Taming Reinforcement Learning Chaos: An MLOps Architecture for Experiment Management
Reinforcement learning is powerful, but managing thousands of iterations is a nightmare. Here is a practical architecture for building a lightweight experiment system.
Join the DZone community and get the full member experience.
Join For FreeReinforcement learning (RL) has achieved superhuman performance in domains ranging from Go (AlphaGo) to complex robotics control. However, unlike supervised learning, where data is static, RL is dynamic. It relies on an agent interacting with an environment through massive trial and error.
For engineering teams, this "trial and error" nature creates a significant MLOps bottleneck. A single viable model might require hundreds of experiments, each with slight variations in reward functions, learning rates, or environment physics.
The common reality? Engineers manage these configurations in local JSON files or spreadsheets. They copy-paste configurations, manually tweak a parameter, run a script, and pray they remember what they changed three days later. This leads to configuration drift, wasted compute time, and the "it worked on my machine" syndrome.
Based on recent case studies in autonomous system development, this article outlines an architectural pattern to build a learning management efficiency tool that streamlines RL workflows.
The Problem: The "TensorBoard Gap"
Most RL practitioners use tools like TensorBoard to visualize training curves (reward over time). While excellent for monitoring results, these tools often fail to manage intent.
The typical pain points in a raw RL workflow include:
- Parameter explosion: Complex environments have hundreds of parameters. Changing one often breaks another.
- The "Copy-Paste" error: Manually creating a new config file based on an old one often leads to typo-induced failures.
- Context loss: Looking at a learning curve six months later, you might know that it failed, but not why you chose those specific hyperparameters.
To solve this, we need a wrapper architecture, an experiment manager that sits between the user and the training engine.
The Solution Architecture
The proposed solution moves the training logic into a containerized service and manages it via a web interface. This ensures that the training environment is reproducible and decoupled from the engineer's local machine.
High-Level Design
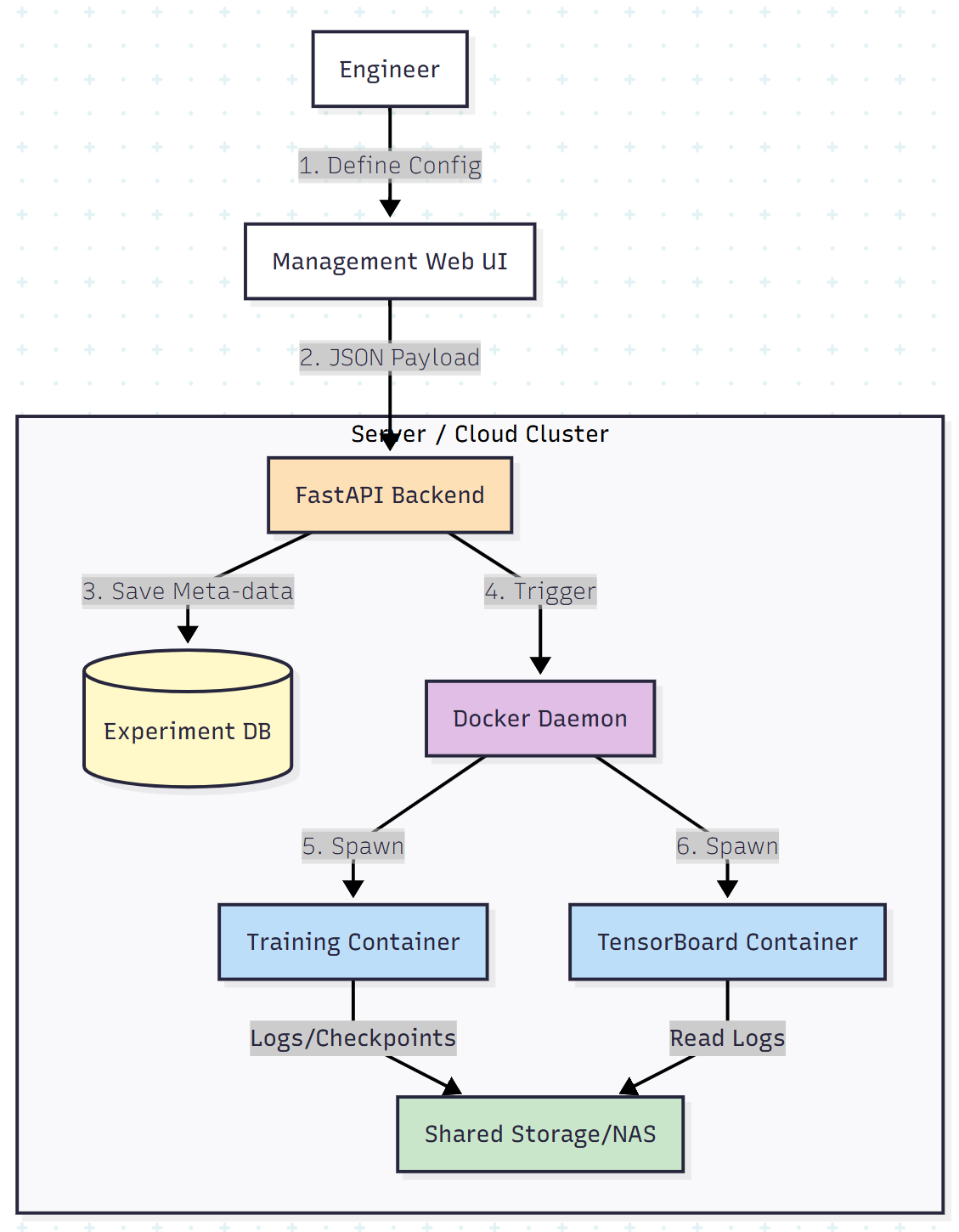
The system consists of three core components:
- The management UI: A React-based frontend for defining experiments.
- The orchestrator: A FastAPI backend that handles configuration inheritance and job dispatch.
- The execution layer: Docker containers that run the actual RL algorithms (e.g., PPO, DQN) and TensorBoard instances.
Key Feature 1: Configuration Inheritance
In RL, you rarely start from scratch. You usually take a promising experiment and tweak the learning_rate or reward_penalty.
Instead of duplicating the entire configuration file (which makes it hard to see what changed), this architecture uses an Inheritance Model.
- Parent experiment: The baseline configuration.
- Child experiment: Stores only the delta (the parameters that changed).
When the orchestrator triggers a job, it recursively merges the child config onto the parent config.
Conceptual Python implementation:
import copy
def merge_configs(parent_config, child_changes):
"""
Recursively merges child parameter overrides into the parent config.
"""
final_config = copy.deepcopy(parent_config)
for key, value in child_changes.items():
if isinstance(value, dict) and key in final_config:
final_config[key] = merge_configs(final_config[key], value)
else:
final_config[key] = value
return final_config
# Example Usage
baseline = {"learning_rate": 0.001, "batch_size": 64, "algorithm": "PPO"}
experiment_v2 = {"learning_rate": 0.0005} # Only storing the diff
runtime_config = merge_configs(baseline, experiment_v2)
# Result: {"learning_rate": 0.0005, "batch_size": 64, "algorithm": "PPO"}This approach reduces database storage and, more importantly, allows the UI to highlight only the changed parameters in Red/Green diffs, instantly showing the engineer the hypothesis being tested.
Key Feature 2: Remote Execution and Containerization
Deep learning rigs are expensive and shared. Running training scripts locally on a developer laptop is inefficient.
By containerizing the RL environment, the experiment manager allows users to trigger training on a remote GPU cluster via a simple "Start" button.
- Image build: The standard environment (Simulators + PyTorch/TensorFlow) is built into a Docker image.
- Volume mounting: When a job starts, the system mounts a network-attached storage (NAS) volume to /opt/training/logs.
- Lifecycle: The back-end monitors the container exit code. If it fails, the error logs are captured and displayed in the UI, preventing the need to SSH into the server to debug crashes.
Key Feature 3: Standardizing "Intent"
One of the biggest sources of "technical debt" in AI is undefined objectives. The system should enforce a schema for metadata before a run is allowed to start.
The "contract" form:
- Objective: (Dropdown/Text) e.g., "Reduce oscillation in turning maneuver."
- Hypothesis: "Lowering entropy coefficient will stabilize convergence."
- Expected outcome: "Reward > 500."
By forcing these fields, the system turns a folder of log files into a searchable knowledge base. New team members can query: "Show me all experiments where we tried to fix oscillation," and see exactly what parameters were tuned.
ROI and Impact
Implementing this pattern in real-world scenarios has shown significant efficiency gains:
- 83% reduction in setup time: Automating the config merging and container deployment replaced manual script editing and command-line execution.
- 50% reduction in rework: Visual diffs of parameters prevented "fat-finger" errors where engineers thought they changed a parameter but actually ran the default configuration.
- Knowledge transfer: Senior engineers could review the "Experiment Ledger" to guide junior engineers, rather than debugging their local scripts.
Conclusion
Reinforcement learning is complex enough without fighting your infrastructure. By building or adopting a lightweight experiment management system that prioritizes configuration inheritance and parameter visibility, you transform your ML workflow from a chaotic art form into a reproducible engineering discipline.
Don't just track your loss functions; track your decisions.
Opinions expressed by DZone contributors are their own.
Comments