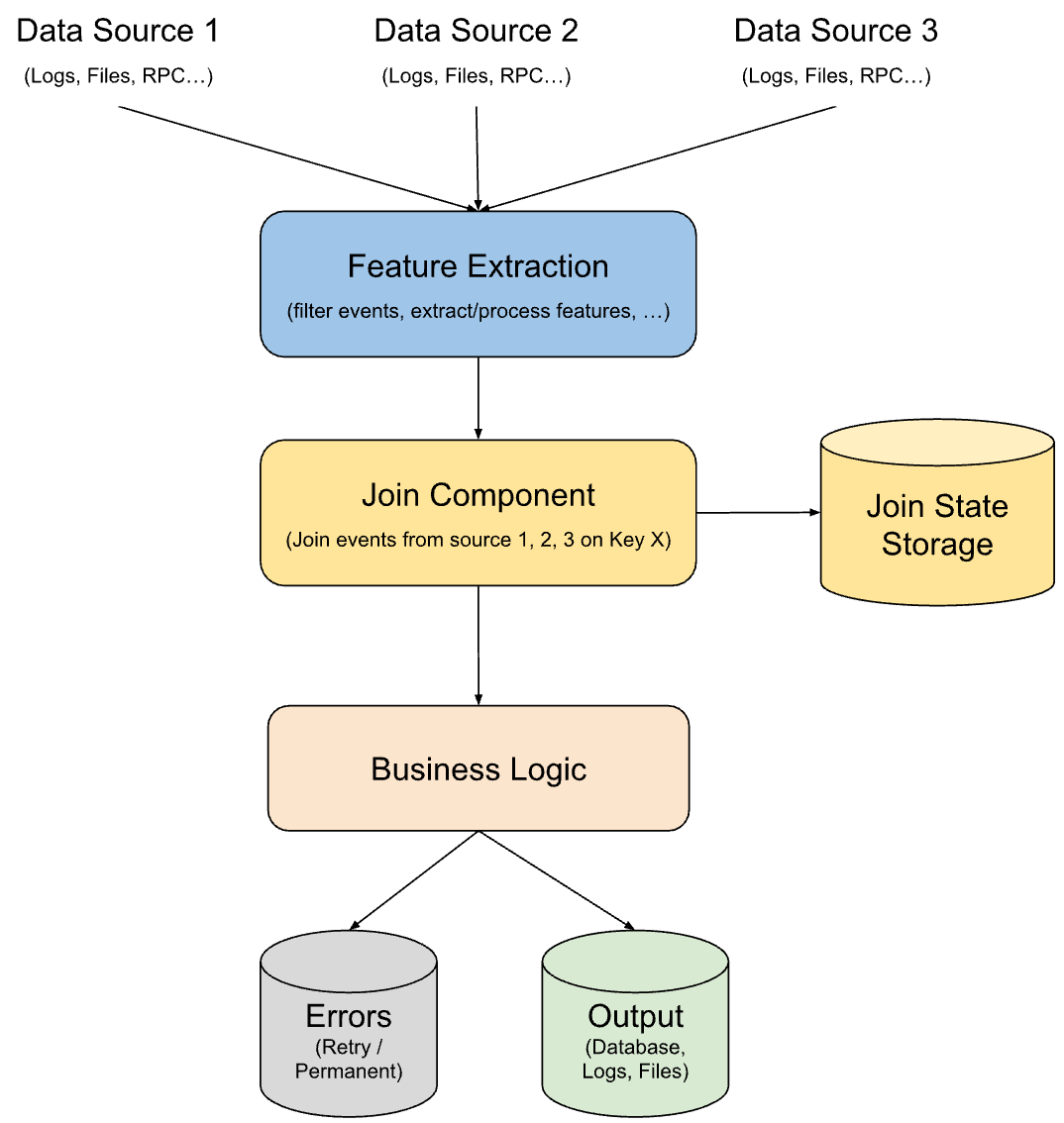
The Join Component will utilize a state storage (like a database) to keep track of incoming events based on Key X. Think of it as creating separate tables in the database for each input source, with each table indexing events by Key X. As new events arrive, they are added to their corresponding table (like Event from source 1 to table 1, event 2 to table 2, etc.) along with some additional metadata. This Join State can be imagined as follows:
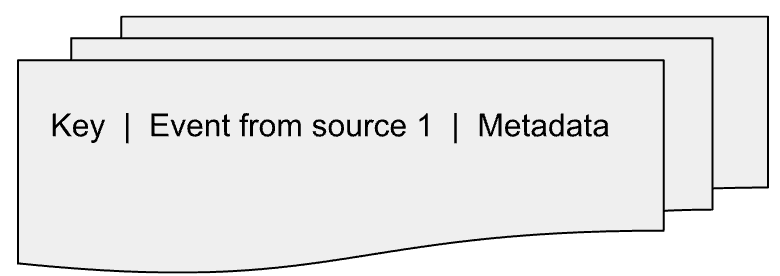
Join Trigger Conditions
All Expected Events Arrive
This means we've received events from all our data sources (Source 1, Source 2, and Source 3) for a specific Key X.
-
We can check for this whenever we're about to add a new event to our state storage. For example, if the Join Component is currently processing an event with Key X from Source 2, it will quickly check if there are already matching rows in the tables for Source 1 and Source 3 with the same Key X. If so, it's time to join!
Join Interval Expires
This happens when at least one event with a particular Key X has been waiting too long to be joined. We set a time limit (the join window) for how long an event can wait.
-
To implement this, we can set an expiration time (TTL) on each row in our tables. When the TTL expires, it triggers a notification to the Join Component, letting it know that this event needs to be joined now, even if it's missing some matches. For instance, if our join window is 15 minutes and an event from Source 2 never shows up, the Join Component will get a notification about the events from Source 1 and Source 3 that are waiting to be joined with that missing Source 2 event. Another way to handle this is to have a periodic job that checks the tables for any expired keys and sends notifications to the Join Component.
Note: This second scenario is only relevant for certain types of use cases where we want to include events even if they don't have a complete match. If we only care about complete sets of events (like INNER JOIN), we can ignore this time-out trigger.
How the Join Happens
When either of our trigger conditions is met — either we have a complete set of events or an event has timed out — the Join Component springs into action. It fetches all the relevant events from the storage tables and performs the join operation. If some required events are missing (and we're doing a type of join that requires complete matches), the incomplete event can be discarded. The final joined event, containing information from all the sources, is then passed on to the Business Logic component for further processing.
Visualization
Let's make this a bit easier to picture. Imagine that events from all three sources (Source 1, Source 2, and Source 3) happen simultaneously at 12:00:00 PM. Consider the join window as 5 minutes.

Optimizations
Set Expiration Times (TTLs)
By setting a TTL for each row in our join state storage, we enable the database to automatically clean up old events that have passed their join window.
Compact Storage
Instead of storing entire events, store them in a compressed format (like bytes) to further reduce the amount of storage space needed in our database.
Outer Join Optimization
If the use case is to perform an OUTER JOIN and one of the event streams (let's say Source 1) is simply too massive to be fully indexed in our storage, we can adjust our approach. Instead of indexing everything from Source 1, we can focus on indexing the events from Source 2 and Source 3. Then, when an event from Source 1 arrives, we can perform targeted lookups into the indexed events from the other sources to complete the join.
Limit Failed Joins
Joining events can be computationally expensive. By minimizing the number of failed join attempts (where we try to join events that don't have matches), we can reduce memory usage and keep our streaming pipeline running smoothly. We can use the Feature Extraction component before the Join Component to filter out events that are unlikely to have matching events from other sources.
Tuning Join Window
While understanding the arrival patterns of events from your input sources is crucial, it's not the only factor to consider when fine-tuning your Join Window. Factors such as data source reliability, latency requirements (SLAs), and scalability also play significant roles.
- Larger join window: Increases the likelihood of successfully joining events, in case of delays in event arrival times; may lead to increased latency as the system waits longer for potential matches
- Smaller join window: Reduces latency and memory footprint as events are processed and potentially discarded more quickly; join success rate might be low, especially if there are delays in event arrival
Finding the optimal Join Window value often requires experimentation and careful consideration of your specific use case and performance requirements.
Monitoring Is Key
It's always a good practice to set up alerts and monitoring for your join component. This allows you to proactively identify anomalies, such as events from one source consistently arriving much later than others, or a drop in the overall join success rate. By staying on top of these issues, you can take corrective action and ensure your streaming join solution operates smoothly and efficiently.
Conclusion
Streaming data joins is a critical tool for unlocking the full potential of real-time data processing. While they present unique challenges compared to traditional SQL (batch) joins, hopefully, this article has given you the idea to design effective solutions.
Remember, there is no one-size-fits-all approach. The ideal solution will depend on the specific characteristics of your data, your performance requirements, and your available infrastructure. By carefully considering factors such as join keys, join windows, and optimization techniques, you can build robust and efficient streaming pipelines that deliver timely, actionable insights.
As the streaming data landscape continues to evolve, so too will the solutions for handling joins. Keep learning about new technologies and best practices to make sure your pipelines stay ahead of the curve as the world of data keeps changing.
Opinions expressed by DZone contributors are their own.
Comments