Technical Approach to Design an Extensible and Scalable Data Processing Framework
This paper discusses and proposes few options to handle the distributed processing concerns and develop an efficient and optimized framework.
Join the DZone community and get the full member experience.
Join For FreeDistributed data processing for analytics is a rapidly expanding ecosystem in every medium to large scale as well as innovative organizations. These enterprises are putting a lot of emphasis and focus in this area to develop optimized, extensible and scalable data processing ecosystems to process organizations raw voluminous disparate datasets and extract meaningful insight out of it. The focus is not just to establish a processing framework but also investigate other key aspects of the framework like how extensible it is, how quickly it can respond to any change as well how the complex processing logic will be authored and defined and how can any last-minute change to processing requirements can be incorporated in the underlying processing framework with minimal disruption and effort.
This paper discusses and proposes a few options to handle all the above highlighted concerns and develop an efficient and optimized framework which provides flexibility to configure different kinds of processing logic based on few key parameters like:
- How frequently the logic will undergo change
- How fast the process should run
- How much data the application must process
- How the application will scale and what type of processing should it support (i.e., distributed processing, monolithic processing, as well as cloud-based processing)
In response to the complexities involved in the distributed data processing pipeline, the work in this paper also discusses some of the popular use cases and options to design the scalable framework whilst also maintaining greater control, quick response to any change and operational flexibility over their data.
Modern distributed data processing applications provide curated and succinct output datasets to the downstream analytics to produce optimized dashboarding and reporting to support multiple sets of stakeholders for informed decision-making. The output of the data processing pipeline must be pertinent to the objective as well as provide summarized and to-the-point information from the backend data processing pipeline. The middleware data processing thus becomes the backbone of these analytics applications to consume voluminous datasets from multiple upstreams and process the complex analytics logic to generate the summarized outcomes, which are then consumed by analytics engines to generate different kinds of reports and dashboards for multiple purposes. The most broadly defined objective for these analytics systems is as listed below:
- Forecasting application to predict the outcome for the future based on the historical trend to decide the future strategies for the organization
- Reporting for senior leadership to display the performance of the organization and assess profitability
- Reporting to external stakeholders for companies’ performance and future guidance
- Regulatory reporting to external and internal regulators
- Various kinds of compliance and risk reporting
- Provide processed and summarized output to data scientists, data stewards, and data engineers to aid them in their data analysis needs
There can be many more needs for the organization requiring the analytics processing output to generate the summarized information which will be consumed by the analytics application for generating the reports, charts, and dashboards.
With all these critical analytics needs, the processing of organizations' raw data to generate vital outcomes is very crucial and becoming the top project for all large and medium-sized organizations.
Again, the analytics processing ecosystem for the organizations should be extensible and agile enough to respond to the changing processing requirements as well, and performance is another crucial factor in processing the voluminous data to generate outcomes as per the given aggressive SLA ranging from hourly and daily, weekly, monthly quarterly with different kinds of frequencies for different sets of analytics and reporting needs.
With this said it's very critical for the organization to develop the analytics processing application in a manner that can quickly adapt to any change in processing requirements and respond to the change in a very agile manner with minimal effort and disruption to other parts of the end-to-end processing pipeline. The paramount focus is to define the best optimal way to structure the processing logic for the analytics processing application.
Agility to change the processing logic will be the backbone of these applications, and it can facilitate the users to change the logic and incorporate any new requirements to the processing pattern with minimal effort and with a faster turnaround time to respond to the changes. The recommendation is to have the processing logic decoupled with the processing engine to have a clear separation of concern and isolation of responsibilities for the implementation team managing and focusing on the analytics processing logic as well as the team managing the processing engine framework focus on keeping the processing framework seamless and supple. This will help to maintain the frameworks in a better manner as well as have lesser comingled processing logic and a simplified approach towards analytical processing.
Other points to consider while deciding the approach are how the application deals with high-volume datasets and how frequently the underlying processing logic will undergo any change based on changing business requirements to the processing logic. We have various ways to architect and design these analytics applications, a few of which are listed down below, and we can have more ways to design the application. We are here listing only a few common and prominent design approaches will focus on one approach in this article.
- An application can be developed as a monolithic where the logic resides in the form of code and will require a change in code for any change to processing requirements.
- The application is developed using an analytics database with instant elastic scalability and the ability to combine cloud features with an SQL query engine.
- The application is developed as a distributed processing application that can scale horizontally to cater to processing needs.
- Application to be developed as a set of disjoint and decoupled logic to be executed in a specified order. The loosely coupled logic can be structured either in the form of pure code using any programming language or as a configurable and metadata-based expression depending on how frequently it will undergo change. Again, the choice of structuring the logic either as configurable logic or in the form of pure code or hybrid will be the choice of the implementation team to enhance the maintainability of the application.
In this article, we will specifically focus on approach four mentioned above and will explain it in detail, along with some illustrations and examples. The biggest question here is how we can develop a maintainable solution that can respond to any kind of change in a very agile manner to meet the aggressive SLA timelines.
The application designer, while implementing the processing logic, will have to consider the best optimal way to onboard the logic. They will need to respond to the questions below for the given application to decide on the right design and architecture for the application.
- How can a voluminous dataset be processed?
- Vertical processing vs. horizontal processing
- Database processing vs. in-memory processing
- Cloud-based solution vs. monolithic solution
- How will the processing logic be defined?
- All the logic resides in the form of application code using any processing language like Java, Kotlin, Python, etc.
- Determine and segregate the processing logic into smaller parts of static logic, which will not undergo any change frequently and might change very rarely, and the other part of the logic, which undergoes change frequently and needs to be highly maintainable where the expectation is to have the logic to be updated based on the changing requirement and undergo all testing cycles and deployed in production with the given SLA timelines to fall within the timelines stipulated for the change and the application has to be agile as committed to the business to respond to the change with a quick turnaround.
With dynamically changing situations influenced by external and internal factors, the processing need is continuously changing to adapt and be relevant to the external and internal factors. The frequent changes to the processing requirements need to be interpreted by the Business Analyst and converted into business requirements for the implementation team. The implementation team next must decipher and translate the business requirement into a technical definition of the processing logic and incorporate the change in the application. How the change is implemented is something that needs to be carefully assessed and decided as the changes are now happening so frequently, and so many internal and external factors are enforcing and driving the changes. With these changing dynamics, the onus is on the technical team to architecting and design the application to design it in a manner that helps to respond to any change in processing requirement faster with minimal disruption and roll it out through multiple levels of testing until production in a quicker time frame as per the need of the time.  With this context in place, there is a need to evaluate the processing logic and have it in a very maintainable format so that it can be quickly changed.
With this context in place, there is a need to evaluate the processing logic and have it in a very maintainable format so that it can be quickly changed.
Also, determination and assessment need to be done as part of the design and analysis phase to determine what portion of the end-to-end logic will remain static, i.e., not undergoing a change in the foreseeable future based on the past historical trend and will require less maintenance. This portion of the logic will be written once in a format not very maintainable, possibly as a pure code, and will be set in a lower tier not anticipated to be changing at all. Also, what other portion of the end-to-end logic will be changing at a frequent phase and at a less frequent phase? Based on the outcome of the analysis, the logic needs to be segregated into separate tiers as listed below and will be designed and developed accordingly. The logic susceptible to change will be placed in higher tiers and will be designed and developed in a format that is highly maintainable and can be changed with minimal effort and disruption to the overall process. Below are the three categories proposed, and we can again have a different set of categories for any implementation based on how the processing logic will undergo change for this illustration. Below is what is proposed, but it's open to change, and the onus is entirely on the design team to decide the tiers and accordingly formulate the logic as per the finalized format for different tiers:
- Tier 1 logic: Logic undergoing changes very frequently. We can call it a hot bucket.
- Tier 2 logic: Logic anticipated undergoing change occasionally. We can call it a lukewarm bucket.
- Tier 3 logic: Not foreseen to undergo any change. We can call it a cold bucket.
Based on the above categorization of the complex and intricate processing logic, we need to design the strategy to write and maintain the logic. The different buckets need to be loosely coupled, and any change in the logic for one bucket should not impact other buckets. This will help to isolate the impact and minimize the testing as well as the scope of work. As the tier one logic will undergo changes very frequently, any change will just be confined to the components holding the logic for the tier 1 bucket. This will help the implementation team to focus on only one part of the whole application to incorporate any change to processing requirements and not overall.
Also, the strategies to author the logic for top-tier hot buckets need to be in the form of a more maintainable metadata-based structure that is configurable and decoupled from other lower tiers so any change to requirements can be swiftly configured in the underlying metadata. While configuring the logic in the metadata structure, the implementation team can also design required governance requirements in the form of appropriately defined checks and control around the metadata to ensure the logic is aptly configured and adequately validated while it is being authored.
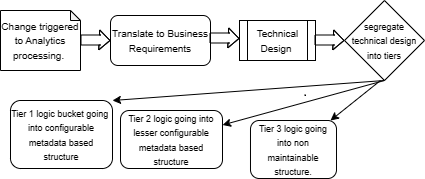
While designing the different logic tiers, designers need to ensure the processing logic is composed in a structure that conforms to tier definition and aligns with the maintainability and control requirements for the logic. Some key recommendations for different tiers are depicted below diagram and explained in detail for every tier:

Tier 1:
This layer will contain processing logic which is frequently undergoing changes and needs to be highly maintainable and should provide ease of maintenance and changes. Logic should be structured in a format that can be updated with ease, should be highly accessible on a stand-alone basis, and provide all the control and checks enforced as part of governance guidelines and principles. This can be in the form of metadata-based structures, custom processing structures, any open-source rule expressions, or even regular expressions. The processing expressions can be configured using any of the data serialization formats like JSON, YAML, XML, or any other confirming structured format that the implementation team determines to be compatible and aligned with the processing logic authoring and managing guidelines. The logic can also be persisted in the backend database in a custom structure and manipulated directly into those structures for any change to underlying requirements governing the logic. This tier should respond to any change in a very agile manner as well as provide quick turnaround to onboard the logic in the lower development environment and go through various levels of testing environments eventually to the production rollout. All this should be aligned with the SLA timelines defined to respond to such requirement changes.
The key to an optimized and extensible application to onboard any change in processing requirement is the agility provided by the application to incorporate the changes in the existing application as quickly as possible with minimal effort and rollout to the production environment after undergoing all validations and testing cycles.
Tier 2
This layer of processing will encompass logic which undergoes any change occasionally. This will be somewhere in between the hot logic changing mostly and cold logic, which rarely undergoes changes. Determining the spot between these two extremes and placing the logic into this bucket will be the most crucial part of designing the overall processing application and segregating the logic into this bucket. The logic, once identified, should be placed in a structure that facilitates the technical team to maintain any change with ease. The best way to place this logic is in the form of a structured format, like in the JSON file or in the form of executable expressions. We can use any rule engine like DROOLS or ILOG to capture this type of logic, and any change to the logic can be done by directly updating the underlying expressions in the rule engine or executable expressions. This tier logic is not undergoing change so frequently, but any change requested needs to be responded to with the same given timelines as tier one changes. This requires the logic to be maintained in a structure that is also decoupled, and the complex and intricate processing logic is divided into smaller chunks to make it simpler and incorporate the change by changing the underlying logic in the decoupled structure.
Tier 3:
This layer is static and rarely undergoes any change, so the logic in this layer is recommended to be stored in the form of code or less maintainable structure. One important recommendation is to keep the logic in this layer decoupled with the logic in other higher layers. This will be helpful to isolate the scope of impact for any change to processing logic. If higher-level tier logic is undergoing frequent changes, this will reduce the impact of change on lower-level tier logic if the logic in different tiers is decoupled and isolated. This will help to minimize the effort to onboard any change in any of the layers and to onboard the report within defined SLA timelines quickly. The focus will be on higher layers to make the changes and to test the changes thoroughly, as they are most susceptible to change. The lower layers will be just holding another portion of the overall processing logic, which might not be the core processing logic, but any supporting logic needed as part of the end-to-end processing.
We can now take a use case and try to design the overall end-to-end processing application and also bifurcate the design of the application as per the above-recommended design. Let's try to design a predictive analytics processing framework for an e-commerce retailer to help the organization assess the current business pattern and predict future needs as per the current business model. At the same time, the analytics should also suggest changes to the business model to find the best path forward as per the uncertain times. To achieve this objective, we need to work as per the following strategy:
- Define the business objective as well as the requirements for predictive analytics.
- Get the required data to perform the processing.
- Source data cleansing, transformation, and standardization before applying predictive analytics modeling.
- Apply the predictive analytics model as per the business objective to generate curated and succinct output.
- The output will be passed over to analytics applications to generate predictive analytics dashboards and reports.
Post defining the business objective for the predictive analysis, we will start determining the data needed to perform the analysis from all the required disparate source systems of the e-commerce retailer ecosystem.
Data specification needs to be defined, and required data sourcing strategies need to be finalized. The data will be extracted as per the finalized strategy and will be provided to the processing framework.
The processing framework, after receiving the data, will perform the required transformation to the data as well as perform data standardization and cleansing before passing it over to the actual predictive analysis model.
The transformed data is next sent to the predictive analysis model to generate the summarized, curated, and succinct output for predictive analytics reporting and dashboard.
From the above-mentioned steps, the tier 1 logic, which is anticipated to undergo changes frequently, is step 4 above, consisting of a predictive analytics model to process the outcome. This predictive analytics model is foreseen to change based on any internal and external condition influencing the sales and market demands. The model can also undergo change based on dynamic pricing strategies and customer behaviors, which can drive to update of the models.
The model should be highly maintainable as well as extensible to incorporate any new pattern and processing. The model should also be decoupled with the other processes in the overall data processing application.
The tier 2 logic will comprise some portion of Step 3 from the data cleansing steps, data quality checks, as well as any kind of data transformation and standardization needed prior to applying predictive models. The implementation team needs to assess all these steps and decide what can undergo changes frequently based on experience and business input and accordingly decide to design the steps into tier 2 or tier 3 frameworks. The basis of identifying the tier where the logic will go depends on how frequently the underlying logic will change and how maintainable the logic needs to be. Consider the scenario where in step 3, the data cleansing step is a time setup along with data quality checks are also not envisaged to undergo frequent changes, but the data transformation step, as well as data standardization, is something that can change over time. With this possibility, we can design the data cleansing process and data quality checks to be as per tier 1 design. The data transformation step and data standardization will be designed as per tier 2 format.
With the above use case as a requirement, the proposed way to design and structure the overall logic is to be segregated and bucketed as below.
- Tier 1 logic: All the steps requiring data extraction step, Data cleansing step, and data quality step.
- Tier 2 logic: The part of the overall logic requiring data transformation step and data standardization step.
- Tier 3 logic: This tier will have the processing logic constituting any predictive model processing step, which will include the processing logic to be applied to the output of the standardized and transformed data to generate the curated output. This step is assessed to be changing frequently where many factors will drive the changes, and the design should be flexible and maintainable enough such that any change can be applied with minimal effort as well as not impacting the other tier logic. This will also result in a minimal testing effort to be contained only to the part which is changed. The decoupling of logic is also crucial for every tier bucket.
Overall, the integration of end-to-end processing will be done using any scheduling or orchestrator tool, which will call the required step from the respective tier and will pass the control to the next step.
Above is an illustration of one of the pertinent use cases in the industry to fit it in the proposed data processing framework. The approach explains how the different processing steps in the use case need to be assessed and bucketed into different tiers to develop a data processing framework that is configurable as well as metadata-driven. The framework also provides flexibility to have the lesser changing logic in the form of pure code, which can be called by the orchestrator. The orchestration of all the steps will be as per the processing requirement. The framework also provides the capability to scale the processing by leveraging the underlying engine, which will be used to process the logic. Whether we choose Apache Spark, Apache Beam, or any other distributed processing framework to design the solution or use a data warehouse application like Snowflake. The underlying software will provide features to horizontally or vertically scale the processing based on the available infrastructure. The application can be deployed in an in-house cluster of VMs, or it can be deployed on a cloud. The underlying processing engine will be capable of scaling horizontally to any level, depending on the required processing capacity. Also, the design provides flexibility to containerize the whole solution and deploy it to any location. The processing logic for Tier 3 and 2 can be exposed to the implementation team using a simplified interface like a user interface or a microservice-based service mash to provide ease of configuration. While authoring the logic, the necessary checks, like any syntactic validation for the final computable expressions as well as any functional validation of the logic, can be defined and can be applied in an automated manner while authoring the logic. This will help the implementation team focus on defining the correct logic for tier 3 and tier 2 types of changes. The logic once authored and configured by the implementation team, can be seamlessly validated and tested while submitting the logic to the framework. This can be done by defining services for syntactical and functional validation of the logic. These services can be called in an automated manner while the implementation team is authoring the logic and submitting it to the framework.
If we consider the overall design for this use case, below is how the overall flow will look while fitting the use case processing steps into the proposed data processing framework. The below design explains all the high-level steps and how they are going to be designed and authored, along with the tier they are going to be incorporated. The integration of all these processing steps is again connected using the orchestrator, which will own the processing of the steps as per the execution order. This orchestrator-based execution ensures that all the different steps are not tightly coupled, and every step is mutually exclusive and interacts with other steps using the data that is passed from the predecessor step to the successor step. All the steps will perform their designated processing on the data it got from the predecessor step and will pass it over to the next step. This process will be followed for the entire processing pipeline, and by the end of the processing, the data has undergone processing through all the steps and will be passed over to the downstream analytics engine to generate the required analytics outcome for the designated recipients. The diagram depicts at a high level all the steps and how they are authored as per the tier, they belong to and will be integrated into the overall processing pipeline using the orchestrator. Finally, the processing of the logic will be done using the processing engine, which is the bottommost layer in the diagram below. The processing engine can be finalized by the architects based on the processing needs and the topology they recommend using. The diagram below suggests three different options for the processing engine. Any one of the options can be chosen based on the organization's processing requirements, budget, and maintainability aspects for the data processing application.
Processing Engine
In the modern distributed data processing pipeline framework, architects and software designers have multiple options for backend processing engines. I am listing below a few of the most used pipeline processing engines that can be contemplated and assessed against the processing needs while deciding the technical stack to perform the voluminous data processing.
This category lists a few of the most widely used Open-source Data processing frameworks like Apache Spark, Beam, Samza, Storm, or Apache Flink.
If the need is to perform the data processing using an in-house developed custom processor, then the team can develop an in-house data processing framework using open-source technologies like Java, Python, Kotlin, etc. This will provide complete end-to-end control of the processing logic and no dependency on any third-party framework.
The third option talks about scenarios where the need is to have the data processing to be done using any Cloud Data Warehouse frameworks like Snowflake, Google Cloud Big Query, Vertica, Amazon Redshift, and Druid. These frameworks are very performance optimized, and if the need is to process the data really fast with a very quick turnaround time, in those scenarios, the cloud-based data warehouse frameworks are the most apt choice for the framework designers as the data need not have to be moved to the framework memory and can be persisted and processed directly within the cloud data warehouse framework and this will be very performant system for high volume data processing with lot of computation logic for scenarios with complex and multiple layers of processing. Based on the processing power needed, the framework can scale horizontally to any level and can be scaled up and down on a need basis. This can also be set as a dynamic and pay-per-usage model where the processing nodes can be spawned when voluminous processing is needed and later can be scaled down to manage the cost of infrastructure optimally.

Conclusion
The proposed approach provides complete flexibility to the implementors to design the overall data processing framework. The onus will be on the implementation team on how to define the logic and predictive analysis model. If the predictive analysis model is complex and has a lot of processing logic, the team needs to break it into smaller, manageable, and modular parts. The key to efficient design is how to break the full requirement for processing into smaller self-managed pieces, which can then be bucketed into different tiers as per the criteria explained in the article.
Every individual part must be loosely coupled and self-contained so that individually existing pieces of logic as well as all the parts taken together, will constitute the predictive processing model. The model pieces will exist in the form of configurable and metadata-based executable expressions. The expressions need to be maintainable and configurable. The predictive analytics model needs to be defined as part of the tier 1 structure, which is open to any change and can be updated with ease and in a very efficient and seamless manner without impacting the other parts of the overall processing. This way, the solution will be decoupled, and changes coming frequently can be quickly incorporated into the overall framework.
Opinions expressed by DZone contributors are their own.
Comments