Synchronous Kafka: Using Spring Request-Reply
With the latest release of Spring-Kafka, request-reply semantics are available off-the-shelf. This example demonstrates the simplicity of the Spring-Kafka implementation.
Join the DZone community and get the full member experience.
Join For FreeThe first connotation that comes to mind when Kafka is brought up is a fast, asynchronous processing system. Request-reply semantics are not natural to Kafka. In order to achieve the request-reply pattern, the developer has to build a system of correlation IDs in the producer records and match that in the consumer records.
With the latest release of Spring-Kafka, these request-reply semantics are now available off-the-shelf. This example demonstrates the simplicity of the Spring-Kafka implementation.
The below picture is a simple demonstrative service to calculate the sum of two numbers that requires synchronous behavior to return the result.
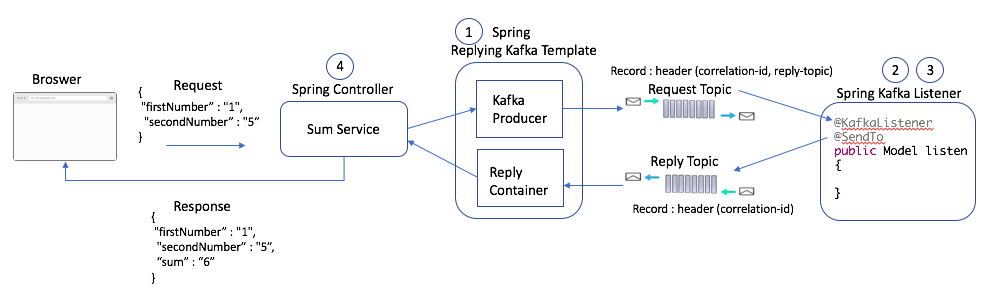
1. Set Up Spring ReplyingKafkaTemplate
This class extends the behavior of KafkaTemplate to provide request-reply behavior. To set this up, you need a producer (see ProducerFactory in the below code) and KafkaMessageListenerContainer. This is an intuitive setup since both producer and consumer behavior is needed for request-reply.
// ReplyingKafkaTemplate
@Bean
public ReplyingKafkaTemplate<String, Model, Model> replyKafkaTemplate(ProducerFactory<String, Model> pf, KafkaMessageListenerContainer<String, Model> container) {
return new ReplyingKafkaTemplate<>(pf, container);
}
// Listener Container to be set up in ReplyingKafkaTemplate
@Bean
public KafkaMessageListenerContainer<String, Model> replyContainer(ConsumerFactory<String, Model> cf) {
ContainerProperties containerProperties = new ContainerProperties(requestReplyTopic);
return new KafkaMessageListenerContainer<>(cf, containerProperties);
}
// Default Producer Factory to be used in ReplyingKafkaTemplate
@Bean
public ProducerFactory<String,Model> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
// Standard KafkaProducer settings - specifying brokerand serializer
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return props;
}2. Set Up Spring-Kafka Listener
This is the standard setup of the Kafka Listener. The only additional change is to set the ReplyTemplate in the factory. This is needed since the consumer will now also need to post the result on the reply-topic of the record.
// Default Consumer Factory
@Bean
public ConsumerFactory<String, Model> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs(),new StringDeserializer(),new JsonDeserializer<>(Model.class));
}
// Concurrent Listner container factory
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, Model>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Model> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// NOTE - set up of reply template
factory.setReplyTemplate(kafkaTemplate());
return factory;
}
// Standard KafkaTemplate
@Bean
public KafkaTemplate<String, Model> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}3. Kafka Consumer
This is the same consumer that you have created in the past. The only change is the additional @SendTo annotation. This annotation returns a result on the reply topic.
@KafkaListener(topics = "${kafka.topic.request-topic}")
@SendTo
public Model listen(Model request) throws InterruptedException {
int sum = request.getFirstNumber() + request.getSecondNumber();
request.setAdditionalProperty("sum", sum);
return request;
}4. Sum Service
Now, let's bring all of this together. On Line 15, I print all headers. You can see that Spring automatically sets a correlation ID in the producer record. This correlation ID is returned as-is by the @SendTo annotation at the consumer end.
@ResponseBody
@PostMapping(value="/sum",produces=MediaType.APPLICATION_JSON_VALUE,consumes=MediaType.APPLICATION_JSON_VALUE)
public Model sum(@RequestBody Model request) throws InterruptedException, ExecutionException {
// create producer record
ProducerRecord<String, Model> record = new ProducerRecord<String, Model>(requestTopic, request);
// set reply topic in header
record.headers().add(new RecordHeader(KafkaHeaders.REPLY_TOPIC, requestReplyTopic.getBytes()));
// post in kafka topic
RequestReplyFuture<String, Model, Model> sendAndReceive = kafkaTemplate.sendAndReceive(record);
// confirm if producer produced successfully
SendResult<String, Model> sendResult = sendAndReceive.getSendFuture().get();
//print all headers
sendResult.getProducerRecord().headers().forEach(header -> System.out.println(header.key() + ":" + header.value().toString()));
// get consumer record
ConsumerRecord<String, Model> consumerRecord = sendAndReceive.get();
// return consumer value
return consumerRecord.value();
}5. Concurrent Consumers
The behavior of request-reply is consistent even if you were to create, say, three partitions of the request topic and set the concurrency of three in consumer factory. The replies from all three consumers still go to the single reply topic. The container at the listening end is able to do the heavy lifting of matching the correlation IDs.
6. Code, Kafka, and Other Setups
The complete running code is available in my repository on GitHub here.
Also, if you are looking for a quick Kafka setup on your local machine, I suggest that you use Kafka using Docker. Here is the command that will fire Kafka for local testing.
docker run --rm -p 2181:2181 -p 3030:3030 -p 8081-8083:8081-8083 -p 9581-9585:9581-9585 -p 9092:9092 -e ADV_HOST=127.0.0.1 landoop/fast-data-dev:latestIf you fancy a UI on top of this Kafka, then run this Docker command and you will have a UI running at port 8000.
docker run --rm -it -p 8000:8000 -e "KAFKA_REST_PROXY_URL=http://localhost:8082" landoop/kafka-topics-uiHappy coding!
Opinions expressed by DZone contributors are their own.
Comments